Mean-Field Reinforcement Learning without Synchrony
作者: Shan Yang
分类: cs.MA, cs.AI, cs.LG
发布日期: 2026-02-20
备注: 21 pages, 5 figures, 1 algorithm
💡 一句话要点
提出基于人口分布的均场强化学习以解决异步问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 均场强化学习 多智能体系统 异步决策 人口分布 策略梯度算法 动态调度 资源分配
📋 核心要点
- 现有的均场强化学习方法要求所有智能体在每个时间步都必须行动,导致在异步情况下均值动作无法定义。
- 本文提出了一种新的统计量——人口分布$μ$,构建了时间均场(TMF)框架,能够处理异步决策问题。
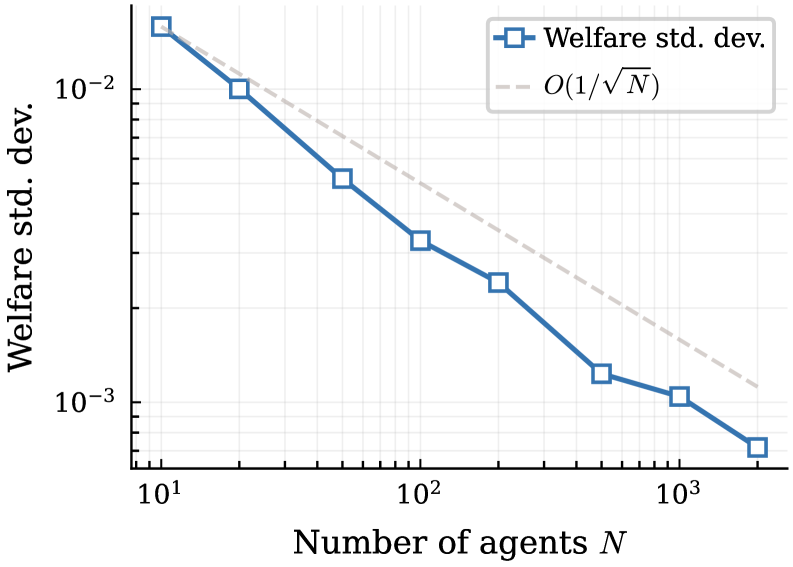
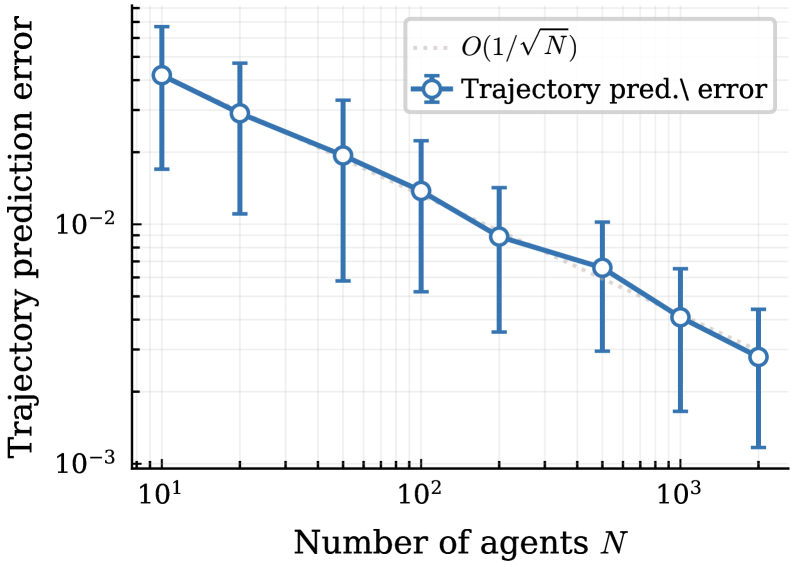
- 实验结果表明,TMF-PG算法在资源选择游戏和动态排队游戏中表现出色,近似误差以$O(1/ extin{√N})$速率衰减。
📝 摘要(中文)
均场强化学习(MF-RL)通过将每个智能体对其他智能体的依赖简化为一个单一的统计量——均值动作,从而扩展了多智能体强化学习到大规模人群。然而,这种简化要求每个智能体在每个时间步都必须行动,当某些智能体处于闲置状态时,均值动作就无法定义。为了解决异步问题,本文提出了一种新的统计量——人口分布$μ extin{∈}Δ( extin{O})$,它在任何智能体行动的情况下都保持定义。我们构建了以人口分布$μ$为基础的时间均场(TMF)框架,涵盖了从完全同步到纯序列决策的完整理论。我们证明了TMF均衡的存在性和唯一性,并建立了一个$O(1/ extin{√N})$的有限人群近似界限,证明了策略梯度算法(TMF-PG)收敛到唯一均衡的性质。实验结果表明,无论是一个智能体还是所有$N$个智能体每步行动,TMF-PG的表现几乎相同,近似误差以$O(1/ extin{√N})$的速率衰减。
🔬 方法详解
问题定义:本文旨在解决均场强化学习中异步决策导致的均值动作无法定义的问题。现有方法依赖于所有智能体在每个时间步都行动,限制了其在大规模人群中的应用。
核心思路:提出人口分布$μ$作为新的统计量,能够在任意智能体行动的情况下保持定义,从而构建时间均场(TMF)框架,涵盖从完全同步到纯序列决策的情况。
技术框架:TMF框架包括人口分布的定义、均衡的存在性和唯一性证明、有限人群近似界限的建立,以及策略梯度算法(TMF-PG)的收敛性分析。
关键创新:TMF框架的核心创新在于引入人口分布$μ$,与传统的均值动作方法相比,TMF能够处理异步决策场景,拓宽了均场强化学习的应用范围。
关键设计:在TMF-PG算法中,设计了适应于人口分布的损失函数和更新规则,确保算法在不同数量的智能体行动时均能保持良好的收敛性和性能。
🖼️ 关键图片
📊 实验亮点
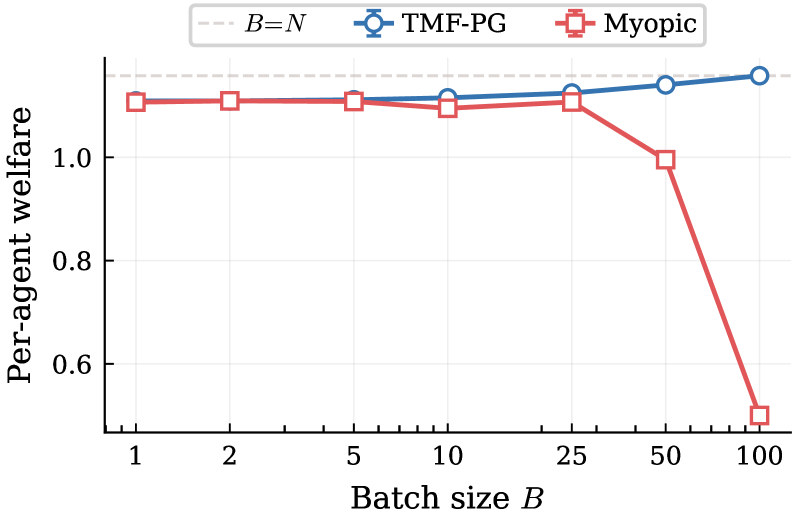
实验结果显示,TMF-PG在资源选择游戏和动态排队游戏中的表现几乎相同,无论是一个智能体还是所有$N$个智能体每步行动,近似误差以$O(1/ extin{√N})$的速率衰减,验证了理论的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括多智能体系统、资源分配、动态调度等场景,尤其适用于需要处理异步决策的复杂环境。通过提供一种新的理论框架,TMF有望在实际应用中提升多智能体强化学习的效率和稳定性,推动相关领域的发展。
📄 摘要(原文)
Mean-field reinforcement learning (MF-RL) scales multi-agent RL to large populations by reducing each agent's dependence on others to a single summary statistic -- the mean action. However, this reduction requires every agent to act at every time step; when some agents are idle, the mean action is simply undefined. Addressing asynchrony therefore requires a different summary statistic -- one that remains defined regardless of which agents act. The population distribution $μ\in Δ(\mathcal{O})$ -- the fraction of agents at each observation -- satisfies this requirement: its dimension is independent of $N$, and under exchangeability it fully determines each agent's reward and transition. Existing MF-RL theory, however, is built on the mean action and does not extend to $μ$. We therefore construct the Temporal Mean Field (TMF) framework around the population distribution $μ$ from scratch, covering the full spectrum from fully synchronous to purely sequential decision-making within a single theory. We prove existence and uniqueness of TMF equilibria, establish an $O(1/\sqrt{N})$ finite-population approximation bound that holds regardless of how many agents act per step, and prove convergence of a policy gradient algorithm (TMF-PG) to the unique equilibrium. Experiments on a resource selection game and a dynamic queueing game confirm that TMF-PG achieves near-identical performance whether one agent or all $N$ act per step, with approximation error decaying at the predicted $O(1/\sqrt{N})$ rate.