Federated Reasoning Distillation Framework with Model Learnability-Aware Data Allocation
作者: Wei Guo, Siyuan Lu, Xiangdong Ran, Yiqi Tong, Yikun Ban, Zelong Xu, Jing Fan, Zixuan Huang, Xiao Zhang, Zhaojun Hu, Fuzhen Zhuang
分类: cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出LaDa框架,通过模型可学习性感知的数据分配实现联邦推理蒸馏。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 推理蒸馏 模型可学习性 数据分配 领域自适应 对比学习 大语言模型 小语言模型
📋 核心要点
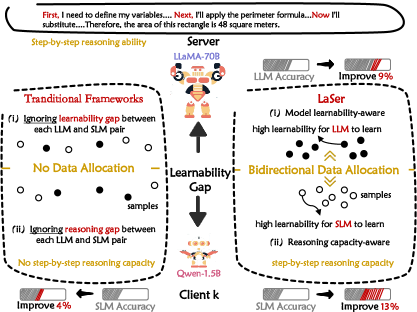
- 现有联邦学习推理协作方法忽略了LLM和SLM之间双向模型可学习性差距,导致知识迁移效率低下。
- LaDa框架通过模型可学习性感知的数据过滤器和领域自适应推理蒸馏,实现高效的双向知识迁移。
- LaDa作为一个插件模块,可以灵活地应用于现有联邦学习框架,提升SLM在本地数据上的推理能力。
📝 摘要(中文)
本文提出了一种名为LaDa的联邦推理蒸馏框架,该框架通过模型可学习性感知的数据分配来解决联邦大语言模型(LLM)和小语言模型(SLM)推理协作中的关键问题。现有方法未能解决双向模型可学习性差距,即客户端SLM无法识别与其学习能力相匹配的高回报样本,而LLM难以选择超出其现有知识的新颖样本。此外,现有推理迁移方法难以灵活适应本地领域数据,阻碍了SLM有效获取逐步推理能力。LaDa引入了一种模型可学习性感知的数据过滤器,自适应地分配高回报样本,有效促进双向知识迁移。进一步设计了一种领域自适应推理蒸馏方法,通过SLM和LLM之间的对比蒸馏学习,对齐过滤后的高回报样本上推理路径的联合概率,使SLM能够捕获本地数据分布下的潜在推理模式。LaDa作为一个插件模块,可以适应现有协作框架,并根据模型可学习性差距调整知识迁移。
🔬 方法详解
问题定义:现有联邦学习推理协作方法在数据分配方面存在不足,未能充分考虑LLM和SLM之间的双向可学习性差距。SLM难以识别适合自身学习能力的高回报样本,而LLM也难以选择能够提供新知识的样本。此外,现有推理迁移方法缺乏领域适应性,无法使SLM有效地学习本地数据分布下的推理模式。
核心思路:LaDa框架的核心思路是根据LLM和SLM之间的可学习性差距,自适应地分配高回报样本,并利用对比蒸馏学习对齐推理路径的联合概率,从而实现高效的双向知识迁移和领域自适应推理。
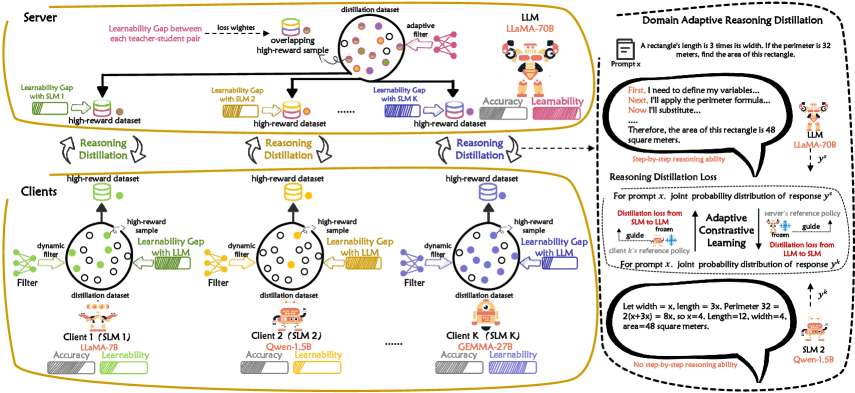
技术框架:LaDa框架主要包含两个模块:模型可学习性感知的数据过滤器和领域自适应推理蒸馏。数据过滤器根据LLM和SLM的可学习性差距,选择高回报样本。领域自适应推理蒸馏模块通过对比学习,对齐LLM和SLM在过滤后的样本上的推理路径概率分布。LaDa可以作为插件集成到现有的联邦学习框架中。
关键创新:LaDa的关键创新在于提出了模型可学习性感知的数据分配策略,该策略能够根据LLM和SLM的学习能力差异,动态地选择最适合双方进行知识迁移的样本。此外,领域自适应推理蒸馏方法能够使SLM更好地适应本地数据分布,提高推理性能。
关键设计:模型可学习性感知的数据过滤器通过计算LLM和SLM在样本上的预测差异来评估样本的回报。领域自适应推理蒸馏模块使用对比损失函数来对齐LLM和SLM的推理路径概率分布。具体损失函数的设计需要根据具体的任务和模型进行调整。
🖼️ 关键图片
📊 实验亮点
论文提出的LaDa框架通过模型可学习性感知的数据分配和领域自适应推理蒸馏,能够有效提升SLM在本地数据上的推理性能。具体实验结果未知,但该框架的设计思路具有较强的创新性和实用性,有望在实际应用中取得显著的性能提升。
🎯 应用场景
LaDa框架可应用于各种联邦学习场景,尤其是在需要LLM和SLM协同推理的场景中,例如联邦医疗诊断、金融风控等。通过LaDa,可以提升客户端SLM的推理能力,同时保护用户数据的隐私,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Data allocation plays a critical role in federated large language model (LLM) and small language models (SLMs) reasoning collaboration. Nevertheless, existing data allocation methods fail to address an under-explored challenge in collaboration: bidirectional model learnability gap, where client-side SLMs cannot identify high-reward samples matching their learnability constraints for effective knowledge transfer from LLMs, while LLMs struggle to select samples contributing novel knowledge beyond their existing data. Furthermore, these collaboration frameworks face another key challenge: domain-agnostic reasoning transfer, where existing reasoning transfer methods fail to flexibly adapt to the local domain data, preventing SLMs from effectively acquiring step-by-step reasoning abilities within from general LLM. To address these challenges, we propose LaDa, a federated reasoning distillation framework with model learnability-aware data allocation. It introduces a model learnability-aware data filter that adaptively allocates high-reward samples based on the learnability gap between each SLM and LLM pair, effectively facilitating bidirectional knowledge transfer. We further design a domain adaptive reasoning distillation method that aligns joint probabilities of reasoning paths on filtered high-reward samples through contrastive distillation learning between SLM and LLM, enabling SLM to capture underlying reasoning patterns under local data distribution. LaDa operates as a plug-in module for existing collaboration frameworks, adapting knowledge transfer based on model learnability gaps.