MeanVoiceFlow: One-step Nonparallel Voice Conversion with Mean Flows
作者: Takuhiro Kaneko, Hirokazu Kameoka, Kou Tanaka, Yuto Kondo
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2026-02-20
备注: Accepted to ICASSP 2026. Project page: https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/meanvoiceflow/
💡 一句话要点
提出MeanVoiceFlow,一种基于平均流的单步非平行语音转换模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音转换 流匹配 平均流 单步转换 非平行训练
📋 核心要点
- 扩散模型和流匹配模型在语音转换中表现出色,但迭代推理导致转换速度慢。
- MeanVoiceFlow利用平均流计算时间积分,实现单步转换,无需预训练或蒸馏。
- 引入结构裕度重构损失和条件扩散输入训练,提升训练稳定性和源信息利用率。
📝 摘要(中文)
本文提出了一种名为MeanVoiceFlow的单步非平行语音转换模型,该模型基于平均流,无需预训练或知识蒸馏即可从头开始训练。与使用瞬时速度的传统流匹配不同,平均流使用平均速度来更准确地计算单步推理路径上的时间积分。为了解决平均速度训练中因目标速度导数导致的训练不稳定问题,引入了结构裕度重构损失作为零输入约束,适度正则化模型的输入输出行为。此外,提出了条件扩散输入训练,在训练和推理期间使用噪声和源数据的混合作为模型输入,使模型能够有效地利用源信息,同时保持训练和推理之间的一致性。实验结果表明,MeanVoiceFlow即使从头开始训练,也能达到与之前的多步和基于蒸馏的模型相当的性能。
🔬 方法详解
问题定义:语音转换旨在改变语音的音色,使其听起来像目标说话者。现有的基于扩散模型和流匹配模型的语音转换方法,虽然音质和说话人相似度高,但由于需要迭代推理,转换速度较慢,难以满足实时性需求。
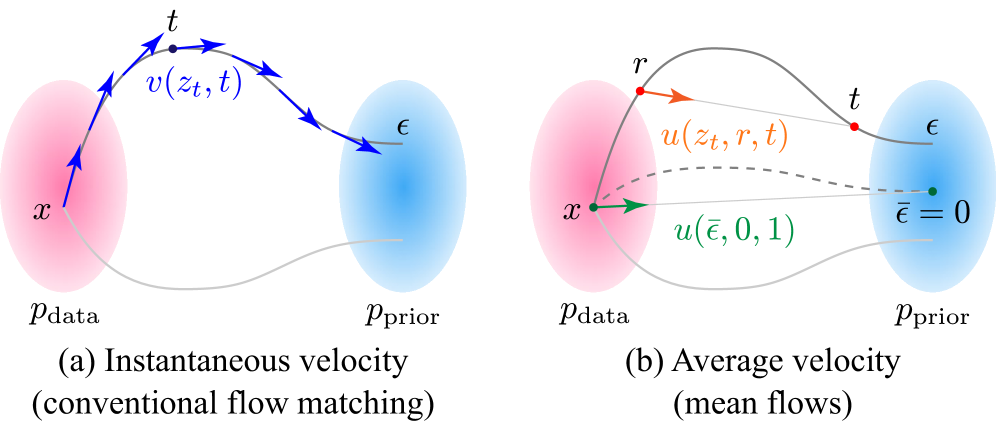
核心思路:MeanVoiceFlow的核心思路是使用平均流(Mean Flows)来近似推理路径上的时间积分,从而实现单步语音转换。与传统的流匹配方法使用瞬时速度不同,平均流使用平均速度,能够更准确地计算整个推理过程,从而避免迭代。
技术框架:MeanVoiceFlow的整体框架包括一个基于神经网络的映射函数,该函数将源语音特征映射到目标语音特征。该模型通过最小化一个损失函数进行训练,该损失函数包括流匹配损失和结构裕度重构损失。在推理阶段,模型接收源语音特征作为输入,并直接输出转换后的目标语音特征。
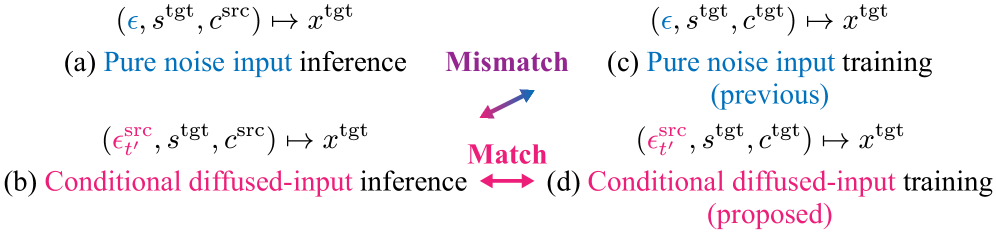
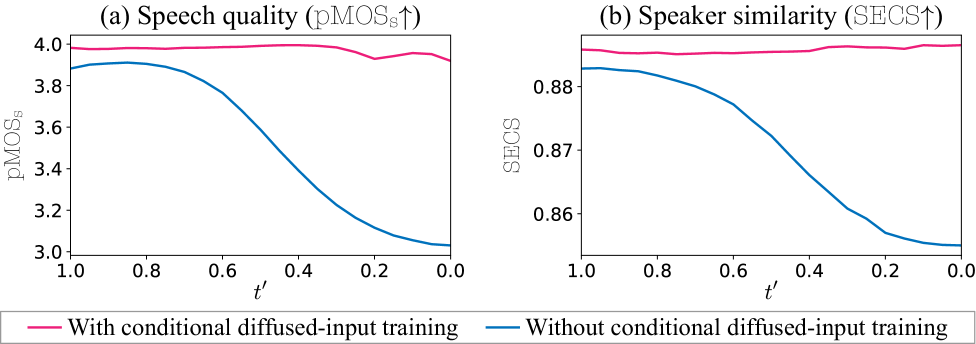
关键创新:MeanVoiceFlow的关键创新在于使用平均流进行单步语音转换。此外,为了解决平均流训练中可能出现的训练不稳定问题,引入了结构裕度重构损失作为零输入约束,以正则化模型的输入输出行为。条件扩散输入训练也是一个创新点,它允许模型在训练和推理期间有效地利用源信息。
关键设计:MeanVoiceFlow的关键设计包括:1) 使用平均流来近似时间积分;2) 引入结构裕度重构损失,其形式为 ||f(0)||,其中 f 是模型,0 是零输入;3) 采用条件扩散输入训练,即在训练和推理时,模型的输入是源数据和噪声的混合,混合比例是一个超参数。具体的网络结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MeanVoiceFlow在语音质量和说话人相似度方面达到了与之前多步和基于蒸馏的模型相当的性能,同时实现了单步转换,显著提高了转换速度。具体性能数据和对比基线在论文中给出,但此处未提供。
🎯 应用场景
MeanVoiceFlow在语音合成、语音编辑、个性化语音助手等领域具有广泛的应用前景。它可以用于快速生成具有特定说话人音色的语音,例如,将文本转换为特定角色的语音,或将一个人的语音转换为另一个人的语音。该技术还可以用于语音修复,例如,恢复受损语音的清晰度。
📄 摘要(原文)
In voice conversion (VC) applications, diffusion and flow-matching models have exhibited exceptional speech quality and speaker similarity performances. However, they are limited by slow conversion owing to their iterative inference. Consequently, we propose MeanVoiceFlow, a novel one-step nonparallel VC model based on mean flows, which can be trained from scratch without requiring pretraining or distillation. Unlike conventional flow matching that uses instantaneous velocity, mean flows employ average velocity to more accurately compute the time integral along the inference path in a single step. However, training the average velocity requires its derivative to compute the target velocity, which can cause instability. Therefore, we introduce a structural margin reconstruction loss as a zero-input constraint, which moderately regularizes the input-output behavior of the model without harmful statistical averaging. Furthermore, we propose conditional diffused-input training in which a mixture of noise and source data is used as input to the model during both training and inference. This enables the model to effectively leverage source information while maintaining consistency between training and inference. Experimental results validate the effectiveness of these techniques and demonstrate that MeanVoiceFlow achieves performance comparable to that of previous multi-step and distillation-based models, even when trained from scratch. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/meanvoiceflow/.