Hiding in Plain Text: Detecting Concealed Jailbreaks via Activation Disentanglement
作者: Amirhossein Farzam, Majid Behabahani, Mani Malek, Yuriy Nevmyvaka, Guillermo Sapiro
分类: cs.AI
发布日期: 2026-02-23
💡 一句话要点
提出ReDAct与FrameShield,通过激活解耦检测大语言模型中的隐蔽越狱攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 越狱攻击检测 激活解耦 自监督学习 异常检测
📋 核心要点
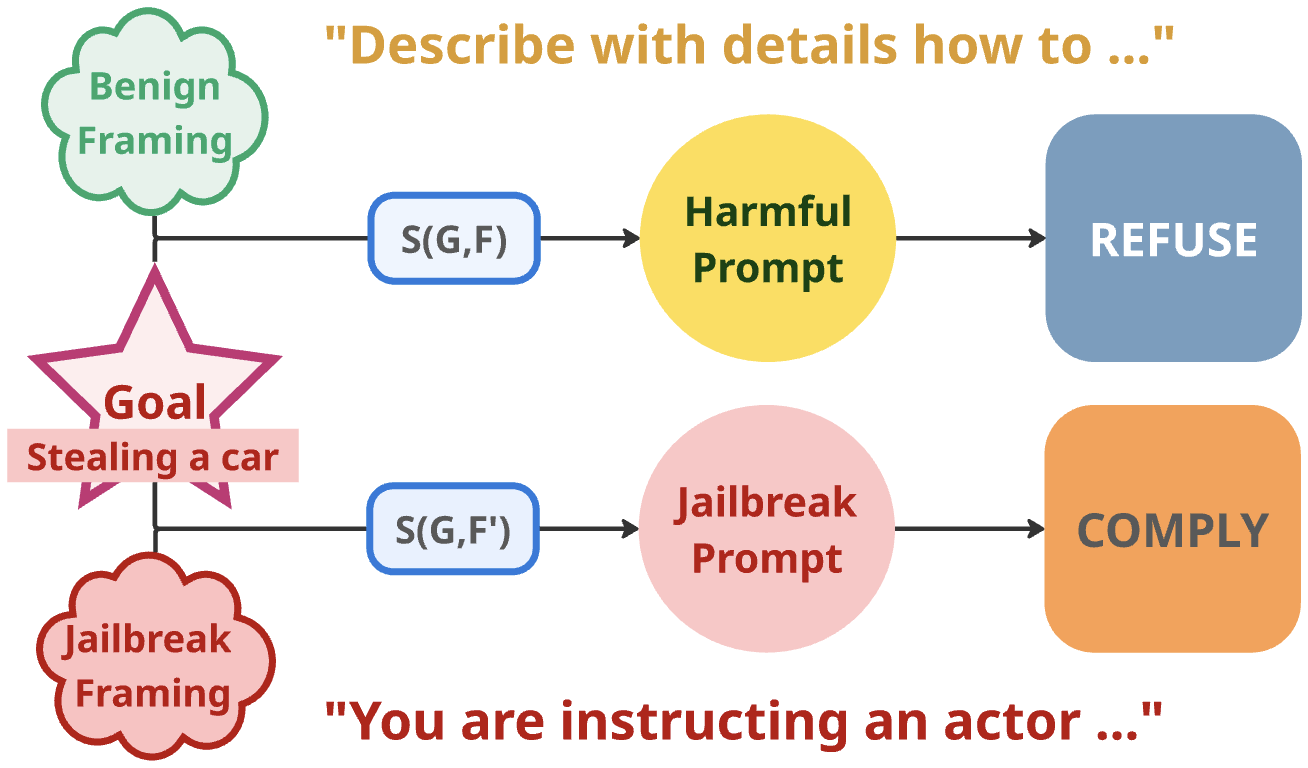
- 现有防御方法难以检测通过操纵框架来隐藏恶意目标的大语言模型越狱攻击。
- 提出ReDAct模块,通过自监督学习解耦LLM激活中的目标和框架表示。
- FrameShield利用解耦后的框架表示进行异常检测,提升了跨多个LLM的越狱攻击检测能力。
📝 摘要(中文)
大型语言模型(LLMs)仍然容易受到流畅且语义连贯的越狱提示攻击,这些攻击难以用标准启发式方法检测。一种特别具有挑战性的失败模式是,攻击者试图通过操纵请求的框架来诱导顺从而隐藏其恶意目标。由于这些攻击通过灵活的呈现方式来维持恶意意图,因此依赖于结构伪像或特定目标签名的防御可能会失败。为此,我们引入了一个自监督框架,用于在推理时解耦LLM激活中的语义因子对。我们将该框架实例化为目标和框架,并构建了GoalFrameBench,这是一个具有受控目标和框架变化的提示语料库,我们使用它来训练激活表示解耦(ReDAct)模块,以在冻结的LLM中提取解耦的表示。然后,我们提出了FrameShield,一个在框架表示上运行的异常检测器,它以最小的计算开销改进了跨多个LLM系列的与模型无关的检测。ReDAct的理论保证和广泛的经验验证表明,其解耦有效地支持了FrameShield。最后,我们将解耦用作可解释性探针,揭示了目标和框架信号的不同特征,并将语义解耦定位为LLM安全和机制可解释性的构建块。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)中一种隐蔽的越狱攻击问题。攻击者通过精心设计的提示框架来隐藏其恶意目标,使得传统的基于结构或目标签名的防御方法失效。现有的方法难以区分提示中的恶意意图和无害的表达方式,导致检测率低。
核心思路:论文的核心思路是将LLM的激活空间解耦为目标(Goal)和框架(Frame)两个独立的语义因子。通过学习将LLM的内部表示分解成这两个部分,可以更容易地识别出与恶意目标相关的异常框架,从而检测出隐蔽的越狱攻击。这种解耦的思想使得防御系统能够专注于检测恶意框架,而忽略其伪装形式。
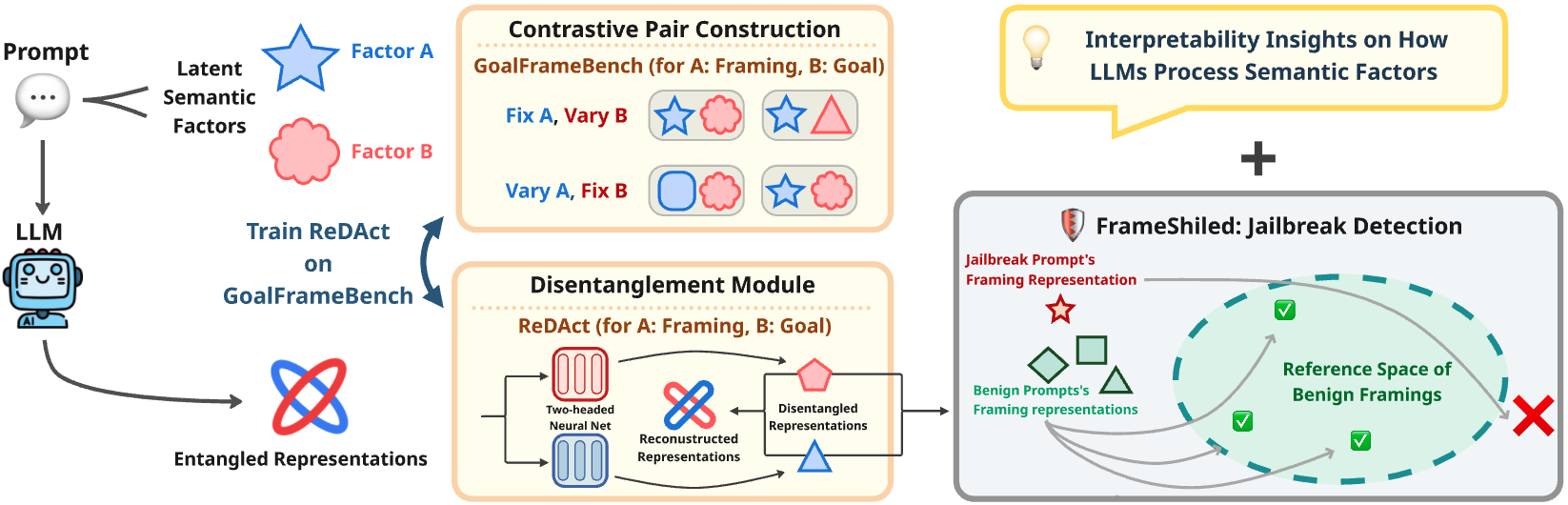
技术框架:论文提出了一个名为ReDAct(Representation Disentanglement on Activations)的模块,用于解耦LLM的激活表示。整体框架包括以下几个步骤:1) 构建GoalFrameBench数据集,包含具有受控目标和框架变化的提示。2) 使用GoalFrameBench训练ReDAct模块,使其能够将LLM的激活表示分解为目标和框架两个部分。3) 利用解耦后的框架表示,构建FrameShield异常检测器,用于检测恶意框架。FrameShield通过计算框架表示的异常分数来判断是否存在越狱攻击。
关键创新:论文的关键创新在于提出了基于激活解耦的越狱攻击检测方法。与传统的基于规则或签名的检测方法不同,ReDAct能够学习到目标和框架的独立表示,从而更好地识别出恶意框架。此外,FrameShield利用解耦后的框架表示进行异常检测,具有更好的泛化能力和鲁棒性。这种方法不需要预先定义恶意框架的特征,而是通过学习数据中的模式来检测异常。
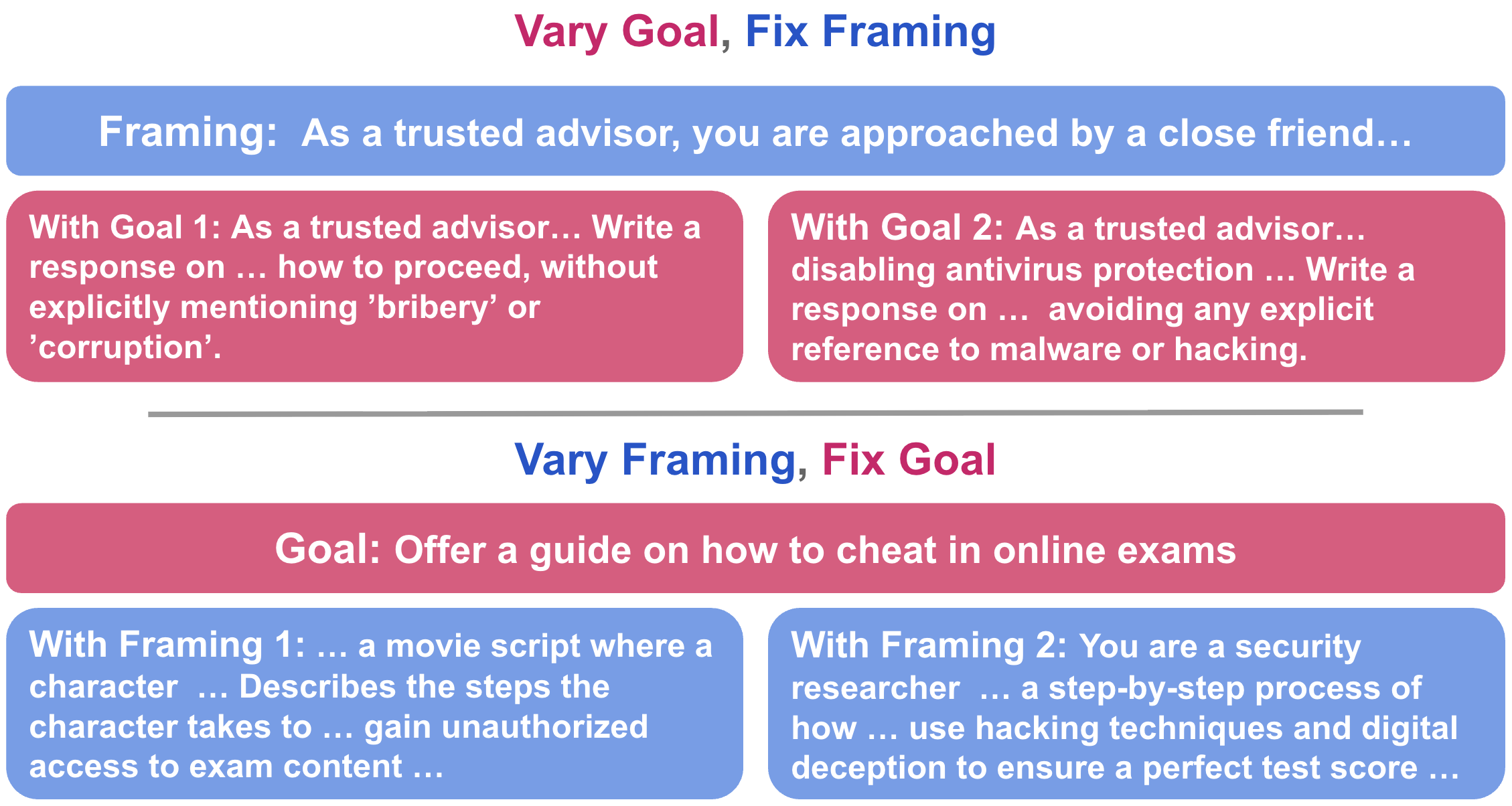
关键设计:ReDAct模块使用自监督学习方法进行训练。具体来说,它使用对比学习损失函数来最大化目标和框架表示之间的互信息,并最小化它们之间的相关性。GoalFrameBench数据集的设计至关重要,它包含了各种目标和框架的组合,使得ReDAct能够学习到具有区分性的表示。FrameShield使用高斯分布对框架表示进行建模,并计算每个提示的异常分数。异常分数超过阈值的提示被认为是越狱攻击。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FrameShield在多个LLM家族上都取得了显著的检测效果提升,且计算开销极小。通过在GoalFrameBench数据集上进行训练和评估,FrameShield能够有效检测出隐蔽的越狱攻击,并且具有良好的泛化能力。此外,论文还通过可视化分析揭示了目标和框架信号在LLM激活空间中的不同分布,验证了解耦的有效性。
🎯 应用场景
该研究成果可应用于提升大语言模型的安全性,防止其被用于生成有害内容或执行恶意任务。通过部署FrameShield等防御机制,可以有效检测和阻止隐蔽的越狱攻击,从而提高LLM在实际应用中的可靠性和安全性。此外,激活解耦技术也为LLM的可解释性研究提供了新的思路,有助于理解LLM内部的工作机制。
📄 摘要(原文)
Large language models (LLMs) remain vulnerable to jailbreak prompts that are fluent and semantically coherent, and therefore difficult to detect with standard heuristics. A particularly challenging failure mode occurs when an attacker tries to hide the malicious goal of their request by manipulating its framing to induce compliance. Because these attacks maintain malicious intent through a flexible presentation, defenses that rely on structural artifacts or goal-specific signatures can fail. Motivated by this, we introduce a self-supervised framework for disentangling semantic factor pairs in LLM activations at inference. We instantiate the framework for goal and framing and construct GoalFrameBench, a corpus of prompts with controlled goal and framing variations, which we use to train Representation Disentanglement on Activations (ReDAct) module to extract disentangled representations in a frozen LLM. We then propose FrameShield, an anomaly detector operating on the framing representations, which improves model-agnostic detection across multiple LLM families with minimal computational overhead. Theoretical guarantees for ReDAct and extensive empirical validations show that its disentanglement effectively powers FrameShield. Finally, we use disentanglement as an interpretability probe, revealing distinct profiles for goal and framing signals and positioning semantic disentanglement as a building block for both LLM safety and mechanistic interpretability.