Time Series, Vision, and Language: Exploring the Limits of Alignment in Contrastive Representation Spaces
作者: Pratham Yashwante, Rose Yu
分类: cs.AI, cs.CV
发布日期: 2026-02-22
备注: 24 Figures, 12 Tables
💡 一句话要点
对比表征空间中时间序列、视觉和语言对齐的极限探索
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列 多模态学习 对比学习 表征对齐 视觉 语言 跨模态检索
📋 核心要点
- 现有研究较少关注时间序列数据与其他模态(视觉、语言)的表征对齐问题,缺乏对多模态融合的深入理解。
- 通过对比学习,在冻结的预训练时间序列、视觉和语言编码器上训练投影头,实现事后对齐,探索不同模态间的表征关系。
- 实验表明,模型越大对齐效果越好,但时间序列与视觉对齐更强,图像可作为时间序列和语言的桥梁,文本描述密度存在阈值效应。
📝 摘要(中文)
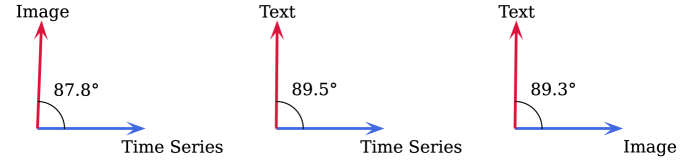
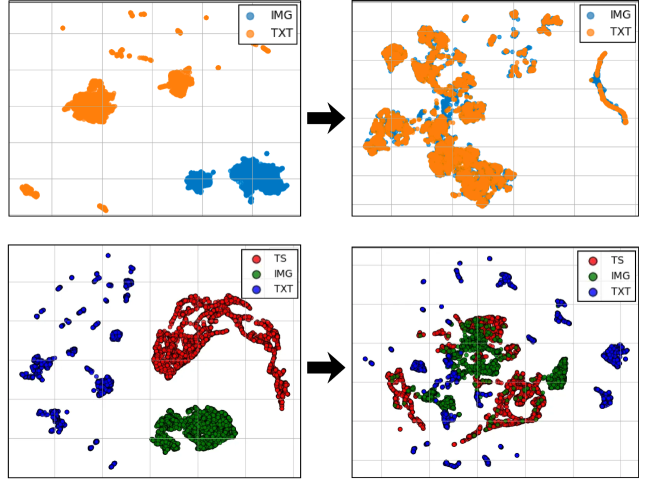
柏拉图表征假设认为,在不同模态上训练的模型学习到的表征会收敛到世界的一个共享潜在结构。然而,这一假设主要在视觉和语言领域进行了研究,时间序列是否参与这种收敛尚不清楚。我们首先在三模态设置中检验了这一点,发现独立预训练的时间序列、视觉和语言编码器在没有显式耦合的情况下表现出近乎正交的几何结构。然后,我们通过使用对比学习在冻结的编码器上训练投影头来应用事后对齐,并分析由此产生的表征,包括几何结构、缩放行为以及对信息密度和输入模态特征的依赖性。我们的研究表明,对比表征空间中的整体对齐随着模型大小的增加而改善,但这种对齐是不对称的:时间序列与视觉表征的对齐比与文本的对齐更强,图像可以作为时间序列和语言之间的有效中介。我们还发现,更丰富的文本描述只能将对齐提高到一定阈值;在更密集的标题上进行训练并不能带来进一步的改进。在视觉表征中也观察到类似的效果。我们的发现为构建涉及视觉和语言之外的非常规数据模态的多模态系统提供了参考。
🔬 方法详解
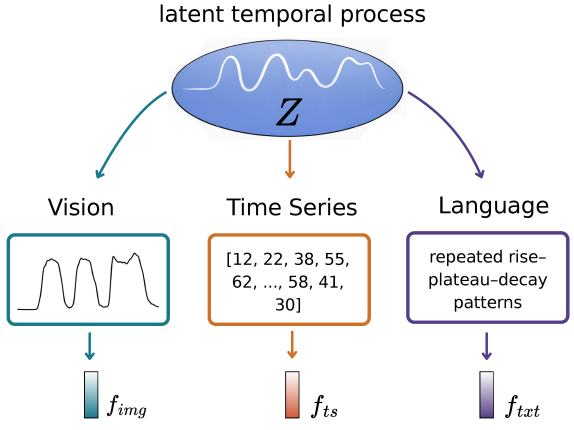
问题定义:论文旨在研究时间序列、视觉和语言三种模态在对比表征空间中的对齐问题。现有方法主要集中在视觉和语言的对齐上,缺乏对时间序列这种非传统数据模态的关注,导致多模态融合效果受限。论文试图探究时间序列是否以及如何参与到多模态表征的收敛过程中,并分析不同模态间的对齐程度和影响因素。
核心思路:论文的核心思路是通过对比学习,将不同模态的数据映射到共享的潜在空间中,从而实现表征对齐。具体来说,论文首先独立预训练时间序列、视觉和语言编码器,然后冻结这些编码器,并训练投影头,将不同模态的表征投影到对比学习的表征空间中。通过分析投影后的表征,可以研究不同模态间的对齐程度和几何关系。
技术框架:整体框架包含三个主要阶段:1) 独立预训练时间序列、视觉和语言编码器;2) 冻结预训练的编码器;3) 使用对比学习训练投影头,将不同模态的表征投影到共享的潜在空间。对比学习的目标是拉近同一语义信息的不同模态表征,推远不同语义信息的表征。通过分析投影后的表征,可以研究不同模态间的对齐程度和几何关系。
关键创新:论文的关键创新在于首次系统性地研究了时间序列、视觉和语言三种模态在对比表征空间中的对齐问题。论文发现,时间序列与视觉表征的对齐比与文本的对齐更强,图像可以作为时间序列和语言之间的有效中介。此外,论文还发现,文本描述密度存在阈值效应,超过阈值后,增加文本描述密度并不能进一步提高对齐效果。
关键设计:论文使用了对比学习框架,具体采用了InfoNCE损失函数。对于时间序列数据,使用了常见的时序模型作为编码器。对于视觉数据,使用了预训练的图像分类模型。对于文本数据,使用了预训练的语言模型。投影头的网络结构使用了简单的MLP。实验中,作者调整了对比学习的温度参数,并分析了不同参数设置下的对齐效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,对比表征空间中的整体对齐随着模型大小的增加而改善。时间序列与视觉表征的对齐比与文本的对齐更强。图像可以作为时间序列和语言之间的有效中介。更丰富的文本描述只能将对齐提高到一定阈值,训练在更密集的标题上并不能带来进一步的改进。
🎯 应用场景
该研究成果可应用于多模态时间序列分析、跨模态数据检索、以及基于时间序列的智能决策等领域。例如,在医疗健康领域,可以将心电图(时间序列)、患者影像(视觉)和病历文本(语言)进行融合分析,从而提高疾病诊断的准确率。在金融领域,可以将股票价格(时间序列)、新闻报道(语言)和市场图像(视觉)进行融合分析,从而预测股票价格的走势。
📄 摘要(原文)
The Platonic Representation Hypothesis posits that learned representations from models trained on different modalities converge to a shared latent structure of the world. However, this hypothesis has largely been examined in vision and language, and it remains unclear whether time series participate in such convergence. We first examine this in a trimodal setting and find that independently pretrained time series, vision, and language encoders exhibit near-orthogonal geometry in the absence of explicit coupling. We then apply post-hoc alignment by training projection heads over frozen encoders using contrastive learning, and analyze the resulting representations with respect to geometry, scaling behavior, and dependence on information density and input modality characteristics. Our investigation reveals that overall alignment in contrastive representation spaces improves with model size, but this alignment is asymmetric: time series align more strongly with visual representations than with text, and images can act as effective intermediaries between time series and language. We further see that richer textual descriptions improve alignment only up to a threshold; training on denser captions does not lead to further improvement. Analogous effects are observed for visual representations. Our findings shed light on considerations for building multimodal systems involving non-conventional data modalities beyond vision and language.