RPU -- A Reasoning Processing Unit
作者: Matthew Adiletta, Gu-Yeon Wei, David Brooks
分类: cs.AR, cs.AI
发布日期: 2026-02-20
💡 一句话要点
RPU:面向推理应用的片上系统架构,解决大模型推理的访存瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型推理 内存墙 片上系统 HBM Chiplet架构 低延迟 高吞吐量 解耦微架构
📋 核心要点
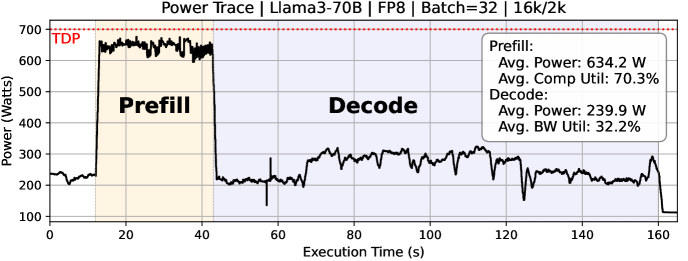
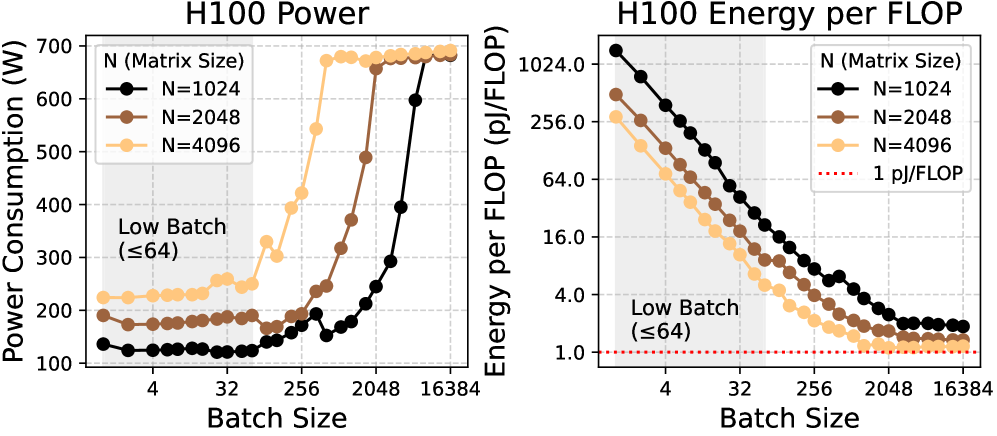
- 现有GPU在大模型推理中面临内存带宽瓶颈,尤其是在长序列、低算术强度推理任务中,导致利用率低、能耗高。
- 论文提出RPU架构,采用容量优化的HBM、可扩展chiplet设计和解耦微架构,旨在提升内存带宽利用率。
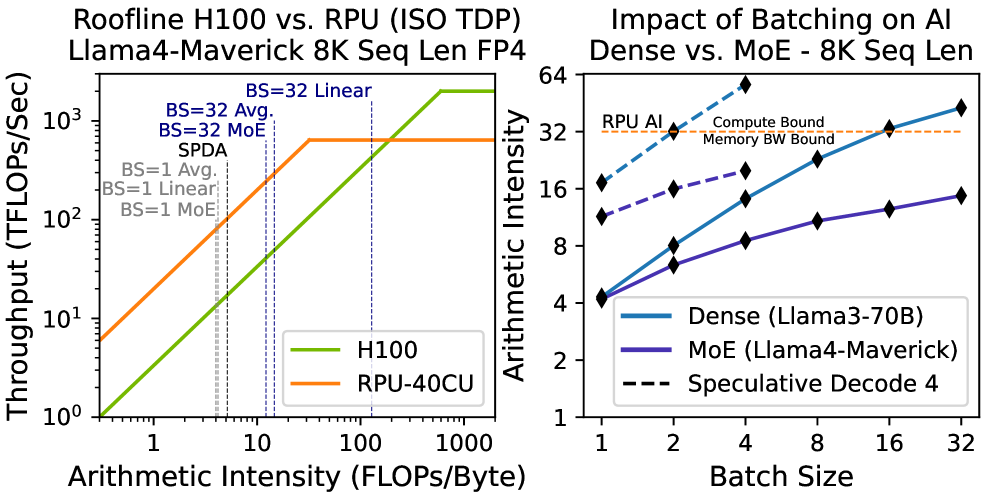
- 实验结果表明,RPU在Llama3-405B模型上,相比H100系统,延迟降低高达45.3倍,吞吐量提升高达18.6倍。
📝 摘要(中文)
大型语言模型(LLM)的推理性能日益受到内存墙的限制。尽管GPU持续提升原始计算吞吐量,但在内存带宽受限的工作负载下,难以实现可扩展的性能。新兴的推理LLM应用加剧了这一挑战,因为它们需要更长的输出序列、更低的算术强度和更严格的延迟约束,从而对内存带宽提出了更高的要求。这导致系统利用率下降,每次推理的能耗上升,突显了对可扩展内存带宽进行优化的系统架构的需求。为了应对这些挑战,我们提出了推理处理单元(RPU),这是一种基于chiplet的架构,旨在解决现代内存墙的挑战。RPU引入了:(1)容量优化的HBM(HBM-CO),它以容量换取更低的能耗和成本;(2)一种可扩展的chiplet架构,具有带宽优先的功率和面积配置设计;以及(3)一种解耦的微架构,它分离了内存、计算和通信流水线,以维持高带宽利用率。仿真结果表明,在Llama3-405B上,RPU在ISO-TDP下比H100系统实现了高达45.3倍的更低延迟和18.6倍的更高吞吐量。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中日益严重的内存墙问题。现有GPU虽然计算能力强大,但在处理内存带宽受限的LLM推理任务时,性能无法有效扩展。特别是对于需要长输出序列、低算术强度和严格延迟约束的推理应用,现有的GPU架构难以满足其对高内存带宽的需求,导致系统利用率低下和能耗过高。
核心思路:论文的核心思路是通过定制化的硬件架构来优化内存带宽的利用率。RPU通过采用容量优化的HBM(HBM-CO),牺牲部分容量来换取更低的能耗和成本,从而提高单位功耗下的带宽。此外,RPU采用可扩展的chiplet架构,并采用带宽优先的功率和面积配置策略,确保带宽资源得到充分利用。最后,RPU采用解耦的微架构,将内存、计算和通信流水线分离,避免相互阻塞,从而维持高带宽利用率。
技术框架:RPU的整体架构是一个基于chiplet的系统,包含多个计算chiplet和一个或多个HBM-CO存储chiplet。计算chiplet负责执行LLM推理的计算任务,HBM-CO chiplet负责提供高带宽的内存访问。chiplet之间通过高速互连网络进行通信。RPU的微架构采用解耦设计,包含独立的内存流水线、计算流水线和通信流水线。内存流水线负责从HBM-CO中读取数据,计算流水线负责执行计算操作,通信流水线负责在chiplet之间传输数据。
关键创新:RPU的关键创新在于其针对LLM推理任务的定制化设计。HBM-CO通过牺牲部分容量来换取更低的能耗和成本,从而提高了单位功耗下的带宽。可扩展的chiplet架构允许根据应用需求灵活配置计算和存储资源。解耦的微架构避免了内存、计算和通信之间的相互阻塞,从而提高了带宽利用率。
关键设计:HBM-CO的关键设计在于其容量和带宽的权衡。论文可能详细描述了HBM-CO的存储单元结构、访问模式和功耗优化策略。Chiplet架构的关键设计在于chiplet之间的互连网络拓扑、带宽分配和通信协议。解耦微架构的关键设计在于流水线的划分、调度策略和数据缓冲机制。这些设计的具体参数和实现细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RPU在Llama3-405B模型上,相比H100系统,在ISO-TDP约束下,实现了高达45.3倍的更低延迟和18.6倍的更高吞吐量。这些显著的性能提升验证了RPU架构在解决LLM推理内存瓶颈方面的有效性,表明其在实际应用中具有巨大的潜力。
🎯 应用场景
RPU架构适用于对延迟和吞吐量有较高要求的LLM推理应用,例如在线对话系统、实时翻译、智能客服等。通过提高内存带宽利用率,RPU可以显著降低推理延迟,提高系统吞吐量,并降低能耗,从而为用户提供更流畅、更高效的AI服务。未来,RPU架构有望应用于各种边缘计算设备和数据中心,推动LLM推理的普及。
📄 摘要(原文)
Large language model (LLM) inference performance is increasingly bottlenecked by the memory wall. While GPUs continue to scale raw compute throughput, they struggle to deliver scalable performance for memory bandwidth bound workloads. This challenge is amplified by emerging reasoning LLM applications, where long output sequences, low arithmetic intensity, and tight latency constraints demand significantly higher memory bandwidth. As a result, system utilization drops and energy per inference rises, highlighting the need for an optimized system architecture for scalable memory bandwidth. To address these challenges we present the Reasoning Processing Unit (RPU), a chiplet-based architecture designed to address the challenges of the modern memory wall. RPU introduces: (1) A Capacity-Optimized High-Bandwidth Memory (HBM-CO) that trades capacity for lower energy and cost; (2) a scalable chiplet architecture featuring a bandwidth-first power and area provisioning design; and (3) a decoupled microarchitecture that separates memory, compute, and communication pipelines to sustain high bandwidth utilization. Simulation results show that RPU performs up to 45.3x lower latency and 18.6x higher throughput over an H100 system at ISO-TDP on Llama3-405B.