How Far Can We Go with Pixels Alone? A Pilot Study on Screen-Only Navigation in Commercial 3D ARPGs
作者: Kaijie Xu, Mustafa Bugti, Clark Verbrugge
分类: cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出基于视觉线索的ARPG游戏自动导航方法,探索纯视觉导航的局限性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉导航 游戏AI 视觉可供性 自动探索 强化学习 3D游戏 ARPG
📋 核心要点
- 现有方法难以量化复杂游戏关卡的可导航性,无法真实捕捉玩家的探索方式。
- 论文提出一种基于视觉可供性的屏幕导航智能体,通过识别兴趣点和有限状态控制器实现导航。
- 实验表明智能体能遍历大部分路段,但视觉模型的局限性阻碍了全面可靠的自动导航。
📝 摘要(中文)
现代3D游戏关卡严重依赖视觉引导,但关卡布局的可导航性难以量化。现有工作要么在简化环境中模拟游戏,要么分析静态截图以获取视觉可供性,但都不能真实地捕捉玩家探索复杂、真实游戏关卡的方式。本文基于现有的开源视觉可供性检测器,实例化了一个纯粹基于视觉可供性的屏幕导航智能体。该智能体接收实时游戏画面,识别显著的兴趣点,并通过一个简单的有限状态控制器在最小的动作空间中探索类《黑暗之魂》的线性关卡,并尝试到达预期的目标区域。初步实验表明,该智能体可以遍历大部分所需路段,并表现出有意义的视觉导航行为,但也突出了底层视觉模型的局限性,阻碍了真正全面和可靠的自动导航。我们认为该系统为复杂游戏中视觉导航提供了一个具体的、共享的基线和评估协议,并呼吁更多关注这一必要任务。我们的结果表明,纯粹基于视觉的感知模型,在离散的单模态输入下,无需显式推理,可以有效地支持理想环境中的导航和环境理解,但不太可能成为通用的解决方案。
🔬 方法详解
问题定义:论文旨在解决3D动作角色扮演游戏(ARPG)中,如何仅通过屏幕画面实现自动导航的问题。现有方法要么过于简化环境,要么仅分析静态图像,无法有效评估真实游戏环境下的可导航性。因此,需要一种能够理解游戏画面并自主导航的智能体,以评估游戏关卡设计的合理性。
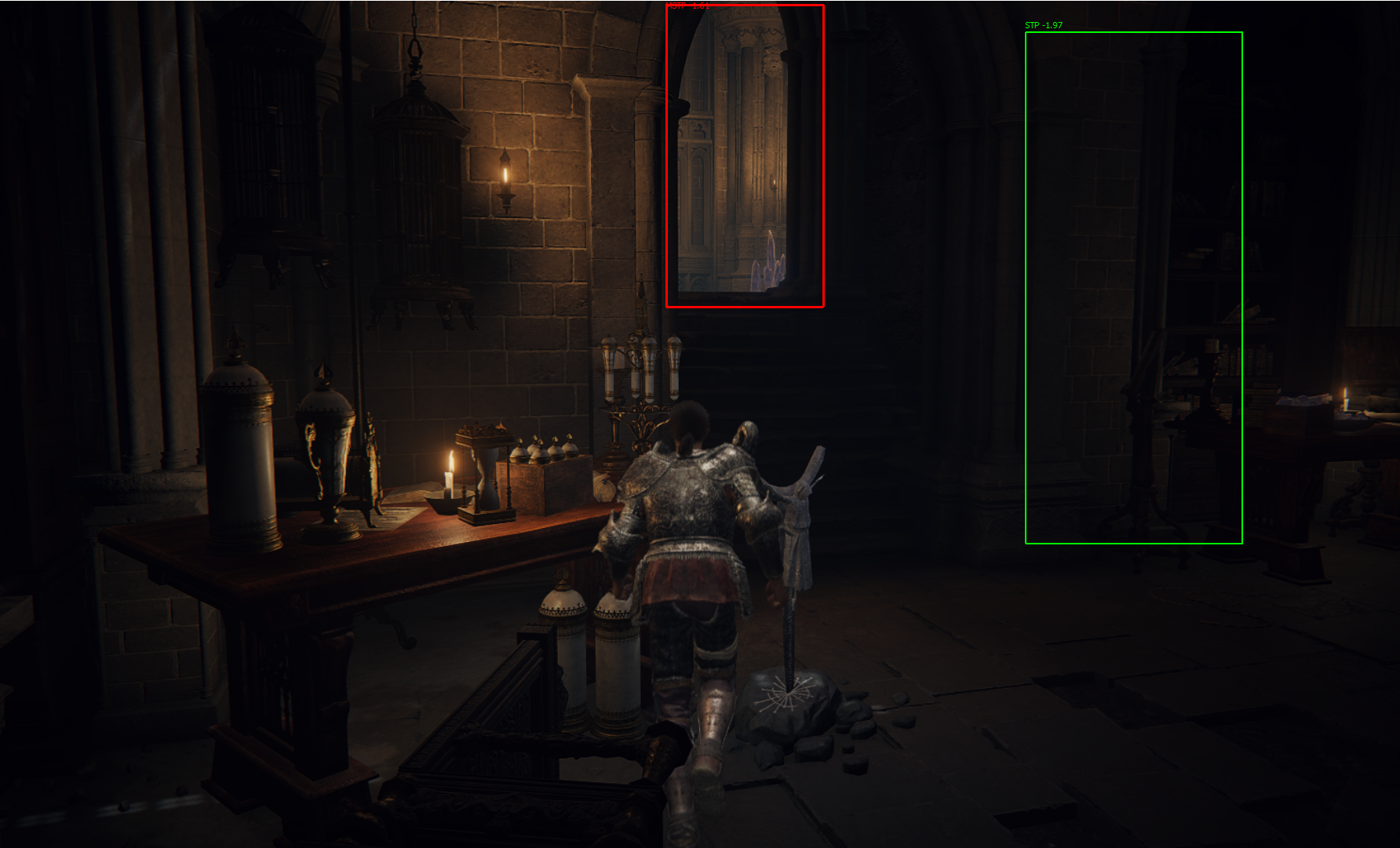
核心思路:论文的核心思路是利用视觉可供性(Visual Affordance)的概念,即从游戏画面中提取出对导航有意义的视觉线索(例如,可行走区域、障碍物等),并基于这些线索驱动智能体进行探索和导航。这种方法模拟了人类玩家仅通过视觉信息进行游戏的方式。
技术框架:整体框架包含以下几个主要模块:1) 游戏画面输入:智能体接收实时的游戏画面帧。2) 视觉可供性检测:利用现有的开源视觉可供性检测器识别画面中的兴趣点。3) 有限状态控制器:基于检测到的兴趣点,驱动智能体执行预定义的动作(例如,前进、转向等)。4) 导航:智能体通过不断地感知环境、执行动作,最终到达目标区域。
关键创新:该论文的关键创新在于构建了一个完全基于视觉的导航智能体,并将其应用于复杂的3D ARPG游戏环境中。与以往的研究相比,该方法更贴近真实的游戏场景,能够更有效地评估游戏关卡的可导航性。此外,该研究还提供了一个具体的、共享的基线和评估协议,为未来的研究提供了参考。
关键设计:智能体使用简单的有限状态控制器,动作空间被限制在最小集合,例如前进、左转、右转。视觉可供性检测器采用现有的开源模型,没有进行特别的定制。实验中,选择《黑暗之魂》风格的线性关卡作为测试环境。目标区域的定义是预先设定的,智能体的目标是到达这些区域。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该智能体能够在《黑暗之魂》风格的线性关卡中成功遍历大部分所需路段,并表现出有意义的视觉导航行为。虽然视觉模型的局限性导致无法实现完全可靠的自动导航,但该研究验证了纯视觉导航在特定游戏环境下的可行性,并为未来的研究提供了宝贵的经验。
🎯 应用场景
该研究成果可应用于游戏AI的开发,例如自动测试游戏关卡的可玩性、辅助游戏设计者优化关卡布局、以及开发更智能的NPC。此外,该方法也可以扩展到其他需要视觉导航的领域,例如机器人导航、自动驾驶等。
📄 摘要(原文)
Modern 3D game levels rely heavily on visual guidance, yet the navigability of level layouts remains difficult to quantify. Prior work either simulates play in simplified environments or analyzes static screenshots for visual affordances, but neither setting faithfully captures how players explore complex, real-world game levels. In this paper, we build on an existing open-source visual affordance detector and instantiate a screen-only exploration and navigation agent that operates purely from visual affordances. Our agent consumes live game frames, identifies salient interest points, and drives a simple finite-state controller over a minimal action space to explore Dark Souls-style linear levels and attempt to reach expected goal regions. Pilot experiments show that the agent can traverse most required segments and exhibits meaningful visual navigation behavior, but also highlight that limitations of the underlying visual model prevent truly comprehensive and reliable auto-navigation. We argue that this system provides a concrete, shared baseline and evaluation protocol for visual navigation in complex games, and we call for more attention to this necessary task. Our results suggest that purely vision-based sense-making models, with discrete single-modality inputs and without explicit reasoning, can effectively support navigation and environment understanding in idealized settings, but are unlikely to be a general solution on their own.