Give Users the Wheel: Towards Promptable Recommendation Paradigm
作者: Fuyuan Lyu, Chenglin Luo, Qiyuan Zhang, Yupeng Hou, Haolun Wu, Xing Tang, Xue Liu, Jin L. C. Guo, Xiuqiang He
分类: cs.IR, cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出解耦可提示序列推荐(DPR)框架,利用自然语言提示动态引导推荐过程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推荐 可提示推荐 自然语言提示 用户意图 解耦框架
📋 核心要点
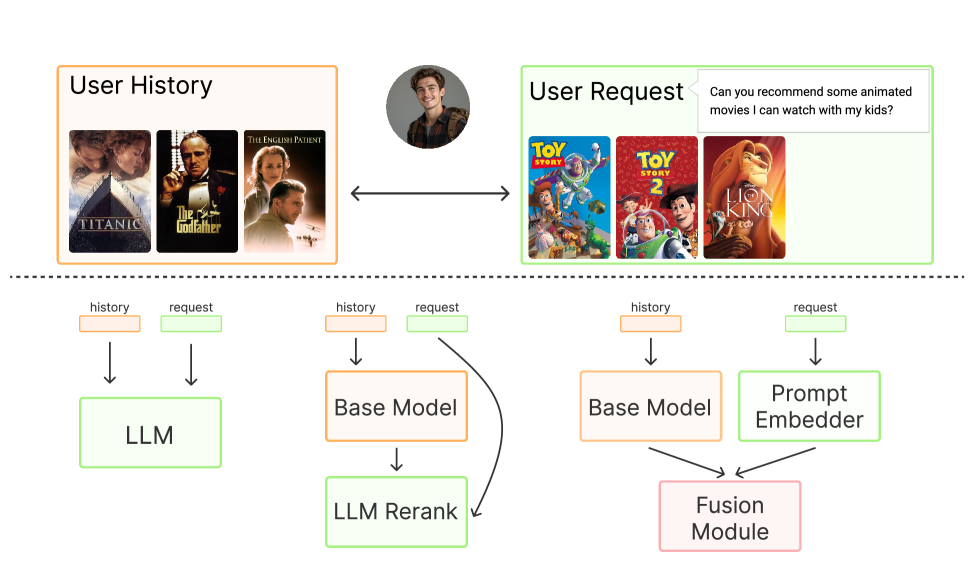
- 现有序列推荐模型难以根据用户自然语言提示的意图进行动态调整,忽略了显式用户意图。
- DPR框架通过解耦协同信号和语义信号,并利用融合模块和MoE架构,实现了可提示推荐。
- 实验结果表明,DPR在提示引导任务中显著优于现有方法,同时保持了标准序列推荐的性能。
📝 摘要(中文)
传统的序列推荐模型在挖掘隐式行为模式方面取得了显著成功。然而,这些架构在结构上对显式用户意图视而不见:当用户的直接目标(例如,通过自然语言提示表达)偏离其历史习惯时,它们难以适应。虽然大型语言模型(LLM)提供了理解这种意图的语义推理能力,但现有的集成范式面临两难:LLM-as-a-recommender范式牺牲了基于ID检索的效率和协同精度,而重排序方法本质上受到底层模型召回能力的限制。本文提出了解耦可提示序列推荐(DPR),这是一个模型无关的框架,使传统的序列骨干网络能够原生支持可提示推荐,即使用自然语言动态引导检索过程,而不会放弃协同信号。DPR直接在检索空间内调节潜在用户表示。为此,我们引入了一个融合模块来对齐协同和语义信号,一个混合专家(MoE)架构来解耦来自正向和负向引导的冲突梯度,以及一个三阶段训练策略,逐步将提示的语义空间与协同空间对齐。在真实世界数据集上的大量实验表明,DPR在提示引导的任务中显著优于最先进的基线,同时在标准序列推荐场景中保持了具有竞争力的性能。
🔬 方法详解
问题定义:现有序列推荐模型主要依赖于用户的历史行为模式进行推荐,缺乏对用户显式意图的理解和利用。当用户通过自然语言提示表达了与历史行为不同的偏好时,现有模型难以有效适应,导致推荐效果下降。此外,直接使用LLM进行推荐效率较低,而重排序方法又受限于底层模型的召回能力。
核心思路:DPR的核心思路是将用户的协同信号(历史行为)和语义信号(自然语言提示)解耦,然后通过融合模块将二者对齐,从而实现可提示推荐。通过这种方式,模型既能利用用户的历史行为模式,又能根据用户的实时意图进行动态调整。
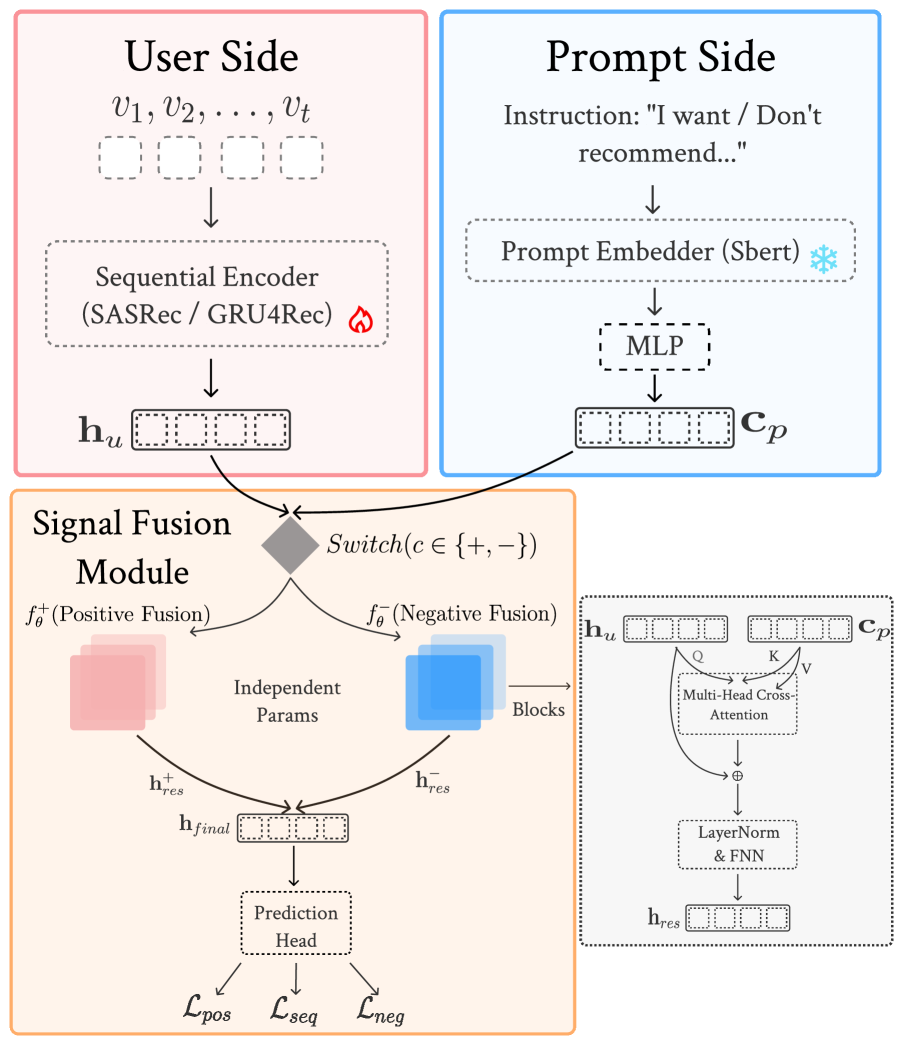
技术框架:DPR框架主要包含三个核心模块:1) 融合模块:用于对齐协同信号和语义信号,将自然语言提示融入到用户表示中。2) 混合专家(MoE)架构:用于解耦来自正向和负向引导的冲突梯度,提高模型的训练效率和效果。3) 三阶段训练策略:逐步将提示的语义空间与协同空间对齐,确保模型能够有效地利用自然语言提示。整体流程是,首先利用序列推荐模型提取用户历史行为的协同信号,然后利用LLM提取自然语言提示的语义信号,接着通过融合模块将二者对齐,最后利用MoE架构和三阶段训练策略进行模型训练。
关键创新:DPR的关键创新在于其解耦的设计思想,以及融合模块和MoE架构的应用。与现有方法相比,DPR能够更有效地利用自然语言提示,实现可提示推荐,同时避免了直接使用LLM带来的效率问题和重排序方法带来的召回限制。
关键设计:融合模块的具体实现方式未知,但推测可能使用了注意力机制或其他融合方法。MoE架构的具体专家数量和网络结构未知。三阶段训练策略的具体步骤和损失函数设计未知。这些细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DPR在提示引导的任务中显著优于最先进的基线模型,证明了其有效性。具体的性能提升幅度未知,需要在论文中查找。同时,DPR在标准序列推荐场景中保持了具有竞争力的性能,表明其在引入可提示能力的同时,没有牺牲原有的推荐效果。
🎯 应用场景
DPR框架可应用于各种需要根据用户实时意图进行推荐的场景,例如电商平台的商品推荐、视频网站的视频推荐、新闻App的新闻推荐等。通过利用用户的自然语言提示,DPR能够更精准地理解用户的需求,从而提供更个性化、更符合用户期望的推荐结果。未来,DPR还可以与其他技术相结合,例如知识图谱、多模态信息等,进一步提升推荐效果。
📄 摘要(原文)
Conventional sequential recommendation models have achieved remarkable success in mining implicit behavioral patterns. However, these architectures remain structurally blind to explicit user intent: they struggle to adapt when a user's immediate goal (e.g., expressed via a natural language prompt) deviates from their historical habits. While Large Language Models (LLMs) offer the semantic reasoning to interpret such intent, existing integration paradigms force a dilemma: LLM-as-a-recommender paradigm sacrifices the efficiency and collaborative precision of ID-based retrieval, while Reranking methods are inherently bottlenecked by the recall capabilities of the underlying model. In this paper, we propose Decoupled Promptable Sequential Recommendation (DPR), a model-agnostic framework that empowers conventional sequential backbones to natively support Promptable Recommendation, the ability to dynamically steer the retrieval process using natural language without abandoning collaborative signals. DPR modulates the latent user representation directly within the retrieval space. To achieve this, we introduce a Fusion module to align the collaborative and semantic signals, a Mixture-of-Experts (MoE) architecture that disentangles the conflicting gradients from positive and negative steering, and a three-stage training strategy that progressively aligns the semantic space of prompts with the collaborative space. Extensive experiments on real-world datasets demonstrate that DPR significantly outperforms state-of-the-art baselines in prompt-guided tasks while maintaining competitive performance in standard sequential recommendation scenarios.