Robust Exploration in Directed Controller Synthesis via Reinforcement Learning with Soft Mixture-of-Experts
作者: Toshihide Ubukata, Zhiyao Wang, Enhong Mu, Jialong Li, Kenji Tei
分类: cs.AI, cs.LG
发布日期: 2026-02-22
💡 一句话要点
提出基于软混合专家模型的强化学习方法,提升定向控制器综合中的探索鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 定向控制器综合 混合专家模型 探索策略 鲁棒性
📋 核心要点
- 现有强化学习方法在定向控制器综合中存在各向异性泛化问题,即策略在不同参数区域表现差异大。
- 论文提出软混合专家模型,通过置信度门控机制集成多个强化学习专家,利用其互补的专业化能力。
- 在空中交通基准测试中,该方法显著扩展了可解参数空间,并提升了探索的鲁棒性,优于单一专家。
📝 摘要(中文)
在线定向控制器综合(OTF-DCS)通过增量式探索系统来缓解状态空间爆炸问题,并严重依赖于探索策略来有效地指导搜索。 近年来,强化学习(RL)方法被用于学习此类策略,并在从小训练实例到更大的未见实例中实现了有希望的零样本泛化。 然而,一个根本的限制是各向异性泛化,即RL策略仅在域参数空间的特定区域表现出强大的性能,而在其他地方由于训练随机性和轨迹依赖性偏差而仍然脆弱。 为了解决这个问题,我们提出了一个软混合专家框架,该框架通过先验置信度门控机制组合多个RL专家,并将这些各向异性行为视为互补的专业化。 在空中交通基准上的评估表明,与任何单一专家相比,Soft-MoE 显著扩展了可解参数空间并提高了鲁棒性。
🔬 方法详解
问题定义:在线定向控制器综合(OTF-DCS)旨在通过增量式探索状态空间来解决状态空间爆炸问题。现有的强化学习方法虽然能学习探索策略,但存在各向异性泛化的问题,即在某些参数区域表现良好,而在其他区域表现不佳,导致鲁棒性不足。训练过程中的随机性和轨迹依赖偏差是导致这一问题的主要原因。
核心思路:论文的核心思路是将多个具有不同探索特性的强化学习专家进行集成,利用它们在不同参数区域的互补优势。通过一个置信度门控机制,根据当前状态选择合适的专家进行探索,从而提高整体的探索鲁棒性。这种方法类似于集成学习的思想,旨在通过结合多个弱学习器来构建一个强学习器。
技术框架:整体框架包含多个强化学习专家和一个置信度门控模块。每个专家独立训练,学习在特定参数区域的探索策略。置信度门控模块根据当前状态,计算每个专家的置信度,并使用这些置信度作为权重,对专家的输出进行加权平均,得到最终的探索策略。整个框架可以看作是一个软混合专家模型,其中每个专家负责一部分参数空间,而门控模块负责动态地选择合适的专家。
关键创新:最关键的创新点在于软混合专家模型的引入,以及置信度门控机制的设计。与传统的单一强化学习策略相比,该方法能够更好地处理各向异性泛化问题,提高探索的鲁棒性。与硬选择的混合专家模型相比,软选择能够更好地利用所有专家的信息,避免了单一专家的过度依赖。
关键设计:置信度门控模块使用一个神经网络来实现,输入是当前状态,输出是每个专家的置信度。置信度可以使用softmax函数进行归一化,确保所有置信度之和为1。损失函数包括强化学习的奖励函数和置信度正则化项,用于鼓励专家之间的差异性和避免过度自信。具体的网络结构和参数设置需要根据具体的应用场景进行调整。
🖼️ 关键图片
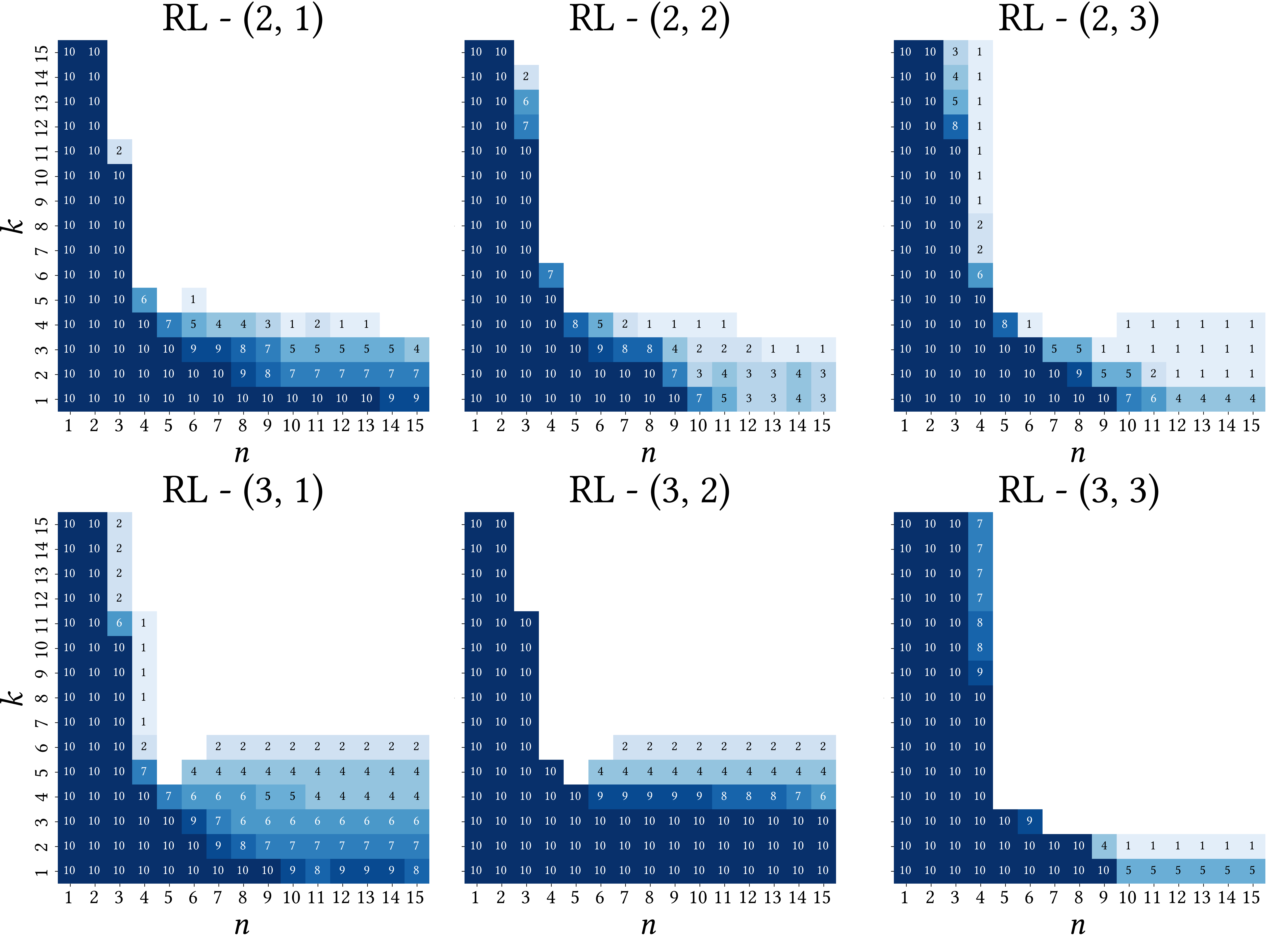
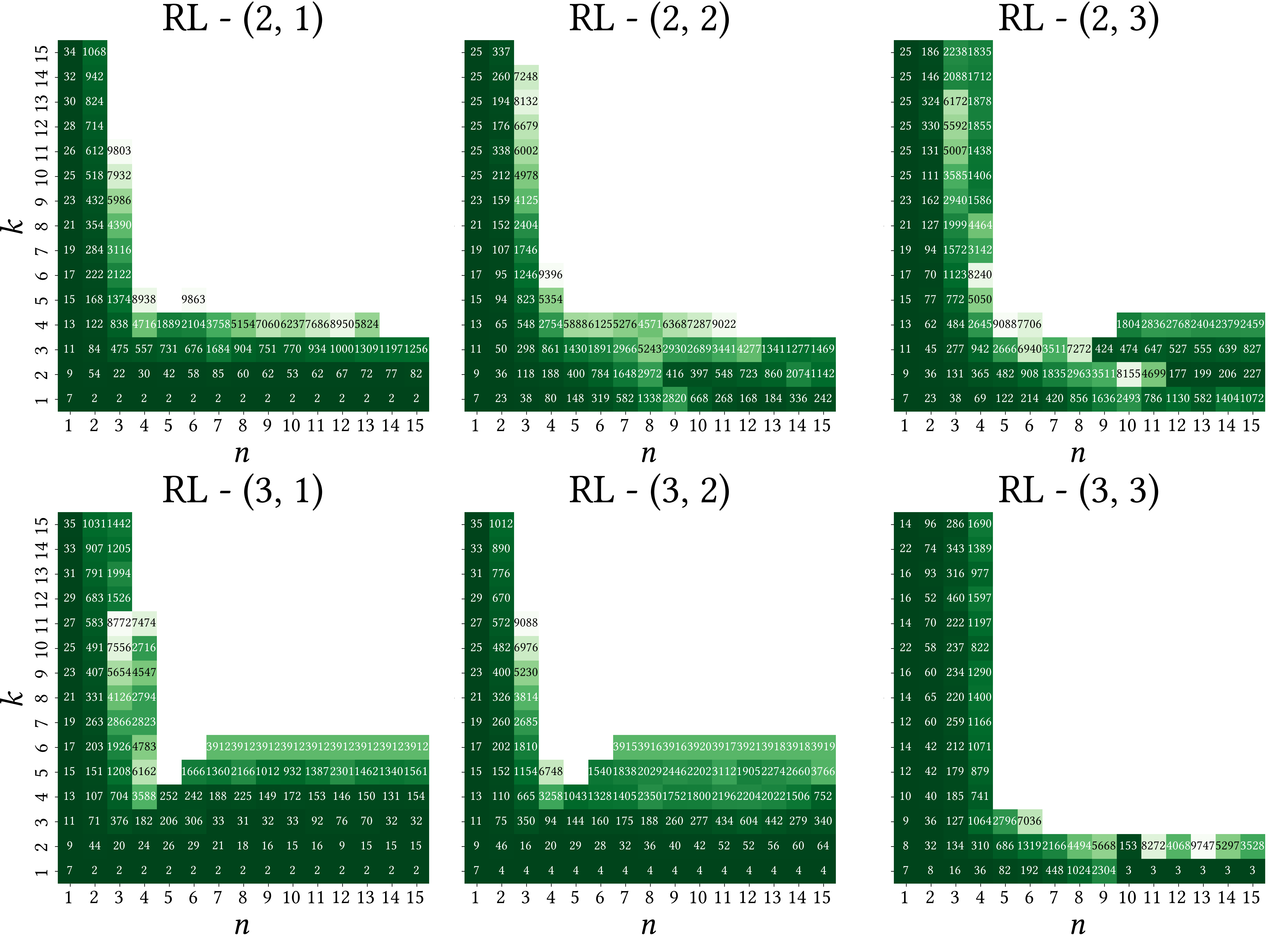
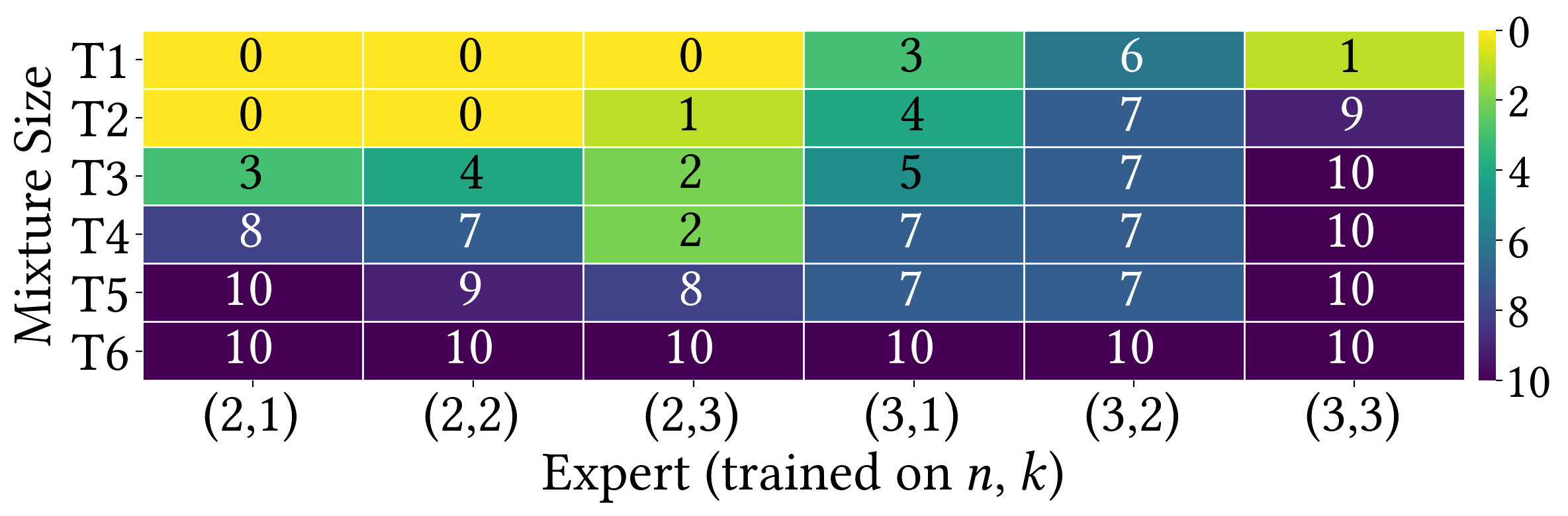
📊 实验亮点
在空中交通管制基准测试中,与单一强化学习专家相比,Soft-MoE方法显著扩展了可解参数空间,提高了鲁棒性。具体而言,Soft-MoE能够解决更多不同复杂度的空中交通场景,并且在面对环境变化时表现出更强的适应能力。实验结果表明,Soft-MoE能够有效地利用多个专家的互补优势,从而提升整体的探索性能。
🎯 应用场景
该研究成果可应用于各种需要自主探索和控制的复杂系统,例如机器人导航、自动驾驶、资源调度和网络安全等领域。通过提高探索的鲁棒性和效率,可以降低系统开发和部署的成本,并提升系统的性能和可靠性。未来,该方法有望推广到更广泛的控制和决策问题中。
📄 摘要(原文)
On-the-fly Directed Controller Synthesis (OTF-DCS) mitigates state-space explosion by incrementally exploring the system and relies critically on an exploration policy to guide search efficiently. Recent reinforcement learning (RL) approaches learn such policies and achieve promising zero-shot generalization from small training instances to larger unseen ones. However, a fundamental limitation is anisotropic generalization, where an RL policy exhibits strong performance only in a specific region of the domain-parameter space while remaining fragile elsewhere due to training stochasticity and trajectory-dependent bias. To address this, we propose a Soft Mixture-of-Experts framework that combines multiple RL experts via a prior-confidence gating mechanism and treats these anisotropic behaviors as complementary specializations. The evaluation on the Air Traffic benchmark shows that Soft-MoE substantially expands the solvable parameter space and improves robustness compared to any single expert.