Classroom Final Exam: An Instructor-Tested Reasoning Benchmark
作者: Chongyang Gao, Diji Yang, Shuyan Zhou, Xichen Yan, Luchuan Song, Shuo Li, Kezhen Chen
分类: cs.AI, cs.CE, cs.CL, cs.CV
发布日期: 2026-02-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出 Classroom Final Exam (CFE),用于评估大语言模型在 STEM 领域的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 STEM教育 基准测试 多模态学习
📋 核心要点
- 现有大语言模型在复杂 STEM 问题推理方面存在不足,尤其是在多步骤推理中难以保持中间状态的正确性。
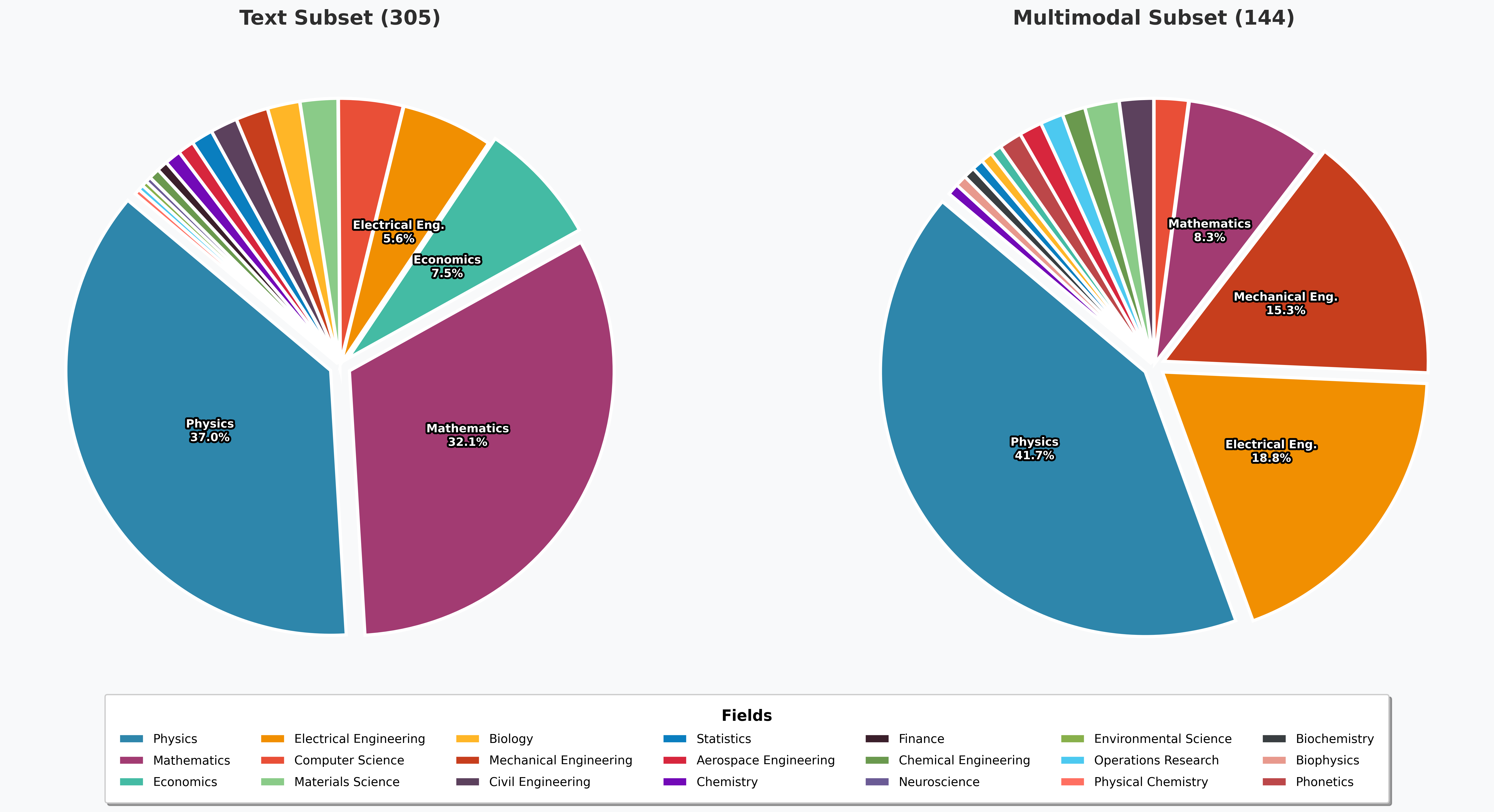
- CFE 通过收集真实大学作业和考试题目,构建了一个多模态推理基准,包含参考答案和详细的推理流程。
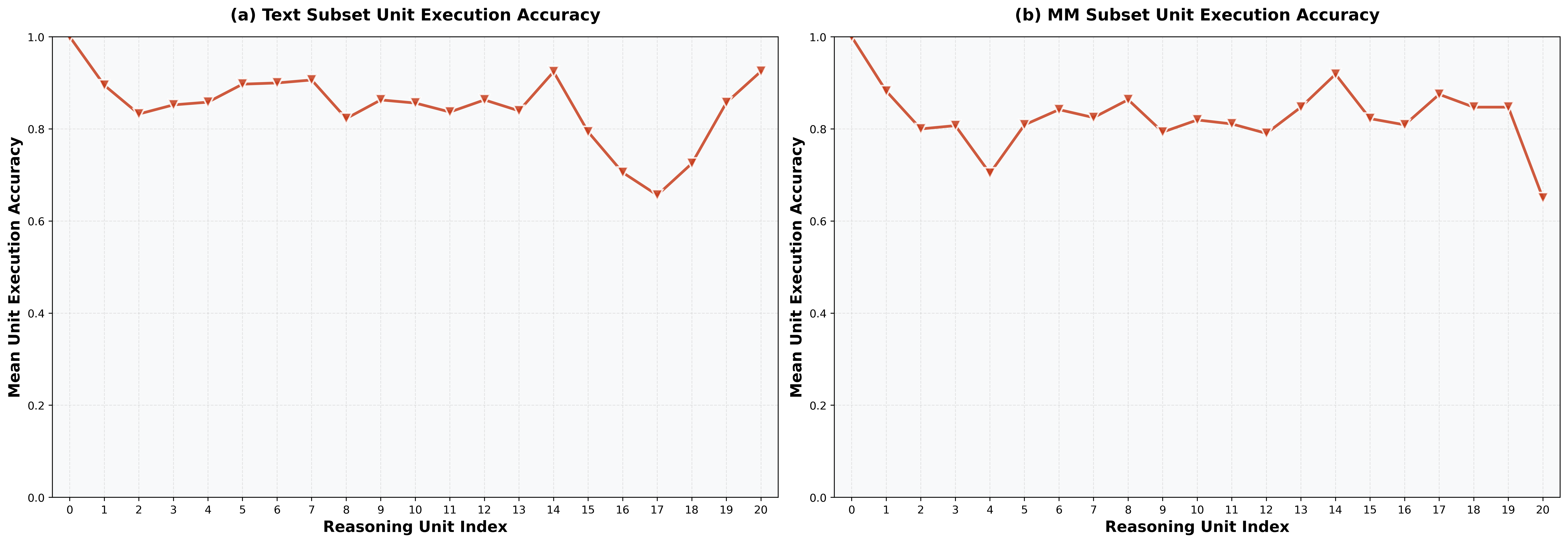
- 实验表明,即使是最先进的模型在 CFE 上表现仍有提升空间,模型生成的解决方案步骤冗余,易累积错误。
📝 摘要(中文)
本文介绍了一个多模态基准测试集 Classroom Final Exam (CFE),旨在评估大型语言模型在超过 20 个 STEM 领域的推理能力。CFE 数据集来源于真实大学的作业和考试题目,并附有课程讲师提供的参考答案。即使对于最先进的模型,CFE 仍然是一个巨大的挑战:最新发布的 Gemini-3.1-pro-preview 模型的总体准确率仅为 59.69%,而第二好的模型 Gemini-3-flash-preview 的准确率为 55.46%,这表明仍有很大的改进空间。除了排行榜结果,我们还通过将参考答案分解为推理流程来进行诊断分析。我们发现,尽管前沿模型通常可以正确回答中间子问题,但它们难以在多步骤解决方案中可靠地推导和维持正确的中间状态。我们进一步观察到,模型生成的解决方案通常比讲师提供的解决方案具有更多的推理步骤,这表明步骤效率欠佳,并且存在更高的错误累积风险。数据和代码可在 https://github.com/Analogy-AI/CFE_Bench 获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在 STEM 领域复杂推理问题上的不足。现有方法在处理需要多步骤推理的问题时,容易出现中间状态错误,导致最终答案错误。此外,现有模型生成的解决方案通常步骤冗余,效率低下,增加了错误累积的风险。
核心思路:论文的核心思路是构建一个高质量、多模态的基准测试集,用于评估和诊断大型语言模型在 STEM 领域的推理能力。通过分析模型在解决真实大学作业和考试题目时的表现,可以更深入地了解模型的推理能力和局限性。
技术框架:CFE 基准测试集包含以下几个关键组成部分:1) 从大学课程中收集的真实作业和考试题目;2) 课程讲师提供的参考答案,包含详细的推理步骤;3) 用于评估模型性能的指标,包括总体准确率和中间步骤的正确率;4) 用于诊断模型推理过程的工具,例如将参考答案分解为推理流程。
关键创新:CFE 的关键创新在于其数据的真实性和高质量。与以往的基准测试集相比,CFE 使用的是真实大学的作业和考试题目,这些题目更具挑战性,更能反映实际应用场景。此外,CFE 还提供了课程讲师提供的参考答案,这些答案不仅包含最终答案,还包含详细的推理步骤,有助于更全面地评估模型的推理能力。
关键设计:CFE 的关键设计包括:1) 题目覆盖了超过 20 个 STEM 领域,确保了基准测试集的广泛适用性;2) 参考答案分解为推理流程,方便分析模型在每个步骤的正确性;3) 评估指标不仅关注最终答案的正确性,还关注中间步骤的正确性,更全面地评估模型的推理能力;4) 提供了数据和代码,方便研究人员使用和扩展 CFE。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的 Gemini-3.1-pro-preview 模型在 CFE 上的总体准确率仅为 59.69%,而第二好的模型 Gemini-3-flash-preview 的准确率为 55.46%。这表明现有模型在 STEM 领域的推理能力仍有很大的提升空间。此外,研究发现模型生成的解决方案通常比讲师提供的解决方案具有更多的推理步骤,表明模型在步骤效率方面存在不足。
🎯 应用场景
该研究成果可应用于提升大语言模型在教育领域的应用,例如智能辅导系统、自动阅卷系统等。通过 CFE 基准测试,可以更好地评估和改进模型的推理能力,使其能够更准确地理解和解决 STEM 领域的复杂问题,从而为学生提供更有效的学习支持。此外,该研究也有助于推动通用人工智能的发展,提高模型在复杂任务中的推理能力。
📄 摘要(原文)
We introduce \CFE{} (\textbf{C}lassroom \textbf{F}inal \textbf{E}xam), a multimodal benchmark for evaluating the reasoning capabilities of large language models across more than 20 STEM domains. \CFE{} is curated from repeatedly used, authentic university homework and exam problems, together with reference solutions provided by course instructors. \CFE{} presents a significant challenge even for frontier models: the newly released Gemini-3.1-pro-preview achieves an overall accuracy of 59.69\%, while the second-best model, Gemini-3-flash-preview, reaches 55.46\%, leaving considerable room for improvement. Beyond leaderboard results, we perform a diagnostic analysis by decomposing reference solutions into reasoning flows. We find that although frontier models can often answer intermediate sub-questions correctly, they struggle to reliably derive and maintain correct intermediate states throughout multi-step solutions. We further observe that model-generated solutions typically have more reasoning steps than those provided by the instructor, indicating suboptimal step efficiency and a higher risk of error accumulation. The data and code are available at https://github.com/Analogy-AI/CFE_Bench.