Aurora: Neuro-Symbolic AI Driven Advising Agent
作者: Lorena Amanda Quincoso Lugones, Christopher Kverne, Nityam Sharadkumar Bhimani, Ana Carolina Oliveira, Agoritsa Polyzou, Christine Lisetti, Janki Bhimani
分类: cs.HC, cs.AI
发布日期: 2026-02-20
备注: Accepted to 41st ACM/SIGAPP Symposium On Applied Computing. 8 Pages, 3 Figures
💡 一句话要点
Aurora:神经符号AI驱动的智能选课顾问,解决高校咨询瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经符号AI 智能选课顾问 检索增强生成 符号推理 大型语言模型 高校学业指导 课程推荐
📋 核心要点
- 高校学业指导资源紧张,师生比例失衡导致学生难以获得及时有效的指导,影响毕业率和公平性。
- Aurora采用神经符号AI方法,结合检索增强生成、符号推理和规范化课程数据,提供策略合规、可验证的选课建议。
- 实验表明,Aurora在语义对齐方面提升36%,推理精度高,响应速度快83倍,证明了其有效性和效率。
📝 摘要(中文)
高等教育中的学业指导面临巨大压力,师生比例通常超过300:1。这种结构性瓶颈限制了及时指导,增加了延迟毕业的风险,并加剧了学生支持方面的不平等。我们介绍了Aurora,一个模块化的神经符号咨询代理,它统一了检索增强生成(RAG)、符号推理和规范化的课程数据库,以大规模提供符合策略、可验证的建议。Aurora集成了三个组件:(i)用于一致程序规则的Boyce-Codd范式(BCNF)目录模式,(ii)用于先决条件和学分执行的Prolog引擎,以及(iii)用于对其建议进行自然语言解释的指令调整的大型语言模型。为了评估性能,我们设计了一个结构化的评估套件,涵盖了常见和边缘案例的咨询场景,包括短期调度、长期路线图、技能对齐的路径和超出范围的请求。在这个多样化的集合中,Aurora将与专家制作的答案的语义对齐从0.68(原始LLM基线)提高到0.93(+36%),在近一半的范围内案例中实现了完美的精确率和召回率,并始终为无法回答的提示产生正确的后备方案。在通用硬件上,Aurora提供亚秒级的平均延迟(20个查询的平均延迟为0.71秒),比原始LLM基线(59.2秒)快约83倍。通过将符号严谨性与神经流畅性相结合,Aurora推进了准确、可解释和可扩展的AI驱动咨询的范例。
🔬 方法详解
问题定义:当前高校学业指导面临师生比例严重失衡的问题,学生难以获得及时、个性化的指导。现有方法,如人工咨询,效率低下且成本高昂。纯粹依赖大型语言模型(LLM)的方案,虽然具备自然语言交互能力,但在保证建议的准确性、合规性和可解释性方面存在挑战。现有方法缺乏对课程规则和先修知识的严格约束,容易产生错误或不符合规定的建议。
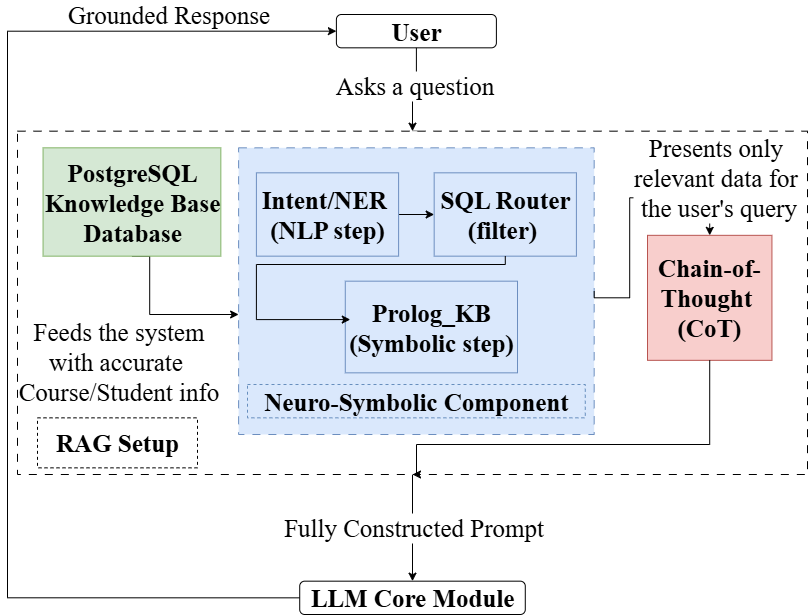
核心思路:Aurora的核心思路是将神经模型的流畅性和符号推理的严谨性相结合,构建一个既能理解学生需求,又能严格遵守课程规则的智能咨询代理。通过融合检索增强生成(RAG)、符号推理和规范化课程数据库,Aurora旨在提供准确、可解释、可验证且可扩展的学业指导服务。
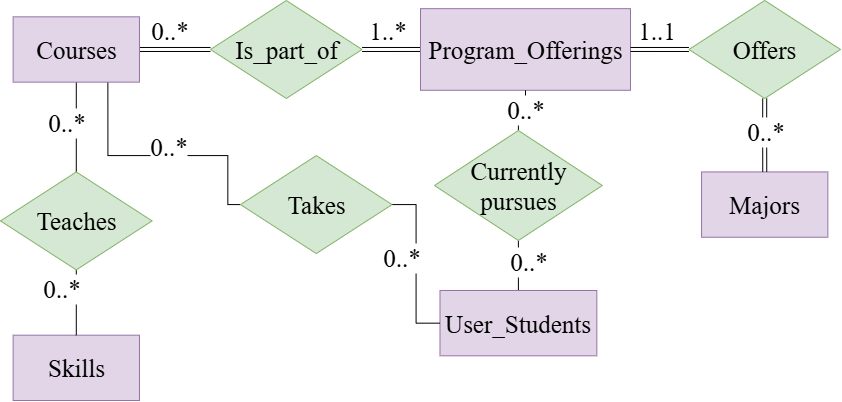
技术框架:Aurora包含三个主要模块:(1) BCNF目录模式:用于存储和管理规范化的课程规则,确保数据一致性。(2) Prolog引擎:用于执行先修课程和学分要求等符号推理,保证建议的合规性。(3) 指令调整的LLM:用于生成自然语言解释,使建议更易于理解。整体流程是:用户输入问题,系统检索相关课程信息,Prolog引擎进行规则验证,LLM生成建议和解释。
关键创新:Aurora的关键创新在于其神经符号融合架构,它将LLM的自然语言处理能力与符号推理的精确性相结合。与纯粹依赖LLM的方法相比,Aurora能够更好地保证建议的准确性和合规性。此外,Aurora采用BCNF目录模式,确保课程数据的规范化和一致性,避免了数据冗余和不一致问题。
关键设计:Aurora使用Boyce-Codd Normal Form (BCNF) 来设计课程数据库,确保数据的一致性和避免冗余。Prolog引擎使用预定义的规则集来执行学分和先修课程的检查。LLM通过指令微调来优化其生成建议和解释的能力。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
Aurora在结构化评估套件中表现出色,语义对齐度从原始LLM的0.68提升到0.93(+36%)。在近一半的范围内案例中,Aurora实现了完美的精确率和召回率。此外,Aurora在通用硬件上实现了亚秒级的平均延迟(0.71秒),比原始LLM快约83倍,证明了其高效性。
🎯 应用场景
Aurora可应用于高校学业指导、职业规划、在线教育等领域。它可以为学生提供个性化的选课建议、学习路径规划和职业发展指导,帮助学生更好地实现学业目标和职业目标。此外,Aurora还可以减轻人工咨询的压力,提高咨询效率,降低咨询成本,促进教育公平。
📄 摘要(原文)
Academic advising in higher education is under severe strain, with advisor-to-student ratios commonly exceeding 300:1. These structural bottlenecks limit timely access to guidance, increase the risk of delayed graduation, and contribute to inequities in student support. We introduce Aurora, a modular neuro-symbolic advising agent that unifies retrieval-augmented generation (RAG), symbolic reasoning, and normalized curricular databases to deliver policy-compliant, verifiable recommendations at scale. Aurora integrates three components: (i) a Boyce-Codd Normal Form (BCNF) catalog schema for consistent program rules, (ii) a Prolog engine for prerequisite and credit enforcement, and (iii) an instruction-tuned large language model for natural-language explanations of its recommendations. To assess performance, we design a structured evaluation suite spanning common and edge-case advising scenarios, including short-term scheduling, long-term roadmapping, skill-aligned pathways, and out-of-scope requests. Across this diverse set, Aurora improves semantic alignment with expert-crafted answers from 0.68 (Raw LLM baseline) to 0.93 (+36%), achieves perfect precision and recall in nearly half of in-scope cases, and consistently produces correct fallbacks for unanswerable prompts. On commodity hardware, Aurora delivers sub-second mean latency (0.71s across 20 queries), approximately 83X faster than a Raw LLM baseline (59.2s). By combining symbolic rigor with neural fluency, Aurora advances a paradigm for accurate, explainable, and scalable AI-driven advising.