Diffusing to Coordinate: Efficient Online Multi-Agent Diffusion Policies
作者: Zhuoran Li, Hai Zhong, Xun Wang, Qingxin Xia, Lihua Zhang, Longbo Huang
分类: cs.AI
发布日期: 2026-02-20
💡 一句话要点
提出OMAD框架,利用扩散策略解决在线多智能体强化学习中的探索与协调难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 扩散模型 在线学习 策略表达 探索与协调
📋 核心要点
- 在线多智能体强化学习中,现有方法难以兼顾策略表达能力和高效探索,阻碍了智能体间的有效协调。
- OMAD框架通过最大化缩放的联合熵来放宽策略目标,促进了有效的探索,无需依赖于难以处理的可能性。
- 实验表明,OMAD在多个任务中显著提升了样本效率,性能超越现有方法,成为新的state-of-the-art。
📝 摘要(中文)
在线多智能体强化学习(MARL)是实现高效智能体协作的重要框架。提升策略的表达能力是获得卓越性能的关键。基于扩散的生成模型在图像生成和离线环境中表现出卓越的表达能力和多模态表示,但其在在线MARL中的潜力尚未被充分挖掘。主要障碍在于扩散模型难以处理的可能性阻碍了基于熵的探索和协调。为了解决这个问题,我们提出了首个使用扩散策略的在线off-policy MARL框架(OMAD)来协调协作。我们的关键创新是放宽了策略目标,从而最大化缩放的联合熵,促进了有效的探索,而无需依赖于易于处理的可能性。作为补充,在集中式训练和分散式执行(CTDE)范式中,我们采用联合分布价值函数来优化分散的扩散策略。它利用易于处理的熵增强目标来指导扩散策略的同步更新,从而确保稳定的协调。在MPE和MAMuJoCo上的广泛评估表明,我们的方法在10个不同的任务中成为新的最先进方法,在样本效率方面实现了2.5倍到5倍的显著提高。
🔬 方法详解
问题定义:论文旨在解决在线多智能体强化学习(MARL)中,智能体策略表达能力不足和探索效率低下的问题。现有方法通常难以在策略的复杂性和可训练性之间取得平衡,导致智能体难以有效探索环境并进行协调。扩散模型虽然具有强大的表达能力,但其难以处理的似然性阻碍了基于熵的有效探索。
核心思路:论文的核心思路是利用扩散模型强大的策略表达能力,并设计一种新的训练目标,以克服扩散模型似然性难以处理的问题。通过最大化缩放的联合熵,鼓励智能体进行有效的探索,而无需直接计算扩散模型的似然性。同时,采用集中式训练分散式执行(CTDE)范式,利用联合分布价值函数来指导分散式扩散策略的更新,确保智能体之间的稳定协调。
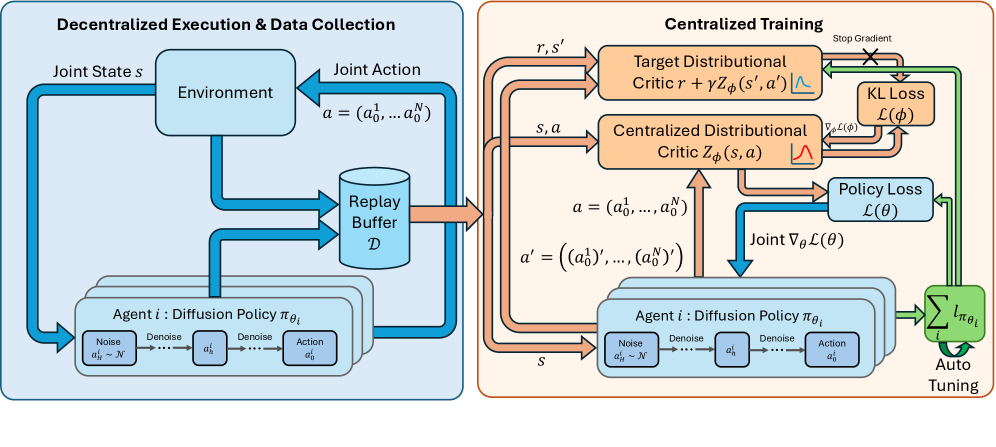
技术框架:OMAD框架采用CTDE范式,包含以下主要模块:1) 分布式扩散策略网络,用于生成每个智能体的动作;2) 联合分布价值函数网络,用于评估联合动作的价值;3) 熵正则化目标函数,用于鼓励智能体进行探索。训练过程包括:智能体与环境交互收集数据,利用收集到的数据更新扩散策略网络和价值函数网络,重复以上过程直到策略收敛。
关键创新:论文的关键创新在于:1) 提出了基于扩散模型的在线MARL框架OMAD;2) 设计了一种新的策略目标,通过最大化缩放的联合熵来促进探索,避免了直接计算扩散模型似然性的难题;3) 利用联合分布价值函数来指导分散式扩散策略的更新,保证了智能体之间的稳定协调。
关键设计:OMAD框架的关键设计包括:1) 扩散模型的选择:论文中使用的扩散模型类型未知,但需要选择适合于连续动作空间的扩散模型;2) 缩放联合熵的系数:该系数控制了探索的强度,需要根据具体任务进行调整;3) 联合分布价值函数的网络结构:需要设计合适的网络结构来捕捉智能体之间的依赖关系;4) 损失函数的设计:需要设计合适的损失函数来同时优化扩散策略网络和价值函数网络。
🖼️ 关键图片
📊 实验亮点
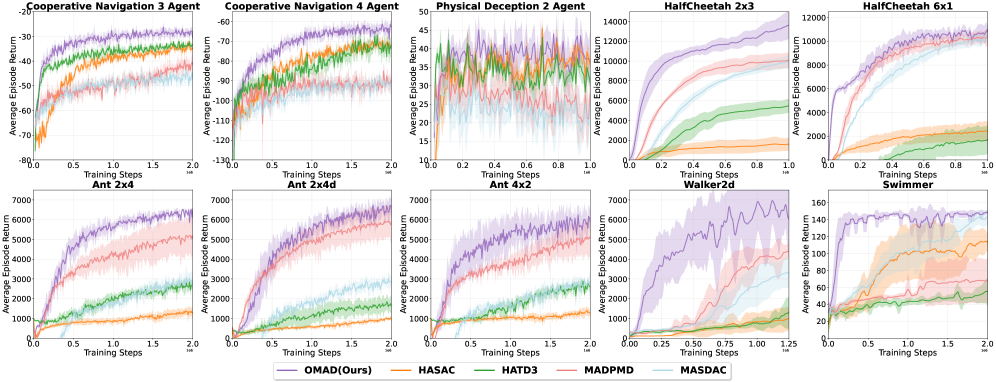
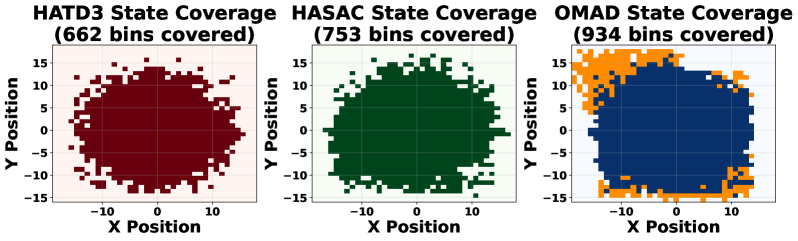
OMAD在MPE和MAMuJoCo的10个不同任务上进行了广泛评估,实验结果表明,OMAD在样本效率方面实现了2.5倍到5倍的显著提升,超越了现有的state-of-the-art方法。这表明OMAD能够更有效地利用数据进行学习,从而更快地找到最优策略,尤其是在样本获取成本较高的场景中具有重要意义。
🎯 应用场景
该研究成果可应用于需要多智能体高效协作的复杂环境,例如自动驾驶、机器人协同、资源分配、交通调度等领域。通过提升智能体的策略表达能力和探索效率,可以显著提高多智能体系统的性能和鲁棒性,使其能够更好地适应动态变化的环境,并完成复杂的协作任务。未来,该方法有望在更多实际场景中得到应用,推动多智能体系统的发展。
📄 摘要(原文)
Online Multi-Agent Reinforcement Learning (MARL) is a prominent framework for efficient agent coordination. Crucially, enhancing policy expressiveness is pivotal for achieving superior performance. Diffusion-based generative models are well-positioned to meet this demand, having demonstrated remarkable expressiveness and multimodal representation in image generation and offline settings. Yet, their potential in online MARL remains largely under-explored. A major obstacle is that the intractable likelihoods of diffusion models impede entropy-based exploration and coordination. To tackle this challenge, we propose among the first \underline{O}nline off-policy \underline{MA}RL framework using \underline{D}iffusion policies (\textbf{OMAD}) to orchestrate coordination. Our key innovation is a relaxed policy objective that maximizes scaled joint entropy, facilitating effective exploration without relying on tractable likelihood. Complementing this, within the centralized training with decentralized execution (CTDE) paradigm, we employ a joint distributional value function to optimize decentralized diffusion policies. It leverages tractable entropy-augmented targets to guide the simultaneous updates of diffusion policies, thereby ensuring stable coordination. Extensive evaluations on MPE and MAMuJoCo establish our method as the new state-of-the-art across $10$ diverse tasks, demonstrating a remarkable $2.5\times$ to $5\times$ improvement in sample efficiency.