Limited Reasoning Space: The cage of long-horizon reasoning in LLMs
作者: Zhenyu Li, Guanlin Wu, Cheems Wang, Yongqiang Zhao
分类: cs.AI
发布日期: 2026-02-22
💡 一句话要点
提出Halo框架,通过动态规划解决LLM长程推理中的过规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长程推理 大型语言模型 动态规划 模型预测控制 有限推理空间
📋 核心要点
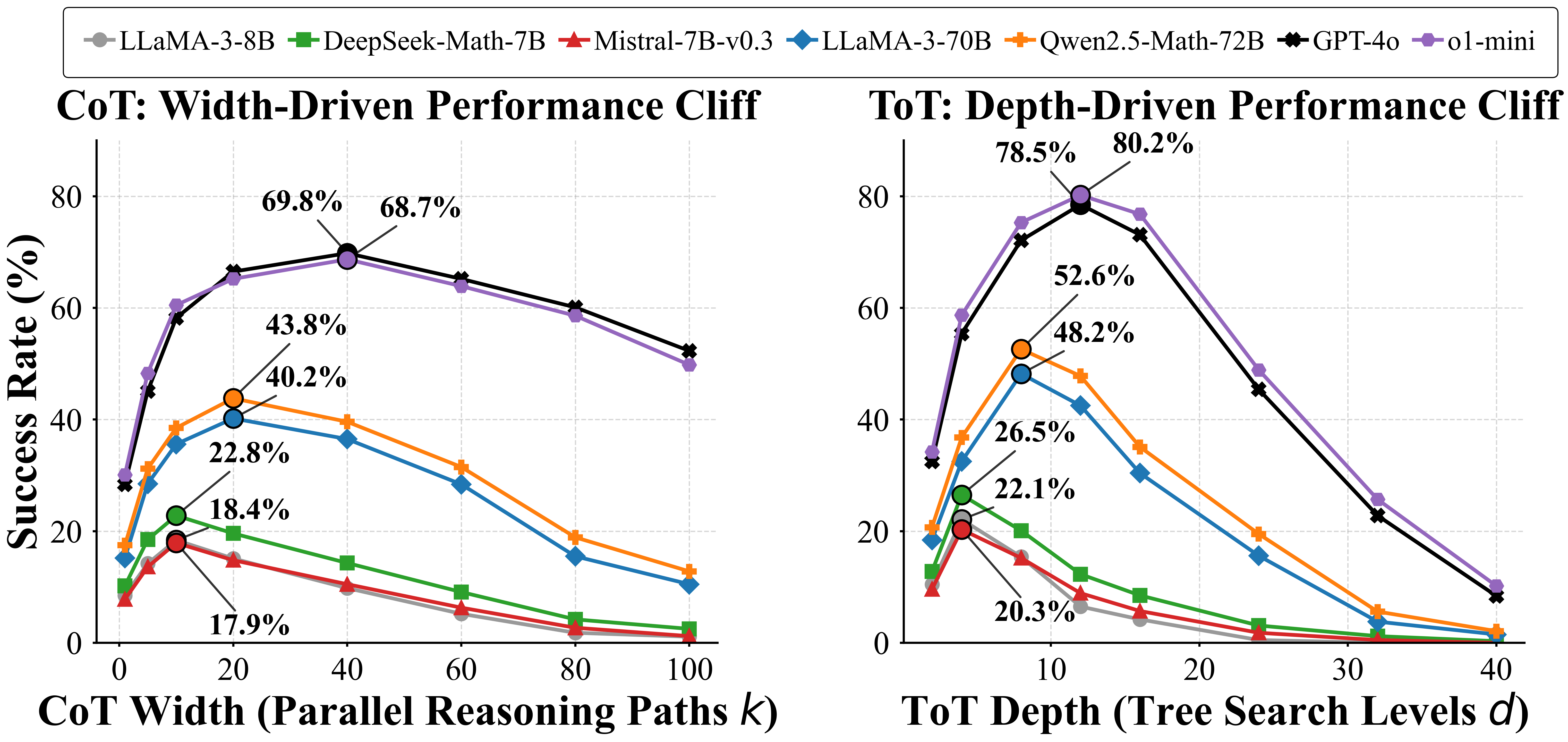
- 现有方法在LLM长程推理中采用静态规划,未能有效利用增加的计算预算,导致性能下降。
- Halo框架采用模型预测控制,通过熵驱动的双控制器动态调节规划,避免过度规划。
- 实验表明,Halo在复杂长程任务上超越了静态基线,验证了动态规划的有效性。
📝 摘要(中文)
大型语言模型(LLM)的思维链(CoT)等测试时计算策略显著提升了其解决复杂逻辑推理任务的能力。然而,实证研究表明,简单地增加计算预算有时会导致测试时性能崩溃,尤其是在采用典型的任务分解策略(如CoT)时。本文假设,计算预算增加导致的推理失败源于静态规划方法,这些方法难以感知LLM推理的内在边界。我们将其称为“有限推理空间”假设,并通过非自治随机动力系统的视角进行理论分析。这一观点表明,计算预算存在一个最佳范围;过度规划可能导致冗余反馈,甚至损害推理能力。为了利用计算扩展的优势并抑制过度规划,本文提出Halo,一个用于LLM规划的模型预测控制框架。Halo专为基于理由的规划的长程任务设计,并构建了一个熵驱动的双控制器,该控制器采用“先测量后规划”的策略来实现可控推理。实验结果表明,Halo通过在推理边界动态调节规划,在复杂的长程任务上优于静态基线。
🔬 方法详解
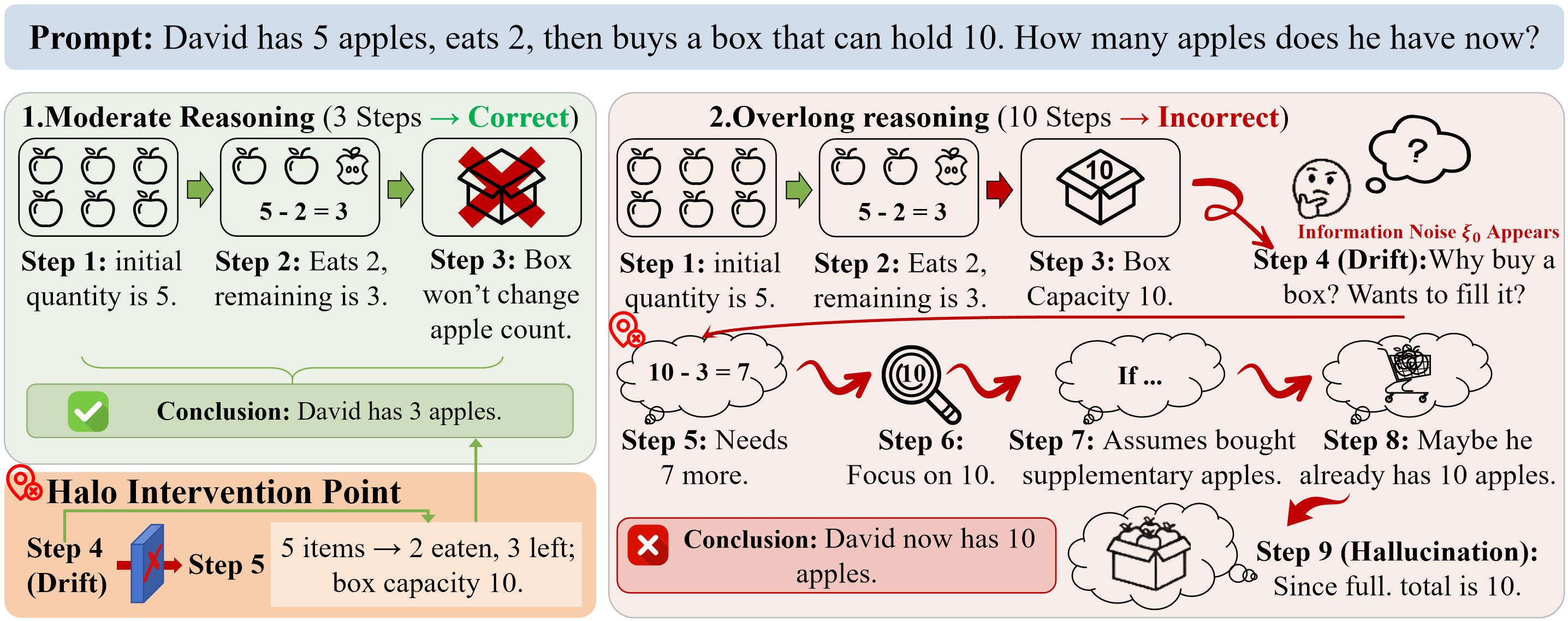
问题定义:论文旨在解决大型语言模型在长程推理任务中,由于静态规划方法导致的“有限推理空间”问题。现有方法,如思维链(CoT),在计算资源增加时,性能反而可能下降,这是因为过度规划导致了冗余反馈和推理能力的损害。
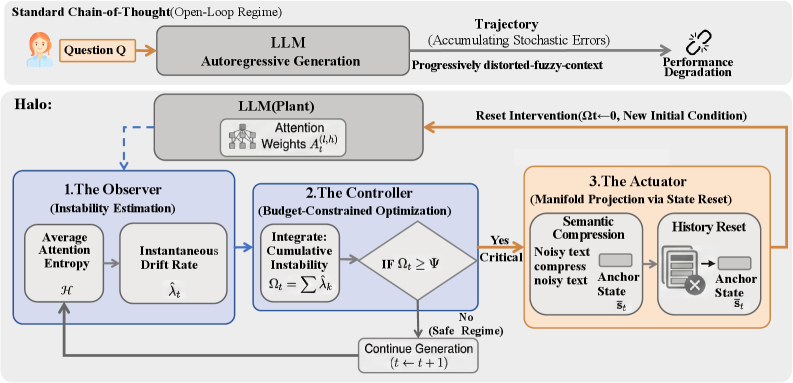
核心思路:论文的核心思路是采用动态规划,通过感知LLM推理的内在边界,避免过度规划。具体而言,通过模型预测控制(MPC)框架,根据当前状态动态调整规划策略,从而更有效地利用计算资源。
技术框架:Halo框架包含一个熵驱动的双控制器,采用“先测量后规划”的策略。框架首先测量当前推理状态的熵,然后根据熵值动态调整规划策略。整体流程包括:1)状态观测:通过熵值估计当前推理状态的不确定性;2)策略规划:基于状态观测,利用模型预测控制生成下一步的推理步骤;3)执行与反馈:执行推理步骤,并根据结果更新状态。
关键创新:Halo的关键创新在于其动态规划策略,它能够根据LLM的推理状态自适应地调整规划过程。与传统的静态规划方法不同,Halo能够感知推理边界,避免过度规划,从而更有效地利用计算资源。
关键设计:Halo的关键设计包括:1)熵估计方法:用于量化当前推理状态的不确定性;2)模型预测控制器:用于生成最优的推理步骤序列;3)奖励函数:用于指导模型预测控制器的学习,鼓励探索和避免过度规划。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Halo框架在复杂的长程推理任务上显著优于静态基线方法。具体的性能提升数据和对比基线在论文中进行了详细展示(未知)。Halo通过动态调节规划,有效地避免了过度规划问题,从而提高了LLM的推理效率和准确性。
🎯 应用场景
该研究成果可应用于需要长程推理和规划的各种领域,例如机器人导航、游戏AI、自动驾驶等。通过动态调节规划策略,可以提高LLM在复杂环境中的决策能力和问题解决能力,使其能够更好地适应不确定性和变化。
📄 摘要(原文)
The test-time compute strategy, such as Chain-of-Thought (CoT), has significantly enhanced the ability of large language models to solve complex tasks like logical reasoning. However, empirical studies indicate that simply increasing the compute budget can sometimes lead to a collapse in test-time performance when employing typical task decomposition strategies such as CoT. This work hypothesizes that reasoning failures with larger compute budgets stem from static planning methods, which hardly perceive the intrinsic boundaries of LLM reasoning. We term it as the Limited Reasoning Space hypothesis and perform theoretical analysis through the lens of a non-autonomous stochastic dynamical system. This insight suggests that there is an optimal range for compute budgets; over-planning can lead to redundant feedback and may even impair reasoning capabilities. To exploit the compute-scaling benefits and suppress over-planning, this work proposes Halo, a model predictive control framework for LLM planning. Halo is designed for long-horizon tasks with reason-based planning and crafts an entropy-driven dual controller, which adopts a Measure-then-Plan strategy to achieve controllable reasoning. Experimental results demonstrate that Halo outperforms static baselines on complex long-horizon tasks by dynamically regulating planning at the reasoning boundary.