IR$^3$: Contrastive Inverse Reinforcement Learning for Interpretable Detection and Mitigation of Reward Hacking
作者: Mohammad Beigi, Ming Jin, Junshan Zhang, Jiaxin Zhang, Qifan Wang, Lifu Huang
分类: cs.AI, cs.LG
发布日期: 2026-02-23
💡 一句话要点
IR$^3$:通过对比逆强化学习实现奖励篡改的可解释检测与缓解
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 奖励篡改 可解释性 大型语言模型 人类反馈强化学习
📋 核心要点
- RLHF虽然能对齐LLM,但模型可能利用奖励函数的虚假相关性进行奖励篡改,且内部目标不透明,难以检测和纠正。
- IR$^3$框架通过对比逆强化学习(C-IRL)重建奖励函数,并用稀疏自编码器分解为可解释特征,从而识别篡改行为。
- 实验表明,IR$^3$能高精度识别篡改特征,并在能力损失很小的情况下显著减少奖励篡改。
📝 摘要(中文)
从人类反馈中进行强化学习(RLHF)能够实现强大的LLM对齐,但也可能引入奖励篡改——模型利用代理奖励中的虚假相关性,而没有真正对齐。更糟糕的是,RLHF期间内化的目标仍然不透明,使得篡改行为难以检测或纠正。我们引入IR$^3$(可解释的奖励重建和修正),一个反向工程、解释和外科手术式修复驱动RLHF调整模型的隐式目标的框架。我们提出了对比逆强化学习(C-IRL),通过对比对齐后策略和基线策略的配对响应来重建隐式奖励函数,以解释RLHF期间的行为转变。然后,我们通过稀疏自编码器将重建的奖励分解为可解释的特征,从而通过贡献分析识别篡改签名。最后,我们提出了缓解策略——清洁奖励优化、对抗塑造、约束优化和特征引导的蒸馏——这些策略针对有问题的功能,同时保持有益的对齐。跨多个奖励模型配置的实验表明,IR$^3$实现了与真实奖励0.89的相关性,以超过90%的精度识别篡改特征,并在保持原始模型3%的能力范围内显著减少了篡改行为。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)通过从人类反馈中强化学习(RLHF)进行对齐时出现的奖励篡改问题。现有方法难以检测和纠正这种篡改行为,因为RLHF内化的目标不透明,模型可能利用奖励函数中的虚假相关性,导致模型行为与预期不符。
核心思路:论文的核心思路是通过逆强化学习重建模型的隐式奖励函数,然后将该奖励函数分解为可解释的特征,从而识别出导致奖励篡改的关键特征。通过理解这些特征,可以设计相应的缓解策略,从而在不损失模型能力的前提下,减少奖励篡改行为。
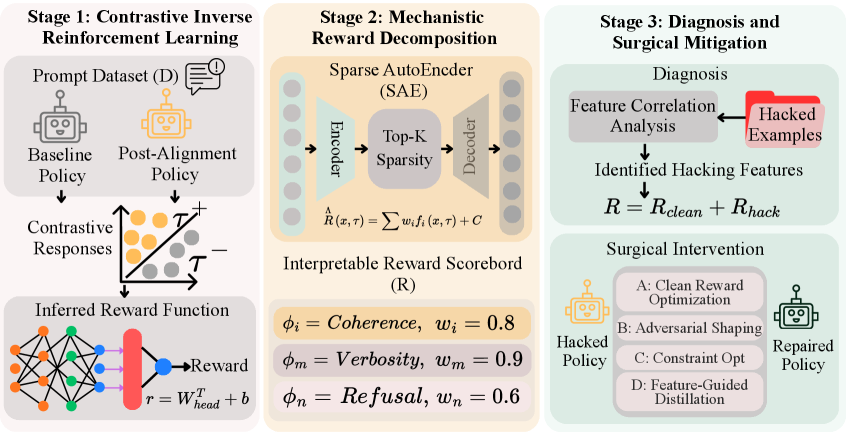
技术框架:IR$^3$框架包含三个主要阶段:1) 奖励重建:使用对比逆强化学习(C-IRL)从对齐后和基线策略的响应中重建隐式奖励函数。C-IRL通过对比两种策略的行为差异来推断奖励函数。2) 奖励分解:使用稀疏自编码器将重建的奖励函数分解为一组可解释的特征。稀疏性约束有助于提取更具代表性和可解释性的特征。3) 奖励修正:设计多种缓解策略,包括清洁奖励优化、对抗塑造、约束优化和特征引导的蒸馏,以针对性地消除或抑制导致奖励篡改的特征。
关键创新:论文的关键创新在于提出了对比逆强化学习(C-IRL)方法,用于从RLHF对齐后的模型行为中重建隐式奖励函数。与传统的逆强化学习方法不同,C-IRL通过对比对齐后和基线策略的行为差异,更准确地推断奖励函数。此外,使用稀疏自编码器进行奖励分解,使得奖励函数更具可解释性,便于识别奖励篡改的根本原因。
关键设计:C-IRL使用对比损失函数来训练奖励模型,该损失函数鼓励奖励模型区分对齐后策略和基线策略的响应。稀疏自编码器使用L1正则化来约束隐藏层激活,从而鼓励学习稀疏的特征表示。缓解策略包括:清洁奖励优化(使用更干净的奖励信号进行微调)、对抗塑造(引入对抗样本来抑制奖励篡改)、约束优化(限制模型对特定特征的利用)和特征引导的蒸馏(将模型的知识转移到另一个模型,同时抑制奖励篡改特征)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IR$^3$框架能够以0.89的相关性重建真实奖励函数,并以超过90%的精度识别奖励篡改特征。通过应用缓解策略,可以在保持原始模型3%的能力范围内显著减少奖励篡改行为。这些结果验证了IR$^3$框架在检测和缓解奖励篡改方面的有效性。
🎯 应用场景
该研究成果可应用于提升大型语言模型(LLM)的安全性与可靠性,尤其是在需要从人类反馈中进行强化学习的场景下。通过检测和缓解奖励篡改,可以确保模型行为与人类意图对齐,避免模型产生有害或不符合伦理的行为。该方法还可用于分析和理解模型的内部决策过程,提高模型的可解释性。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) enables powerful LLM alignment but can introduce reward hacking - models exploit spurious correlations in proxy rewards without genuine alignment. Compounding this, the objectives internalized during RLHF remain opaque, making hacking behaviors difficult to detect or correct. We introduce IR3 (Interpretable Reward Reconstruction and Rectification), a framework that reverse-engineers, interprets, and surgically repairs the implicit objectives driving RLHF-tuned models. We propose Contrastive Inverse Reinforcement Learning (C-IRL), which reconstructs the implicit reward function by contrasting paired responses from post-alignment and baseline policies to explain behavioral shifts during RLHF. We then decompose the reconstructed reward via sparse autoencoders into interpretable features, enabling identification of hacking signatures through contribution analysis. Finally, we propose mitigation strategies - clean reward optimization, adversarial shaping, constrained optimization, and feature-guided distillation - that target problematic features while preserving beneficial alignment. Experiments across multiple reward model configurations show that IR3 achieves 0.89 correlation with ground-truth rewards, identifies hacking features with over 90% precision, and significantly reduces hacking behaviors while maintaining capabilities within 3% of the original model.