ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
作者: Hongjue Zhao, Haosen Sun, Jiangtao Kong, Xiaochang Li, Qineng Wang, Liwei Jiang, Qi Zhu, Tarek Abdelzaher, Yejin Choi, Manling Li, Huajie Shao
分类: cs.AI
发布日期: 2026-02-19
备注: Accepted by ICLR 2026
💡 一句话要点
ODESteer:基于ODE的统一框架,用于大语言模型对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型对齐 激活引导 常微分方程 势垒函数 表示工程
📋 核心要点
- 现有激活引导方法缺乏统一理论框架,难以指导引导方向设计,且过度依赖单步引导,无法捕捉复杂激活模式。
- 论文提出基于常微分方程(ODE)的统一理论框架,将激活引导视为ODE求解,并利用势垒函数设计引导方向。
- 提出的ODESteer方法在多个LLM对齐基准上取得了显著提升,例如TruthfulQA提升5.7%,验证了理论框架的有效性。
📝 摘要(中文)
激活引导(或表示工程)提供了一种轻量级的方法,通过在推理时操纵大型语言模型(LLM)的内部激活来实现模型对齐。然而,当前的方法存在两个主要局限性:(i)缺乏统一的理论框架来指导引导方向的设计,以及(ii)过度依赖于“单步引导”,无法捕捉激活分布的复杂模式。本文提出了一个统一的基于常微分方程(ODE)的理论框架,用于LLM对齐中的激活引导。我们证明了传统的激活添加可以解释为ODE解的一阶近似。基于这种ODE视角,识别引导方向等同于设计控制理论中的“势垒函数”。从这个框架出发,我们引入了ODESteer,一种由势垒函数引导的基于ODE的引导方法,它在LLM对齐方面表现出经验性的进步。ODESteer通过将势垒函数定义为正激活和负激活之间的对数密度比来识别引导方向,并利用它来构建用于多步和自适应引导的ODE。与最先进的激活引导方法相比,ODESteer在各种LLM对齐基准上实现了持续的经验改进,在TruthfulQA上显著提高了5.7%,在UltraFeedback上提高了2.5%,在RealToxicityPrompts上提高了2.4%。我们的工作通过ODE统一了激活引导的理论基础,并经验性地通过提出的ODESteer方法验证了它,从而为LLM对齐中的激活引导建立了一个有原则的新视角。
🔬 方法详解
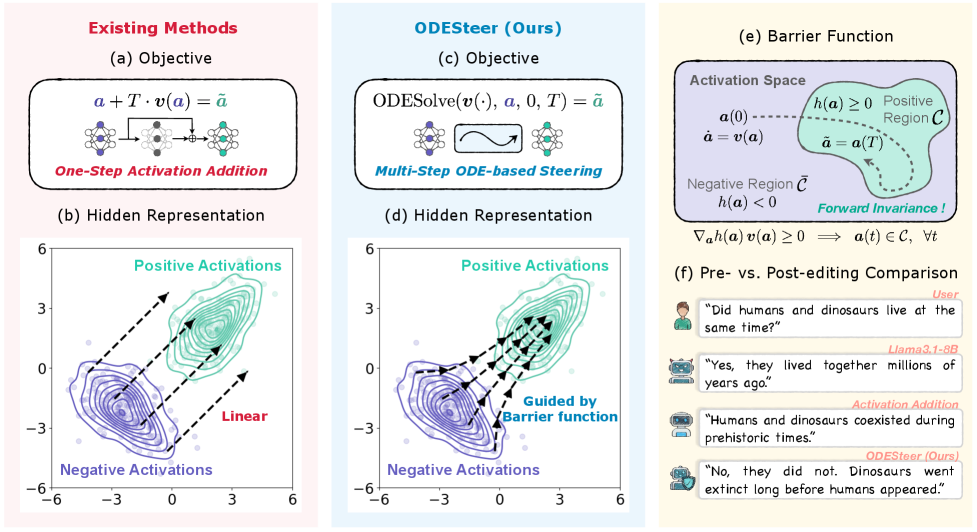
问题定义:现有激活引导方法在大型语言模型对齐方面存在局限性。缺乏统一的理论基础来指导激活方向的设计,导致启发式方法难以优化。此外,现有方法通常采用单步激活引导,无法充分利用激活分布的复杂模式,限制了对齐效果。
核心思路:论文的核心思路是将激活引导过程建模为常微分方程(ODE)的求解过程。通过这种方式,可以将激活引导问题转化为控制理论中的势垒函数设计问题。选择合适的势垒函数可以引导模型朝着期望的行为方向演化,从而实现更有效的模型对齐。
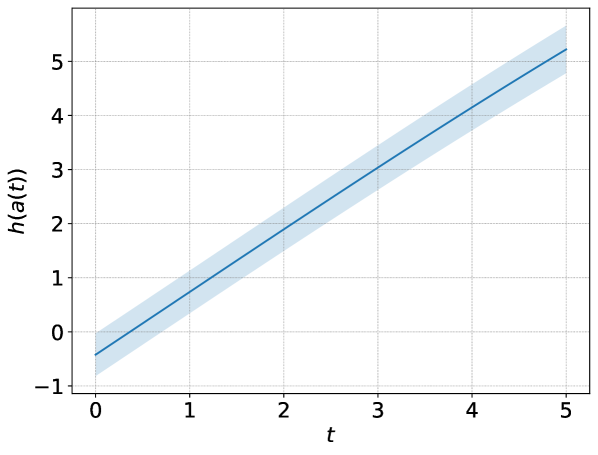
技术框架:ODESteer框架主要包含以下几个阶段:1) 定义势垒函数:基于正负激活的对数密度比来定义势垒函数,该函数能够区分期望行为和非期望行为。2) 构建ODE:利用定义的势垒函数构建ODE,该ODE描述了激活随时间的变化。3) 多步自适应引导:通过求解ODE,实现多步激活引导,并根据模型状态自适应地调整引导强度。
关键创新:论文最重要的创新在于将激活引导问题与常微分方程联系起来,从而建立了一个统一的理论框架。这种基于ODE的视角为激活引导方向的设计提供了理论指导,并允许采用多步和自适应的引导策略。与现有方法相比,ODESteer不再依赖于启发式方法或单步引导,而是基于严格的数学模型进行优化。
关键设计:ODESteer的关键设计包括:1) 势垒函数的选择:使用正负激活的对数密度比作为势垒函数,能够有效地捕捉期望行为和非期望行为之间的差异。2) ODE求解器的选择:选择合适的ODE求解器(例如Runge-Kutta方法)来保证求解的精度和效率。3) 自适应引导强度的调整:根据模型的状态动态调整引导强度,避免过度干预或引导不足。
🖼️ 关键图片
📊 实验亮点
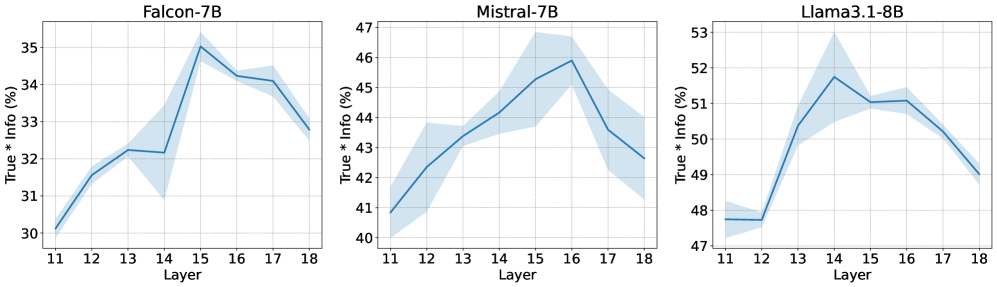
ODESteer在多个LLM对齐基准上取得了显著的性能提升。在TruthfulQA上,ODESteer相比现有最佳方法提升了5.7%;在UltraFeedback上提升了2.5%;在RealToxicityPrompts上降低了2.4%的毒性。这些结果表明,ODESteer能够有效地提高LLM的真实性、安全性和对齐性。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种场景下的安全性、可靠性和道德性。例如,可以用于减少模型生成有害内容、提高模型的事实准确性、以及增强模型的公平性。此外,该方法还可以应用于个性化语言模型,根据用户的偏好和需求调整模型的行为。
📄 摘要(原文)
Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.