Reasoning Capabilities of Large Language Models. Lessons Learned from General Game Playing
作者: Maciej Świechowski, Adam Żychowski, Jacek Mańdziuk
分类: cs.AI, cs.CL, cs.LO
发布日期: 2026-02-22
💡 一句话要点
通过通用游戏玩耍评估大语言模型的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 通用游戏玩耍 形式化推理 规则学习
📋 核心要点
- 现有方法难以评估LLM在形式化、规则驱动环境中的推理能力,缺乏系统性的评估框架。
- 本文提出利用通用游戏玩耍(GGP)作为测试平台,通过前向模拟任务评估LLM的推理能力。
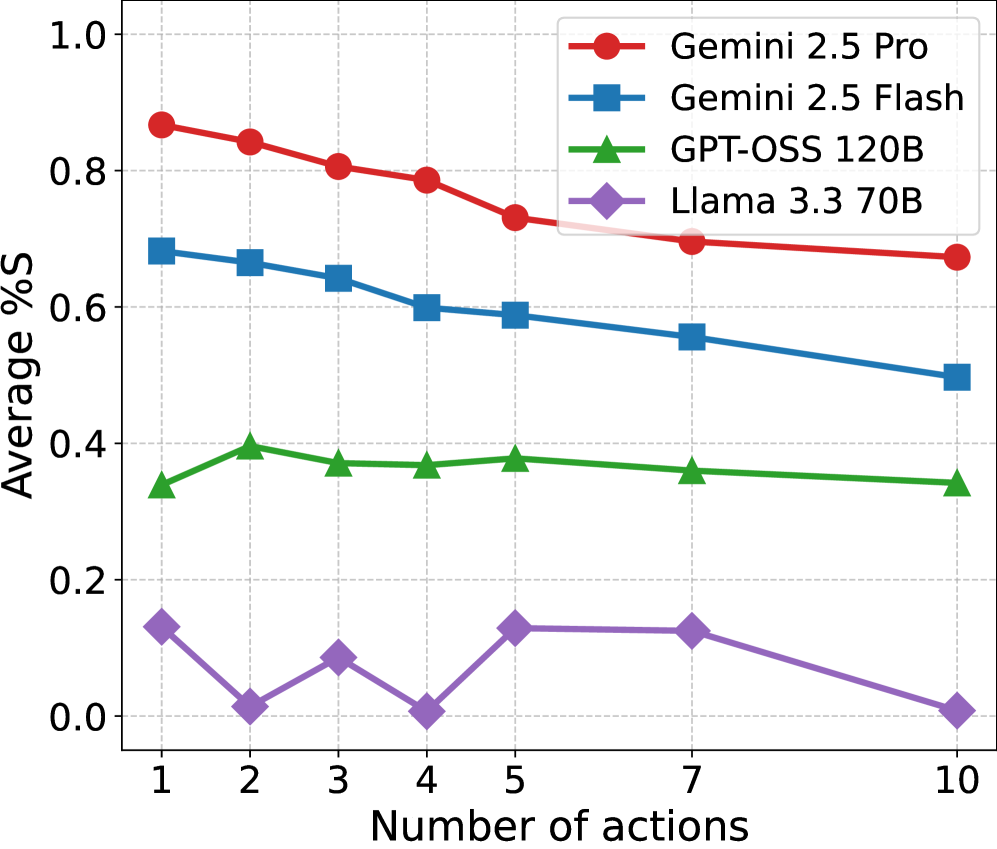
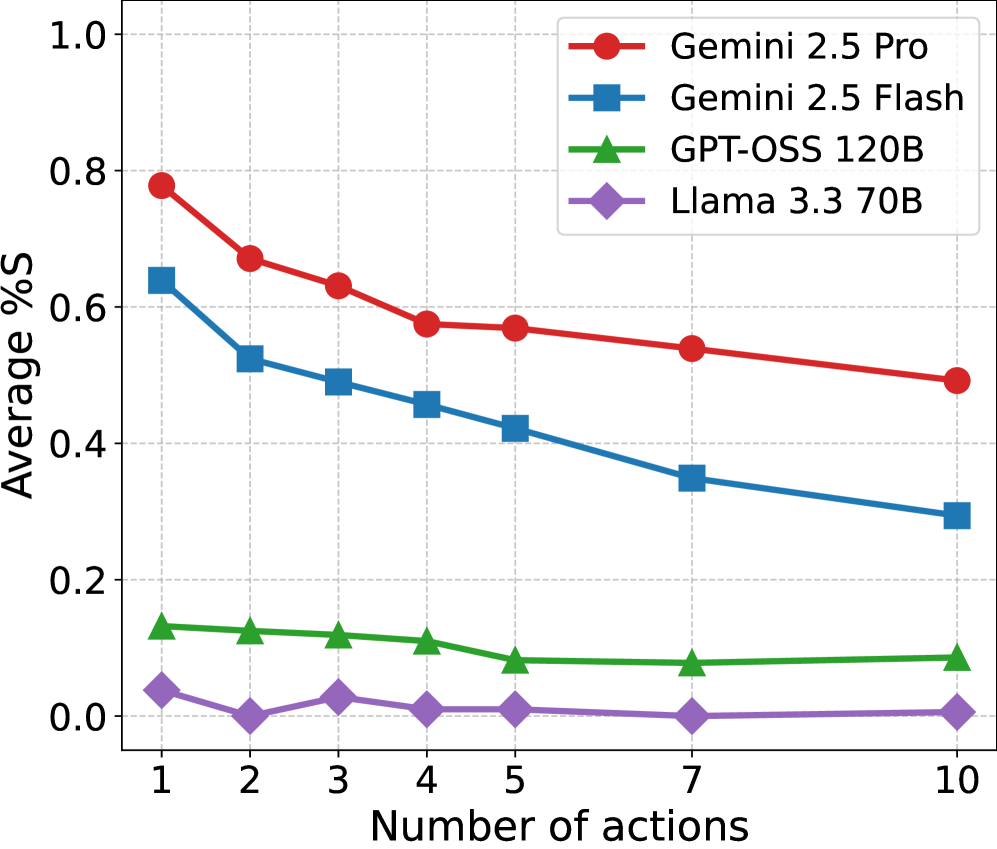
- 实验结果表明,LLM在大多数实验设置中表现良好,但随着游戏步数的增加,性能会下降。
📝 摘要(中文)
本文从一个新颖的角度,即大语言模型在形式化、规则驱动环境中的操作能力,来考察其推理能力。我们评估了四个大语言模型(Gemini 2.5 Pro及其Flash变体,Llama 3.3 70B和GPT-OSS 120B)在一系列前向模拟任务中的表现,包括下一步/多步状态制定和合法动作生成。这些任务涵盖了通过通用游戏玩耍(GGP)游戏实例展示的各种推理问题。除了报告实例级别的性能外,我们还基于40个结构特征对游戏进行表征,并分析这些特征与LLM性能之间的相关性。此外,我们还研究了各种游戏混淆的影响,以评估游戏定义中语言语义的作用,以及LLM在训练期间可能对特定游戏进行预先接触的影响。主要结果表明,所评估的模型中,有三个模型在大多数实验设置中表现良好,但随着评估范围的扩大(即游戏步数增加),性能有所下降。对LLM性能的详细案例分析,为基于逻辑的问题公式化中常见的推理错误提供了新的见解,包括幻觉规则、冗余状态事实或语法错误。总的来说,本文报告了当代模型在形式推理能力方面的明显进展。
🔬 方法详解
问题定义:本文旨在评估大型语言模型(LLMs)在形式化、规则驱动环境下的推理能力。现有方法缺乏对LLMs在逻辑推理和规则理解方面的系统性评估,尤其是在复杂、多步骤推理场景下。现有评估方法难以区分LLMs是真正理解了规则,还是仅仅依赖于记忆或模式匹配。
核心思路:本文的核心思路是将通用游戏玩耍(GGP)作为评估LLMs推理能力的测试平台。GGP提供了一系列形式化定义的游戏,LLMs需要理解游戏规则并进行推理,才能生成合法的动作和预测游戏状态。通过分析LLMs在不同游戏中的表现,可以深入了解其推理能力的优势和局限性。
技术框架:本文的评估框架主要包括以下几个阶段:1)选择GGP游戏实例;2)将游戏规则和当前状态输入LLM;3)要求LLM生成下一步的合法动作或预测下一步的游戏状态;4)评估LLM生成的动作或状态的正确性。本文使用了四个LLM模型(Gemini 2.5 Pro及其Flash变体,Llama 3.3 70B和GPT-OSS 120B)进行评估,并分析了游戏结构特征与LLM性能之间的相关性。
关键创新:本文的创新之处在于:1)将GGP作为评估LLMs推理能力的新颖平台;2)系统性地评估了LLMs在不同游戏中的推理能力,并分析了游戏特征对LLM性能的影响;3)通过游戏混淆实验,评估了LLMs对语言语义的依赖程度。
关键设计:本文的关键设计包括:1)选择具有不同结构特征的GGP游戏实例,以考察LLMs在不同推理场景下的表现;2)设计了多种游戏混淆方法,以评估LLMs对语言语义的敏感性;3)采用多种评估指标,包括动作合法性、状态预测准确率等,以全面评估LLMs的推理能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Gemini 2.5 Pro和Llama 3.3 70B在大多数GGP游戏中表现良好,但在游戏步数增加时性能有所下降。通过案例分析,发现LLM常见的推理错误包括幻觉规则、冗余状态事实和语法错误。游戏混淆实验表明,LLM对语言语义具有一定的依赖性。
🎯 应用场景
该研究成果可应用于开发更智能的AI系统,例如智能游戏代理、自动化规划系统和智能决策支持系统。通过提升LLM的推理能力,可以使其更好地理解和解决现实世界中的复杂问题,例如医疗诊断、金融风险评估和法律咨询等。
📄 摘要(原文)
This paper examines the reasoning capabilities of Large Language Models (LLMs) from a novel perspective, focusing on their ability to operate within formally specified, rule-governed environments. We evaluate four LLMs (Gemini 2.5 Pro and Flash variants, Llama 3.3 70B and GPT-OSS 120B) on a suite of forward-simulation tasks-including next / multistep state formulation, and legal action generation-across a diverse set of reasoning problems illustrated through General Game Playing (GGP) game instances. Beyond reporting instance-level performance, we characterize games based on 40 structural features and analyze correlations between these features and LLM performance. Furthermore, we investigate the effects of various game obfuscations to assess the role of linguistic semantics in game definitions and the impact of potential prior exposure of LLMs to specific games during training. The main results indicate that three of the evaluated models generally perform well across most experimental settings, with performance degradation observed as the evaluation horizon increases (i.e., with a higher number of game steps). Detailed case-based analysis of the LLM performance provides novel insights into common reasoning errors in the considered logic-based problem formulation, including hallucinated rules, redundant state facts, or syntactic errors. Overall, the paper reports clear progress in formal reasoning capabilities of contemporary models.