K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model
作者: Shiyi Cao, Ziming Mao, Joseph E. Gonzalez, Ion Stoica
分类: cs.AI
发布日期: 2026-02-22
💡 一句话要点
K-Search:通过协同演化的内在世界模型生成LLM Kernel,显著提升GPU Kernel优化效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GPU Kernel优化 LLM 进化搜索 世界模型 代码生成
📋 核心要点
- 现有GPU Kernel优化方法依赖启发式进化搜索,将LLM视为随机代码生成器,缺乏规划能力,难以处理复杂Kernel。
- K-Search通过协同演化的世界模型指导LLM进行Kernel搜索,解耦高层规划和底层实现,提升优化效率和鲁棒性。
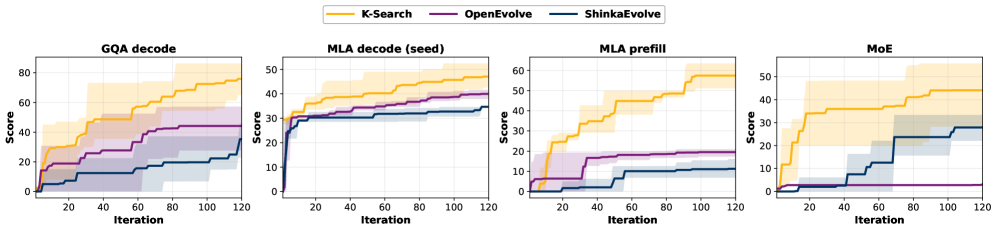
- 实验表明,K-Search在FlashInfer Kernel上优于现有方法,平均提升2.10倍,MoE Kernel上提升高达14.3倍,并在GPUMode TriMul任务中达到SOTA。
📝 摘要(中文)
优化GPU Kernel对于高效的现代机器学习系统至关重要,但由于设计因素的复杂相互作用和硬件的快速发展,这仍然具有挑战性。现有的自动化方法通常仅将大型语言模型(LLM)视为启发式引导的进化循环中的随机代码生成器。这些方法通常难以处理需要协调、多步骤结构转换的复杂Kernel,因为它们缺乏显式的规划能力,并且由于低效或不正确的中间实现而经常丢弃有希望的策略。为了解决这个问题,我们提出了通过协同演化世界模型进行搜索的方法,并在此基础上构建了K-Search。通过用协同演化的世界模型取代静态搜索启发式方法,我们的框架利用LLM的先验领域知识来指导搜索,积极探索优化空间。这种方法将高层算法规划与低层程序实例化显式解耦,使系统能够导航非单调优化路径,同时保持对临时实现缺陷的弹性。我们在FlashInfer中各种复杂的Kernel(包括GQA、MLA和MoE Kernel)上评估了K-Search。结果表明,K-Search显著优于最先进的进化搜索方法,平均提高了2.10倍,在复杂的MoE Kernel上提高了高达14.3倍。在GPUMode TriMul任务中,K-Search在H100上实现了最先进的性能,达到1030us,超过了之前的进化和人工设计的解决方案。
🔬 方法详解
问题定义:论文旨在解决GPU Kernel优化效率低下的问题。现有方法,特别是基于LLM的进化搜索,将LLM简单地作为代码生成器,缺乏对优化过程的规划和理解,导致难以处理复杂的Kernel优化任务,且容易陷入局部最优。
核心思路:论文的核心思路是引入一个协同演化的世界模型,该模型能够学习和理解Kernel优化的过程,并利用LLM的先验知识来指导搜索过程。通过将高层算法规划与低层程序实例化解耦,系统可以更好地探索优化空间,避免因中间实现缺陷而放弃有潜力的优化路径。
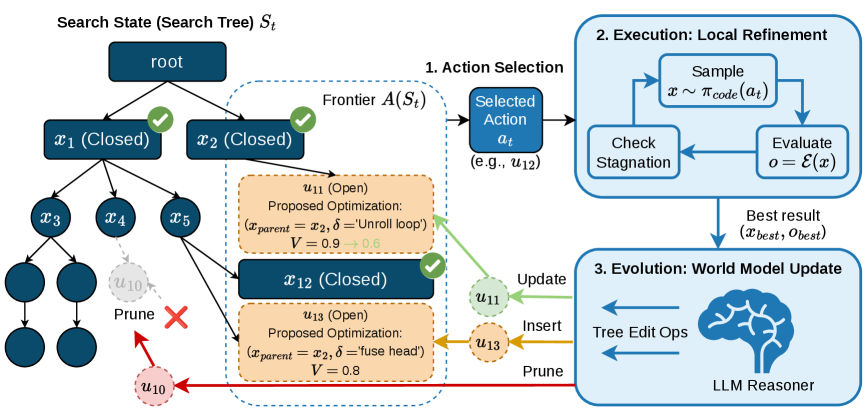
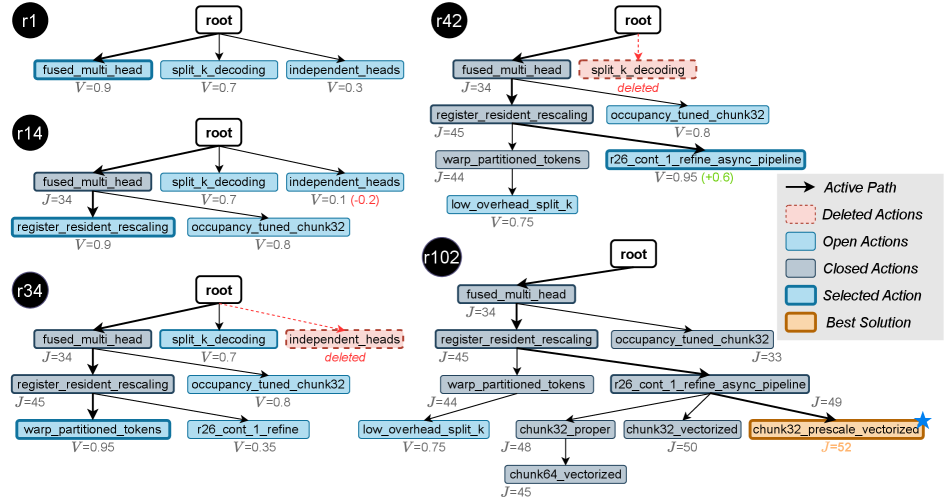
技术框架:K-Search框架包含两个主要部分:一个是LLM驱动的Kernel生成器,另一个是协同演化的世界模型。Kernel生成器负责根据世界模型的指导生成候选Kernel代码。世界模型则负责评估候选Kernel的性能,并根据评估结果更新自身,从而更好地指导后续的Kernel生成。整个过程是一个迭代循环,Kernel生成器和世界模型相互促进,共同进化。
关键创新:K-Search的关键创新在于引入了协同演化的世界模型,该模型能够学习Kernel优化的内在规律,并利用LLM的先验知识来指导搜索过程。这与现有方法将LLM简单地作为代码生成器有本质区别,使得K-Search能够更好地处理复杂的Kernel优化任务。
关键设计:世界模型的设计是K-Search的关键。具体实现细节未知,但可以推测其可能包含以下要素:一个用于表示Kernel优化状态的状态空间,一个用于预测Kernel性能的预测模型,以及一个用于指导Kernel生成的策略网络。损失函数可能包含性能预测误差和策略梯度等项,以鼓励世界模型学习更准确的性能预测和更有效的优化策略。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
K-Search在FlashInfer的GQA、MLA和MoE Kernel上进行了评估,结果表明其显著优于现有的进化搜索方法,平均提升2.10倍,在复杂的MoE Kernel上提升高达14.3倍。在GPUMode TriMul任务中,K-Search在H100上实现了1030us的性能,超越了之前的进化和人工设计的解决方案,达到了SOTA水平。
🎯 应用场景
K-Search具有广泛的应用前景,可用于自动优化各种机器学习框架和应用的GPU Kernel,提升计算效率和性能。尤其是在处理大规模模型和复杂计算任务时,K-Search能够显著降低开发成本和时间,加速AI应用的部署和落地。未来,该技术有望应用于自动驾驶、医疗影像分析、自然语言处理等领域。
📄 摘要(原文)
Optimizing GPU kernels is critical for efficient modern machine learning systems yet remains challenging due to the complex interplay of design factors and rapid hardware evolution. Existing automated approaches typically treat Large Language Models (LLMs) merely as stochastic code generators within heuristic-guided evolutionary loops. These methods often struggle with complex kernels requiring coordinated, multi-step structural transformations, as they lack explicit planning capabilities and frequently discard promising strategies due to inefficient or incorrect intermediate implementations. To address this, we propose Search via Co-Evolving World Model and build K-Search based on this method. By replacing static search heuristics with a co-evolving world model, our framework leverages LLMs' prior domain knowledge to guide the search, actively exploring the optimization space. This approach explicitly decouples high-level algorithmic planning from low-level program instantiation, enabling the system to navigate non-monotonic optimization paths while remaining resilient to temporary implementation defects. We evaluate K-Search on diverse, complex kernels from FlashInfer, including GQA, MLA, and MoE kernels. Our results show that K-Search significantly outperforms state-of-the-art evolutionary search methods, achieving an average 2.10x improvement and up to a 14.3x gain on complex MoE kernels. On the GPUMode TriMul task, K-Search achieves state-of-the-art performance on H100, reaching 1030us and surpassing both prior evolution and human-designed solutions.