Evaluating Chain-of-Thought Reasoning through Reusability and Verifiability
作者: Shashank Aggarwal, Ram Vikas Mishra, Amit Awekar
分类: cs.AI, cs.CL, cs.IR
发布日期: 2026-02-19
💡 一句话要点
提出可复用性和可验证性指标,评估CoT推理质量,揭示现有评估盲点
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 可复用性 可验证性 LLM评估 多智能体系统
📋 核心要点
- 现有CoT评估仅关注最终任务准确率,忽略了推理过程本身的质量和实用性,存在评估盲点。
- 提出可复用性和可验证性指标,通过Thinker-Executor框架解耦CoT生成与执行,分别衡量CoT的易用性和正确性。
- 实验表明,可复用性和可验证性与准确率不相关,且专用推理模型的CoT并不一定优于通用LLM。
📝 摘要(中文)
在多智能体信息检索流程中,基于LLM的智能体之间通过思维链(CoT)交换中间推理过程。目前CoT的评估主要集中在目标任务的准确性上,但这种指标无法评估推理过程本身的质量或效用。为了解决这一局限性,我们引入了两个新的度量标准:可复用性和可验证性。我们使用Thinker-Executor框架将CoT的生成与执行分离。可复用性衡量Executor复用Thinker的CoT的容易程度。可验证性衡量Executor使用CoT匹配Thinker答案的频率。我们针对五个基准测试,评估了四个Thinker模型和十个Executor模型。结果表明,可复用性和可验证性与标准准确性不相关,揭示了当前基于准确性的推理能力排行榜的盲点。令人惊讶的是,我们发现来自专门推理模型的CoT并不总是比来自通用LLM(如Llama和Gemma)的CoT更具可复用性或可验证性。
🔬 方法详解
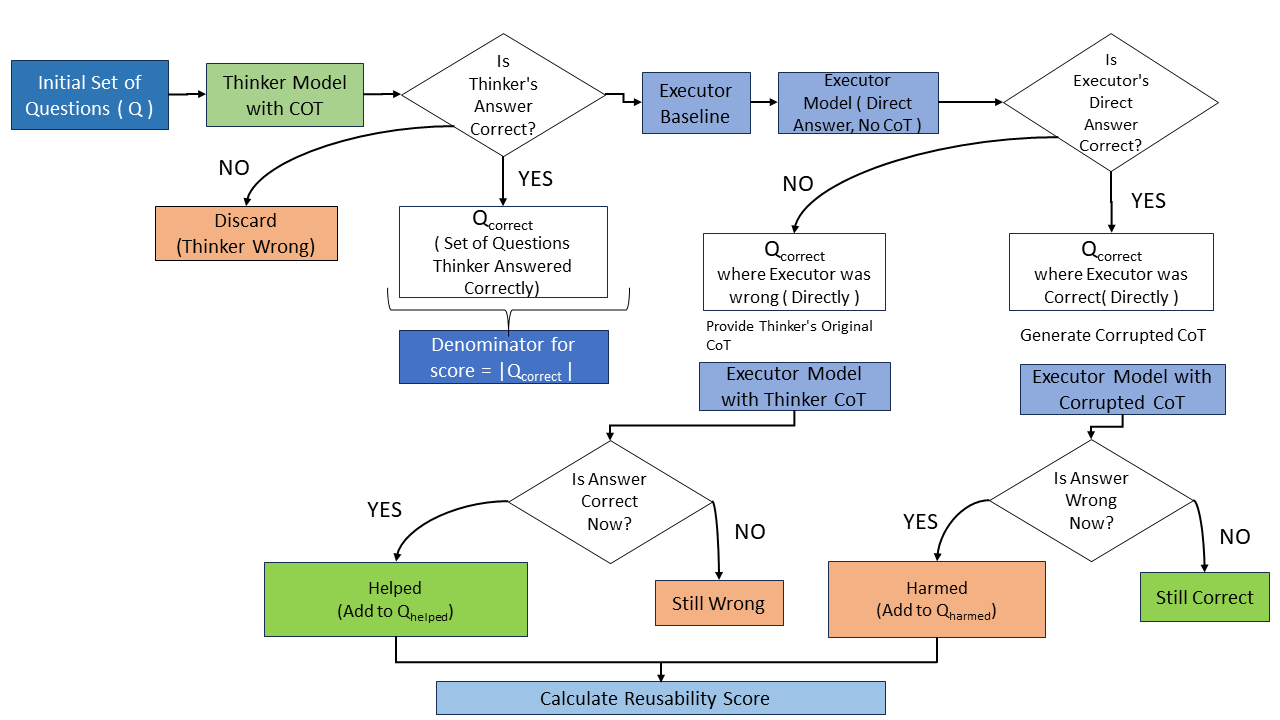
问题定义:现有CoT评估方法主要依赖于最终任务的准确率,无法有效衡量CoT推理过程本身的质量,例如推理步骤是否清晰、易于理解和复用。这种评估方式忽略了CoT作为中间推理过程的内在价值,阻碍了CoT推理能力的深入研究和提升。
核心思路:论文的核心思路是将CoT的生成(Thinker)和执行(Executor)解耦,并引入可复用性和可验证性两个指标来评估CoT的质量。可复用性衡量Executor能否容易地理解和利用Thinker生成的CoT,可验证性衡量Executor能否通过CoT验证Thinker的答案。通过这两个指标,可以更全面地评估CoT的质量,并发现现有评估方法无法捕捉到的信息。
技术框架:论文采用Thinker-Executor框架。Thinker负责生成CoT推理过程和最终答案,Executor负责利用Thinker生成的CoT来推导答案。通过比较Executor的答案和Thinker的答案,可以评估CoT的可验证性。通过分析Executor使用CoT的难易程度,可以评估CoT的可复用性。实验中,使用了多个Thinker模型和Executor模型,并在多个基准数据集上进行了评估。
关键创新:论文的关键创新在于提出了可复用性和可验证性这两个新的CoT评估指标。这两个指标弥补了现有基于准确率的评估方法的不足,能够更全面地评估CoT的质量。此外,论文还通过实验揭示了现有评估方法的一个盲点,即CoT的准确率并不一定与其可复用性和可验证性相关。
关键设计:可复用性的评估方法是(具体评估方法未知,论文中未详细说明)。可验证性的评估方法是比较Executor使用CoT得到的答案与Thinker的答案,计算两者一致的比例。实验中,使用了四个Thinker模型(具体模型未知)和十个Executor模型(具体模型未知),并在五个基准数据集(具体数据集未知)上进行了评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,可复用性和可验证性与标准准确性不相关,揭示了当前基于准确性的推理能力排行榜的盲点。令人惊讶的是,来自专门推理模型的CoT并不总是比来自通用LLM(如Llama和Gemma)的CoT更具可复用性或可验证性。这些发现挑战了现有CoT评估的认知,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于多智能体协作、问答系统、知识图谱推理等领域。通过可复用性和可验证性指标,可以更好地评估和优化CoT推理过程,提升智能体的推理能力和协作效率。未来,可以进一步研究如何生成更具可复用性和可验证性的CoT,从而提高LLM在复杂任务中的表现。
📄 摘要(原文)
In multi-agent IR pipelines for tasks such as search and ranking, LLM-based agents exchange intermediate reasoning in terms of Chain-of-Thought (CoT) with each other. Current CoT evaluation narrowly focuses on target task accuracy. However, this metric fails to assess the quality or utility of the reasoning process itself. To address this limitation, we introduce two novel measures: reusability and verifiability. We decouple CoT generation from execution using a Thinker-Executor framework. Reusability measures how easily an Executor can reuse the Thinker's CoT. Verifiability measures how frequently an Executor can match the Thinker's answer using the CoT. We evaluated four Thinker models against a committee of ten Executor models across five benchmarks. Our results reveal that reusability and verifiability do not correlate with standard accuracy, exposing a blind spot in current accuracy-based leaderboards for reasoning capability. Surprisingly, we find that CoTs from specialized reasoning models are not consistently more reusable or verifiable than those from general-purpose LLMs like Llama and Gemma.