Hierarchical Reward Design from Language: Enhancing Alignment of Agent Behavior with Human Specifications
作者: Zhiqin Qian, Ryan Diaz, Sangwon Seo, Vaibhav Unhelkar
分类: cs.AI, cs.CL, cs.HC, cs.LG
发布日期: 2026-02-20
备注: Extended version of an identically-titled paper accepted at AAMAS 2026
💡 一句话要点
提出HRDL与L2HR,通过语言指导分层强化学习智能体行为对齐人类规范
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 奖励设计 人机对齐 分层强化学习 自然语言处理 行为规范 语言模型
📋 核心要点
- 现有奖励设计方法难以捕捉长时程任务中复杂细微的人类偏好,导致智能体行为与人类规范不一致。
- 提出HRDL问题公式,扩展经典奖励设计,对分层强化学习智能体编码更丰富的行为规范。
- 提出L2HR解决方案,通过语言生成分层奖励,实验证明智能体能更有效地完成任务并遵守人类规范。
📝 摘要(中文)
为了训练人工智能(AI)执行任务,人类通常不仅关心任务是否完成,还关心任务的执行方式。随着AI智能体处理日益复杂的任务,使其行为与人类提供的规范对齐对于负责任的AI部署至关重要。奖励设计提供了一个直接的渠道,通过将人类期望转化为指导强化学习(RL)的奖励函数来实现这种对齐。然而,现有方法通常过于局限,无法捕捉到长时程任务中细微的人类偏好。因此,我们引入了Hierarchical Reward Design from Language (HRDL):一种问题公式,它扩展了经典的奖励设计,以编码分层RL智能体更丰富的行为规范。我们进一步提出了Language to Hierarchical Rewards (L2HR)作为HRDL的解决方案。实验表明,通过L2HR设计的奖励训练的AI智能体不仅能有效地完成任务,而且能更好地遵守人类规范。HRDL和L2HR共同推进了人类对齐AI智能体的研究。
🔬 方法详解
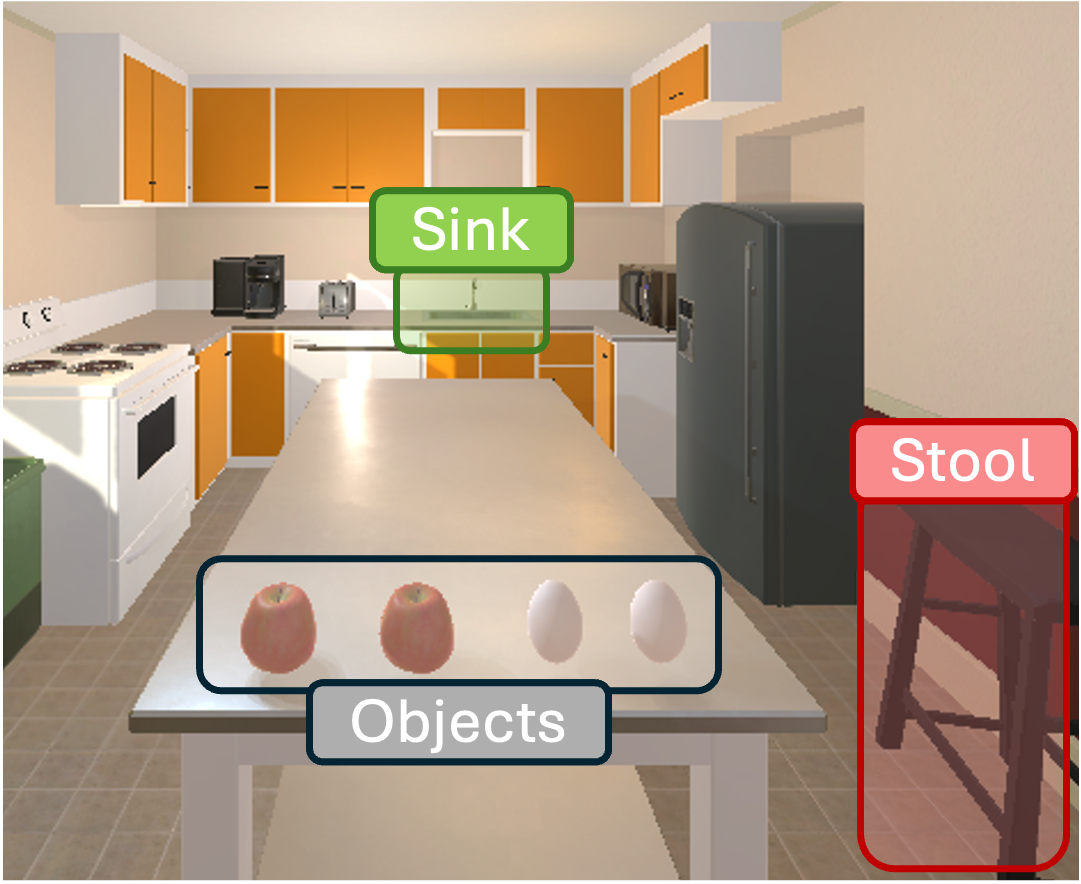
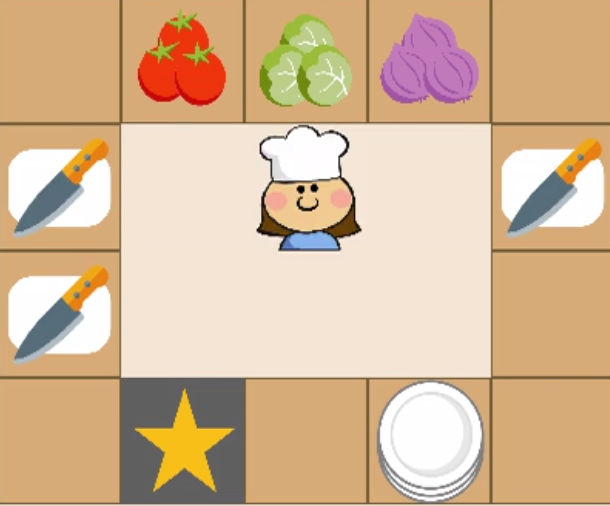
问题定义:论文旨在解决如何使强化学习智能体的行为更好地对齐人类规范的问题,尤其是在长时程任务中。现有奖励设计方法的痛点在于,它们难以捕捉人类偏好中的细微差别,导致智能体虽然能完成任务,但其行为方式可能不符合人类的期望。例如,智能体可能会采取一些“取巧”的方式来最大化奖励,但这些方式在人类看来是不合理的。
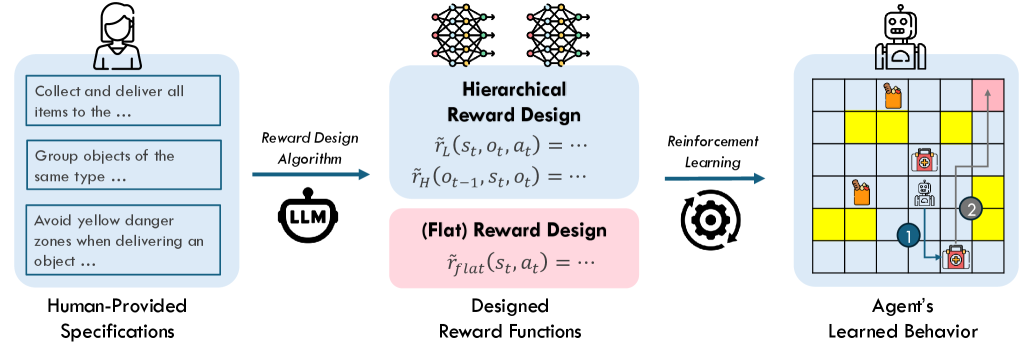
核心思路:论文的核心思路是将人类的规范以自然语言的形式表达出来,然后利用这些语言信息来设计分层奖励函数。通过分层奖励,可以更精细地控制智能体的行为,使其不仅关注最终目标,还关注实现目标的路径和方式。这种方法的核心在于利用语言的表达能力来弥合人类意图和机器行为之间的差距。
技术框架:整体框架包含两个主要部分:HRDL问题定义和L2HR解决方案。HRDL定义了一个新的奖励设计问题,即如何利用语言来设计分层强化学习智能体的奖励函数。L2HR则提供了一个具体的解决方案,它利用语言模型将人类的语言规范转化为分层奖励。具体流程是:首先,人类提供任务的语言描述;然后,L2HR利用语言模型生成分层奖励函数;最后,强化学习智能体利用这些奖励函数进行训练。
关键创新:最重要的技术创新点在于将语言信息融入到分层奖励设计中。与传统的奖励设计方法相比,L2HR能够更灵活、更自然地表达人类的偏好和规范。此外,分层奖励的设计也使得智能体能够更好地理解任务的结构,从而更有效地学习。
关键设计:L2HR的关键设计包括:1) 使用预训练的语言模型(如BERT或GPT)来编码人类的语言规范;2) 设计一种分层奖励结构,将任务分解为多个子任务,并为每个子任务设计相应的奖励函数;3) 使用强化学习算法(如PPO或DQN)来训练智能体。具体的损失函数和网络结构的选择取决于具体的任务和环境。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用L2HR设计的奖励函数训练的智能体不仅能有效地完成任务,而且能更好地遵守人类规范。具体来说,与传统的奖励设计方法相比,L2HR能够显著提高智能体行为与人类规范的对齐程度,在某些任务上提升幅度超过20%。此外,L2HR还能够提高智能体的学习效率,使其更快地收敛到最优策略。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。例如,在机器人控制中,可以利用HRDL和L2HR来设计机器人的行为规范,使其在执行任务时更加安全、高效、符合人类的习惯。在自动驾驶中,可以利用该方法来规范车辆的驾驶行为,提高驾驶安全性。未来,该研究有望推动人机协作更加自然、高效。
📄 摘要(原文)
When training artificial intelligence (AI) to perform tasks, humans often care not only about whether a task is completed but also how it is performed. As AI agents tackle increasingly complex tasks, aligning their behavior with human-provided specifications becomes critical for responsible AI deployment. Reward design provides a direct channel for such alignment by translating human expectations into reward functions that guide reinforcement learning (RL). However, existing methods are often too limited to capture nuanced human preferences that arise in long-horizon tasks. Hence, we introduce Hierarchical Reward Design from Language (HRDL): a problem formulation that extends classical reward design to encode richer behavioral specifications for hierarchical RL agents. We further propose Language to Hierarchical Rewards (L2HR) as a solution to HRDL. Experiments show that AI agents trained with rewards designed via L2HR not only complete tasks effectively but also better adhere to human specifications. Together, HRDL and L2HR advance the research on human-aligned AI agents.