Orchestrating LLM Agents for Scientific Research: A Pilot Study of Multiple Choice Question (MCQ) Generation and Evaluation
作者: Yuan An
分类: cs.CY, cs.AI, cs.HC
发布日期: 2026-02-21
💡 一句话要点
探索LLM智能体在科学研究中的应用:以多项选择题生成与评估为例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 智能体 科学研究 多项选择题生成 自动化研究流程
📋 核心要点
- 现有科学研究方法在数据处理、内容生成和评估方面面临效率瓶颈,难以应对日益增长的信息量。
- 本研究提出一种由人类研究员协调多个LLM智能体的AI编排研究工作流程,实现数据提取、语料库构建、内容生成和评估的自动化。
- 实验表明,LLM生成的MCQ质量较高,但与专家审核的基线问题相比,在技能深度、认知参与等方面仍存在差距,揭示了AI研究运营的新需求。
📝 摘要(中文)
大型语言模型(LLM)的进步正在迅速改变科学研究工作,但关于这些系统如何重塑研究活动的经验证据仍然有限。本研究报告了一项混合方法初步评估,评估了一个由AI编排的研究工作流程,其中人类研究员协调多个基于LLM的智能体来执行数据提取、语料库构建、工件生成和工件评估。以多项选择题(MCQ)的生成和评估作为试验平台,我们收集了1071道SAT数学MCQ,并使用LLM智能体从PDF中提取问题,检索开放教科书并将其转换为结构化表示,将每个MCQ与相关的教科书内容对齐,在指定的难度和认知水平下生成新的MCQ,并使用24条标准的质量框架评估原始和生成的MCQ。总体而言,MCQ的平均质量很高。然而,标准层面的分析和等效性测试表明,生成的MCQ与专家审核的基线问题并不完全可比。在所有24条标准上完全等效的情况从未实现。持续存在的差距集中在技能深度、认知参与、难度校准和元数据对齐方面,而诸如语法流畅性、选项清晰度和无重复等表面质量始终表现良好。除了MCQ的结果之外,该研究还记录了劳动力的转变。研究人员的工作从“编写题目”转变为“规范、编排、验证”和“治理”。形式化约束、设计评估标准、构建验证循环、从工具故障中恢复以及审计来源构成了主要活动。我们讨论了对未来科学研究的影响,包括AI赋能的研究流程所需的新兴“AI研究运营”技能。
🔬 方法详解
问题定义:论文旨在探索如何利用大型语言模型(LLM)智能体来辅助科学研究,并评估其在多项选择题(MCQ)生成和评估任务中的表现。现有方法依赖人工编写和评估MCQ,效率低下且难以保证质量。
核心思路:论文的核心思路是构建一个由人类研究员协调的、基于LLM智能体的自动化研究工作流程。该流程将复杂的MCQ生成和评估任务分解为多个子任务,并分配给不同的LLM智能体执行,从而提高效率和降低人工成本。
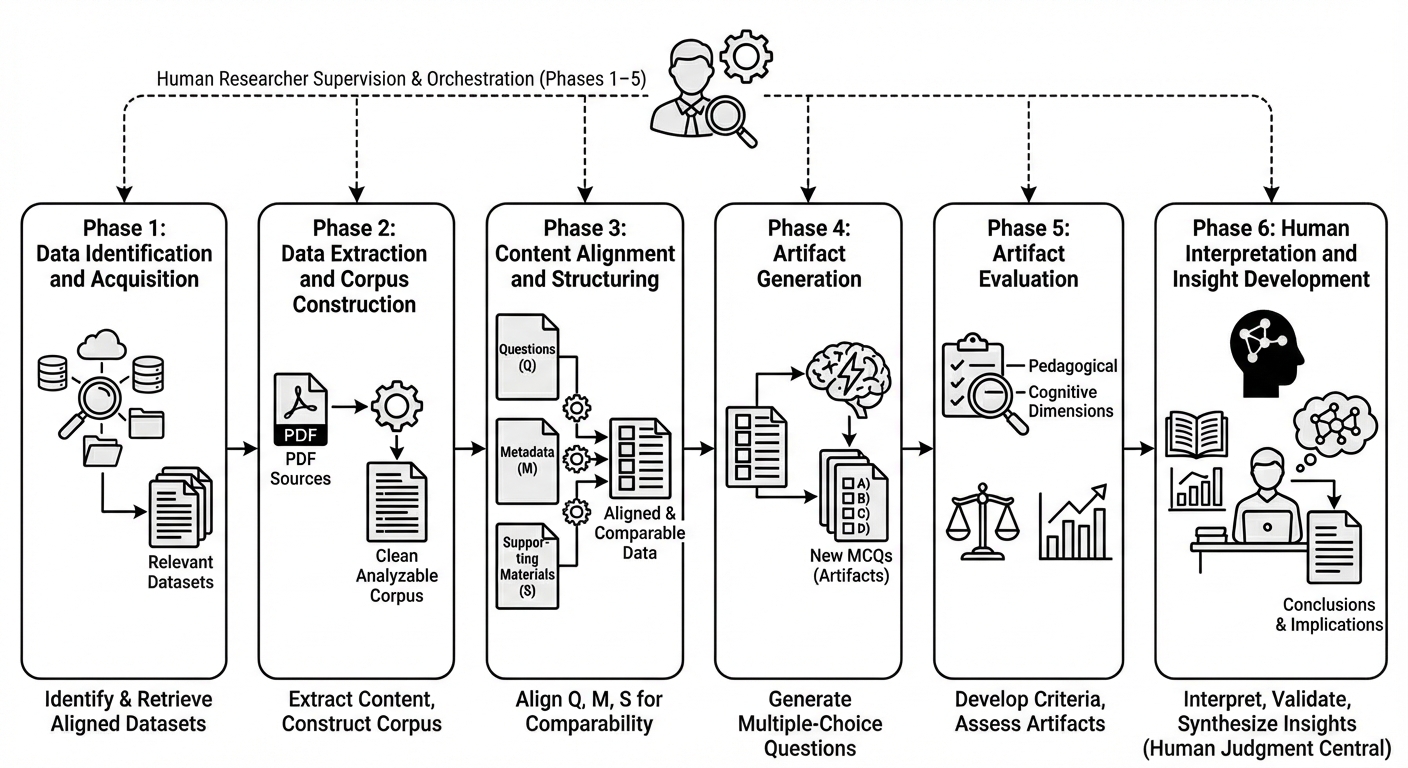
技术框架:整体框架包含以下几个主要模块:1) 数据提取:从PDF文档中提取SAT数学MCQ;2) 语料库构建:检索开放教科书并将其转换为结构化表示;3) 内容对齐:将每个MCQ与相关的教科书内容对齐;4) MCQ生成:在指定的难度和认知水平下生成新的MCQ;5) MCQ评估:使用24条标准的质量框架评估原始和生成的MCQ。
关键创新:该研究的关键创新在于将LLM智能体应用于科学研究流程的编排和自动化,并对生成的内容进行多维度质量评估。此外,该研究还揭示了AI辅助研究中人类研究员的角色转变,从内容创作者转变为流程管理者和质量把控者。
关键设计:在MCQ生成阶段,研究人员需要指定难度和认知水平等参数,并设计合适的提示词(prompt)来引导LLM智能体生成高质量的MCQ。在MCQ评估阶段,研究人员使用包含24条标准的质量框架,对MCQ的语法流畅性、选项清晰度、技能深度、认知参与、难度校准和元数据对齐等方面进行综合评估。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM智能体生成的MCQ平均质量较高,但在技能深度、认知参与和难度校准等方面与专家审核的基线问题存在差距。在24条质量标准中,没有一条标准能够达到完全等效。研究还发现,人类研究员的角色从内容创作者转变为流程管理者和质量把控者,需要具备AI研究运营技能。
🎯 应用场景
该研究成果可应用于教育领域,辅助教师快速生成高质量的练习题和测试题,提高教学效率。此外,该方法还可推广到其他科学研究领域,例如文献综述、数据分析和实验设计等,加速科研进程,降低科研成本。未来,随着LLM技术的不断发展,AI辅助研究将成为一种常态。
📄 摘要(原文)
Advances in large language models (LLMs) are rapidly transforming scientific work, yet empirical evidence on how these systems reshape research activities remains limited. We report a mixed-methods pilot evaluation of an AI-orchestrated research workflow in which a human researcher coordinated multiple LLM-based agents to perform data extraction, corpus construction, artifact generation, and artifact evaluation. Using the generation and assessment of multiple-choice questions (MCQs) as a testbed, we collected 1,071 SAT Math MCQs and employed LLM agents to extract questions from PDFs, retrieve and convert open textbooks into structured representations, align each MCQ with relevant textbook content, generate new MCQs under specified difficulty and cognitive levels, and evaluate both original and generated MCQs using a 24-criterion quality framework. Across all evaluations, average MCQ quality was high. However, criterion-level analysis and equivalence testing show that generated MCQs are not fully comparable to expert-vetted baseline questions. Strict similarity (24/24 criteria equivalent) was never achieved. Persistent gaps concentrated in skill\ depth, cognitive engagement, difficulty calibration, and metadata alignment, while surface-level qualities, such as {grammar fluency}, {clarity options}, {no duplicates}, were consistently strong. Beyond MCQ outcomes, the study documents a labor shift. The researcher's work moved from
authoring items'' toward {specification, orchestration, verification}, and {governance}. Formalizing constraints, designing rubrics, building validation loops, recovering from tool failures, and auditing provenance constituted the primary activities. We discuss implications for the future of scientific work, including emergingAI research operations'' skills required for AI-empowered research pipelines.