TPRU: Advancing Temporal and Procedural Understanding in Large Multimodal Models
作者: Zhenkun Gao, Xuhong Wang, Xin Tan, Yuan Xie
分类: cs.AI
发布日期: 2026-02-21
备注: Accepted to ICLR 2026. 17 pages. Code, data, and models are available at: https://github.com/Stephen-gzk/TPRU
🔗 代码/项目: GITHUB
💡 一句话要点
TPRU:提升多模态大模型在时序和程序理解能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 时序理解 程序理解 具身智能 强化学习微调
📋 核心要点
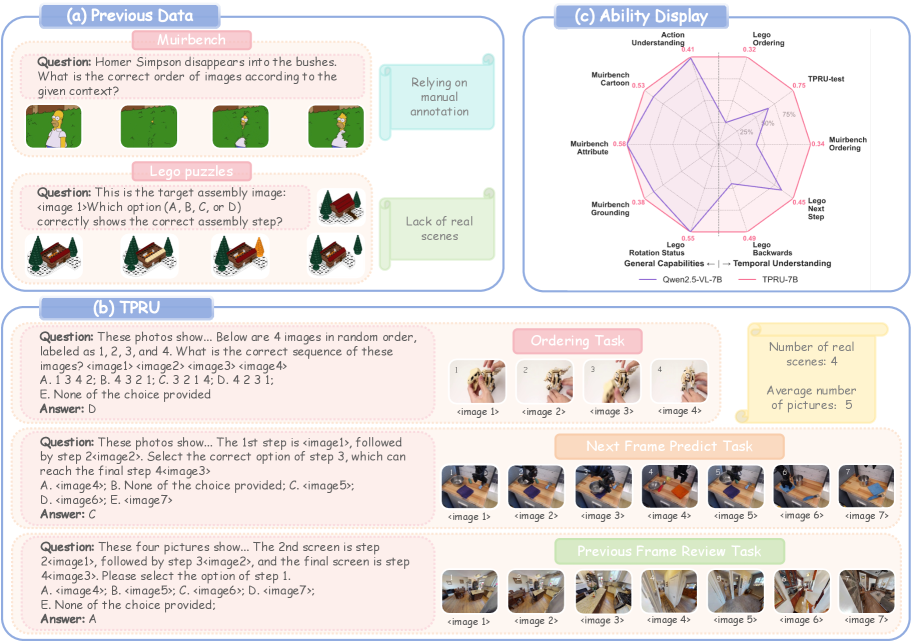
- 现有小规模多模态大模型在时序和程序理解方面存在不足,限制了其在具身智能领域的应用。
- 论文提出TPRU数据集,包含时间重排序、下一帧预测和前一帧回顾三个任务,并引入负样本进行训练。
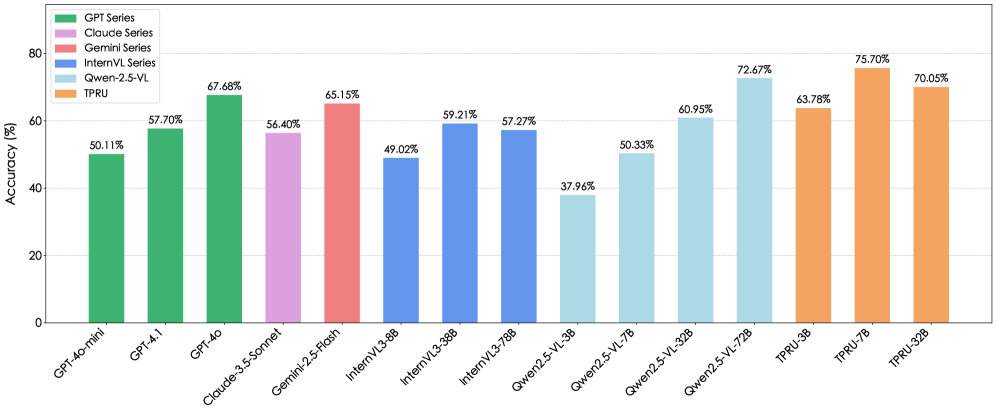
- 实验表明,使用TPRU训练的模型在TPRU-Test上取得了显著提升,并能泛化到其他基准测试中。
📝 摘要(中文)
多模态大语言模型(MLLMs),特别是较小型的、可部署的变体,在理解时序和程序性视觉数据方面存在严重不足,这阻碍了它们在现实世界具身智能中的应用。这种差距主要是由于训练范式中缺乏大规模、程序连贯的数据而导致的系统性失败。为了解决这个问题,我们引入了TPRU,这是一个大规模数据集,来源于机器人操作和GUI导航等不同的具身场景。TPRU经过系统设计,通过三个互补的任务来培养时间推理能力:时间重排序、下一帧预测和前一帧回顾。一个关键特征是包含具有挑战性的负样本,迫使模型从被动观察过渡到主动的跨模态验证。我们利用TPRU和强化学习(RL)微调方法,专门针对资源高效模型的增强。实验表明,我们的方法产生了显著的收益:在我们手动策划的TPRU-Test上,TPRU-7B的准确率从50.33%飙升至75.70%,这是一个最先进的结果,显著优于包括GPT-4o在内的更大的基线模型。重要的是,这些能力可以有效地推广,在已建立的基准上表现出显著的改进。
🔬 方法详解
问题定义:现有的小型多模态大模型难以理解和推理时序视觉数据,尤其是在需要程序性理解的具身智能任务中。现有的训练数据不足以支持模型学习复杂的时序关系和程序逻辑,导致模型性能瓶颈。
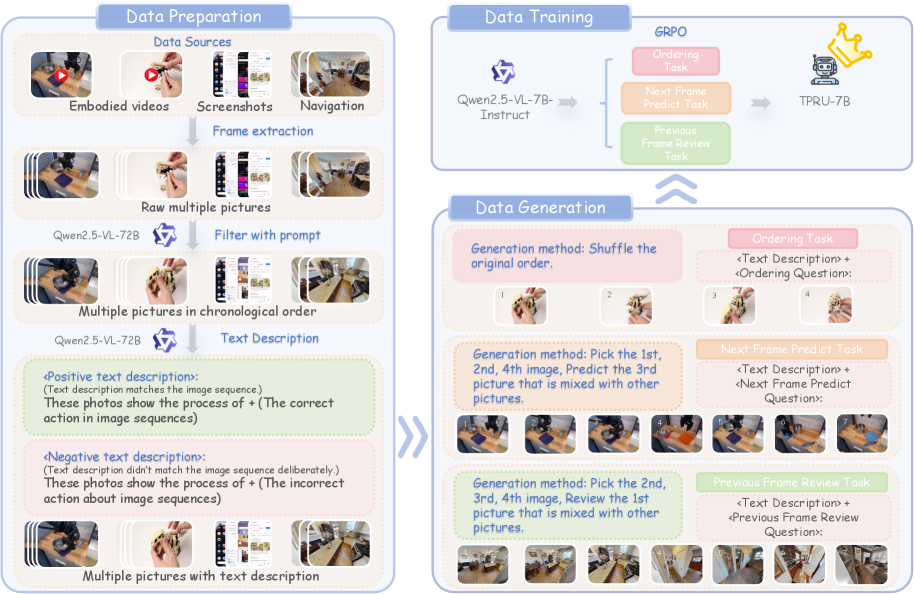
核心思路:论文的核心思路是通过构建一个大规模、程序连贯的数据集TPRU,并结合强化学习微调,来提升模型在时序和程序理解方面的能力。TPRU数据集包含多种具身智能场景,并设计了时间重排序、下一帧预测和前一帧回顾等任务,以增强模型的时间推理能力。
技术框架:整体框架包括数据收集与构建、模型训练和评估三个阶段。首先,从机器人操作和GUI导航等具身场景收集数据,并构建TPRU数据集。然后,使用TPRU数据集对多模态大模型进行强化学习微调。最后,在TPRU-Test和其他基准测试上评估模型的性能。
关键创新:最重要的技术创新点在于TPRU数据集的设计,它不仅规模大,而且具有程序连贯性,并包含了具有挑战性的负样本。这些负样本迫使模型进行主动的跨模态验证,从而更好地学习时序关系和程序逻辑。
关键设计:TPRU数据集包含三个任务:时间重排序(Temporal Reordering)、下一帧预测(Next-Frame Prediction)和前一帧回顾(Previous-Frame Review)。每个任务都包含正样本和负样本。负样本的设计至关重要,例如,在时间重排序任务中,负样本是随机打乱的时间序列。在强化学习微调方面,使用了策略梯度方法,目标是最大化模型在TPRU数据集上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用TPRU数据集训练的TPRU-7B模型在TPRU-Test上的准确率从50.33%提升至75.70%,显著优于包括GPT-4o在内的更大规模的基线模型。此外,该模型在其他已建立的基准测试上也表现出显著的改进,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于机器人操作、GUI导航、自动驾驶等具身智能领域。通过提升模型对时序和程序性视觉数据的理解能力,可以使机器人和智能体更好地理解环境、执行任务,并与人类进行更自然的交互。未来,该技术有望推动智能家居、工业自动化等领域的发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs), particularly smaller, deployable variants, exhibit a critical deficiency in understanding temporal and procedural visual data, a bottleneck hindering their application in real-world embodied AI. This gap is largely caused by a systemic failure in training paradigms, which lack large-scale, procedurally coherent data. To address this problem, we introduce TPRU, a large-scale dataset sourced from diverse embodied scenarios such as robotic manipulation and GUI navigation. TPRU is systematically designed to cultivate temporal reasoning through three complementary tasks: Temporal Reordering, Next-Frame Prediction, and Previous-Frame Review. A key feature is the inclusion of challenging negative samples, compelling models to transition from passive observation to active, cross-modal validation. We leverage TPRU with a reinforcement learning (RL) fine-tuning methodology, specifically targeting the enhancement of resource-efficient models. Experiments show our approach yields dramatic gains: on our manually curated TPRU-Test, the accuracy of TPRU-7B soars from 50.33\% to 75.70\%, a state-of-the-art result that significantly outperforms vastly larger baselines, including GPT-4o. Crucially, these capabilities generalize effectively, demonstrating substantial improvements on established benchmarks. The codebase is available at https://github.com/Stephen-gzk/TPRU/ .