Operational Robustness of LLMs on Code Generation
作者: Debalina Ghosh Paul, Hong Zhu, Ian Bayley
分类: cs.SE, cs.AI, cs.LG
发布日期: 2026-02-21
💡 一句话要点
提出场景域分析方法以评估LLMs在代码生成中的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 鲁棒性评估 自然语言处理 场景域分析
📋 核心要点
- 现有技术无法有效评估LLMs在代码生成中的鲁棒性,特别是在自然语言描述变化时的敏感性。
- 提出的场景域分析方法通过寻找自然语言描述的最小变化,评估LLMs的鲁棒性,解决了现有方法的不足。
- 实验结果显示,四种LLMs的鲁棒性排名明确,且复杂任务和高级主题的鲁棒性显著降低。
📝 摘要(中文)
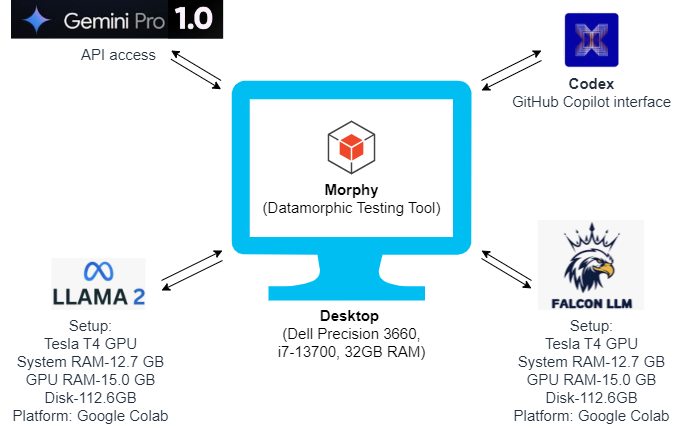
在软件开发中,使用大型语言模型(LLMs)生成程序代码已成为常态。本文关注LLMs在编码任务描述变化下的鲁棒性评估,现有评估技术不适用于代码生成,因为自然语言描述的输入数据空间是离散的。为此,提出了一种名为场景域分析的鲁棒性评估方法,旨在找出导致LLMs产生错误输出的自然语言描述的最小变化。我们对该方法的理论性质进行了正式证明,并对四种最先进的LLMs(Gemini-pro、Codex、Llamma2和Falcon 7B)进行了广泛实验,能够自信地对其鲁棒性进行排名。此外,我们还研究了鲁棒性在不同场景下的变化,发现复杂任务和高级主题(如多线程和数据结构)的鲁棒性较低。
🔬 方法详解
问题定义:本文旨在解决LLMs在代码生成中对自然语言描述变化的鲁棒性评估问题。现有方法无法处理离散的输入数据空间,导致评估结果不准确。
核心思路:提出的场景域分析方法通过识别导致LLMs输出错误的自然语言描述的最小变化,提供了一种新的评估框架。这种设计能够更好地捕捉描述变化对模型输出的影响。
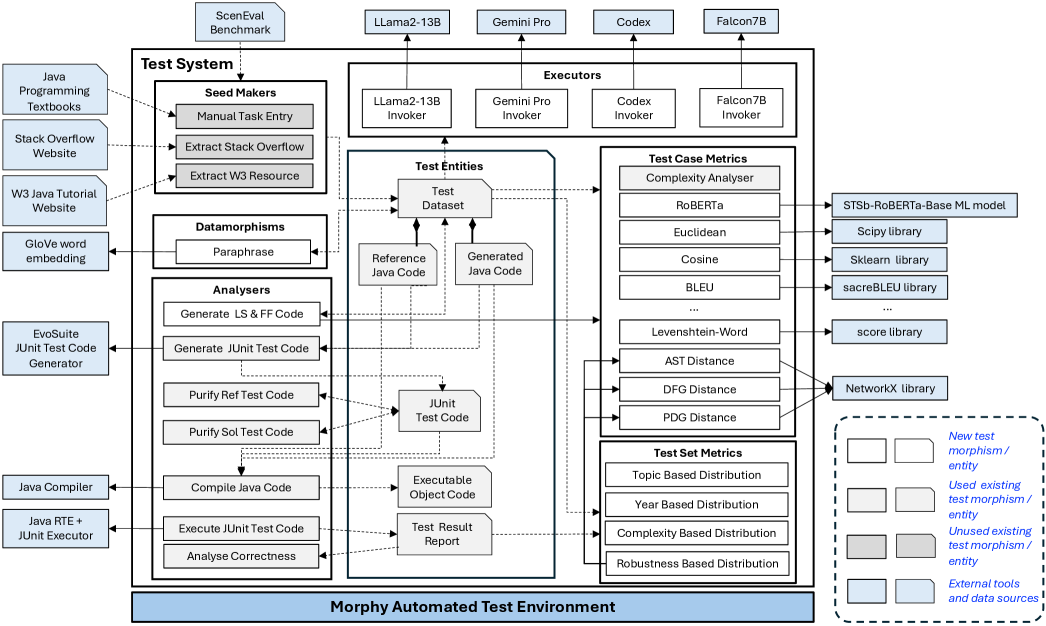
技术框架:该方法包括几个主要模块:首先,收集编码任务的自然语言描述;其次,分析描述变化对模型输出的影响;最后,通过实验验证不同描述变化的鲁棒性。
关键创新:最重要的创新在于提出了场景域分析这一新方法,能够系统地评估LLMs在代码生成中的鲁棒性,与现有方法相比具有更高的准确性和适用性。
关键设计:在实验中,设置了多种编码任务的复杂性和主题,并通过对比不同LLMs的输出,分析了鲁棒性与任务复杂性之间的关系。
🖼️ 关键图片
📊 实验亮点
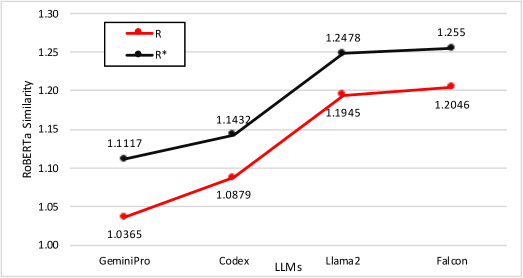
实验结果表明,四种LLMs的鲁棒性排名为Gemini-pro最佳,Codex次之,Llamma2和Falcon 7B表现较差。复杂任务和高级主题的鲁棒性显著低于简单任务,尤其是在多线程和数据结构方面,显示出鲁棒性与任务复杂性之间的负相关关系。
🎯 应用场景
该研究的潜在应用领域包括软件开发工具、自动化编程助手和教育领域的编程教学。通过提高LLMs在代码生成中的鲁棒性,可以显著提升开发效率和代码质量,未来可能推动编程自动化的进一步发展。
📄 摘要(原文)
It is now common practice in software development for large language models (LLMs) to be used to generate program code. It is desirable to evaluate the robustness of LLMs for this usage. This paper is concerned in particular with how sensitive LLMs are to variations in descriptions of the coding tasks. However, existing techniques for evaluating this robustness are unsuitable for code generation because the input data space of natural language descriptions is discrete. To address this problem, we propose a robustness evaluation method called scenario domain analysis, which aims to find the expected minimal change in the natural language descriptions of coding tasks that would cause the LLMs to produce incorrect outputs. We have formally proved the theoretical properties of the method and also conducted extensive experiments to evaluate the robustness of four state-of-the-art art LLMs: Gemini-pro, Codex, Llamma2 and Falcon 7B, and have found that we are able to rank these with confidence from best to worst. Moreover, we have also studied how robustness varies in different scenarios, including the variations with the topic of the coding task and with the complexity of its sample solution, and found that robustness is lower for more complex tasks and also lower for more advanced topics, such as multi-threading and data structures.