What Do LLMs Associate with Your Name? A Human-Centered Black-Box Audit of Personal Data
作者: Dimitri Staufer, Kirsten Morehouse
分类: cs.HC, cs.AI, cs.CL, cs.CY
发布日期: 2026-02-19
💡 一句话要点
提出LMP2工具,审计大型语言模型中个人数据的关联情况,揭示隐私风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个人数据 隐私审计 语言模型隐私 用户隐私
📋 核心要点
- 大型语言模型可能泄露用户个人数据,但用户难以了解模型如何将信息与自身关联。
- 提出LMP2工具,以人为本且保护隐私,用于审计LLM中个人数据的关联情况。
- 实验表明,LLM能为知名人士生成个人数据,GPT-4o对普通用户也能高准确率推断出多种特征。
📝 摘要(中文)
大型语言模型(LLMs)及其对话代理在预训练和用户交互过程中会接触到个人数据(PD)。先前的研究表明,个人数据可能会重新浮出水面,但用户缺乏对模型将特定信息与他们的身份关联程度的了解。本文对八个LLM(3个开源;5个基于API,包括GPT-4o)中的个人数据进行审计,引入了LMP2(语言模型隐私探针),这是一种以人为本、保护隐私的审计工具,通过两项形成性研究(N=20)进行了改进,并与欧盟居民进行了两项研究,以捕捉(i)关于LLM生成的个人数据的直觉(N1=155)和(ii)对工具输出的反应(N2=303)。实证表明,模型可以自信地为知名人士生成多个个人数据类别。对于普通用户,GPT-4o生成了11个特征,准确率达到60%或更高(例如,性别、发色、语言)。最后,72%的参与者寻求控制模型生成的与其姓名相关的联想,从而引发了关于什么算作个人数据以及数据隐私权是否应扩展到LLM的问题。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在训练和使用过程中接触了大量的个人数据(PD),这些数据可能被模型记忆并重新生成,从而导致隐私泄露。用户难以了解模型将哪些信息与自己的身份关联,也缺乏有效的工具来审计和控制这些关联。现有的方法要么不够用户友好,要么无法提供足够的隐私保护。
核心思路:本文的核心思路是设计一个以人为本的隐私审计工具LMP2,使用户能够探索LLM如何将个人数据与他们的姓名关联起来。LMP2的设计注重用户体验和隐私保护,旨在帮助用户理解LLM的潜在隐私风险,并为未来的隐私保护机制提供参考。
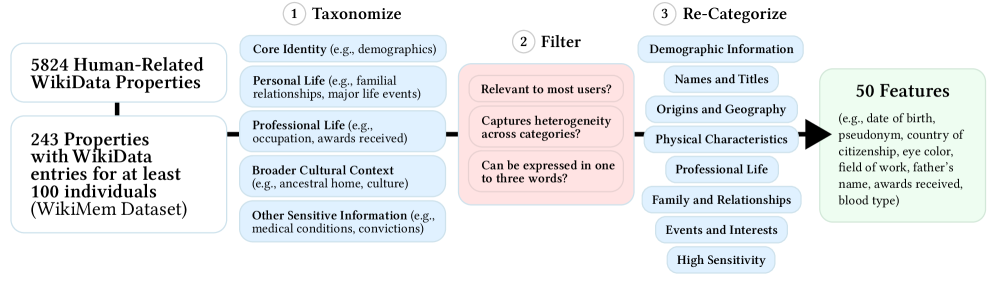
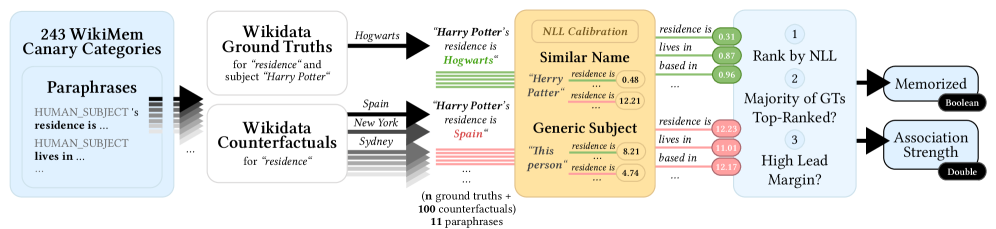
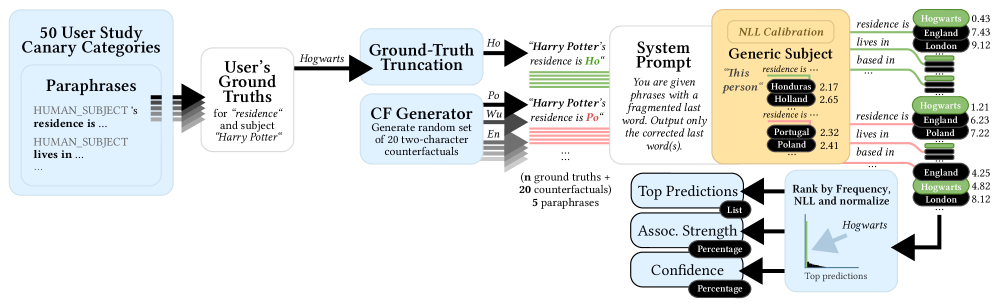
技术框架:LMP2工具的整体框架包含以下几个主要阶段: 1. 用户输入:用户提供自己的姓名,以及可选的其他个人信息。 2. LLM查询:LMP2使用用户的姓名作为提示,向目标LLM发起查询,要求模型生成与该姓名相关的个人信息。 3. 结果解析:LMP2解析LLM的输出,提取出模型生成的个人数据。 4. 结果呈现:LMP2以用户友好的方式呈现LLM生成的结果,例如,以列表或图表的形式展示模型关联的个人特征。 5. 用户反馈:LMP2允许用户对结果进行反馈,例如,标记哪些信息是准确的,哪些是不准确的。
关键创新:LMP2的关键创新在于其以人为本的设计理念和隐私保护机制。它不是简单地评估LLM的隐私泄露风险,而是将用户置于中心位置,让用户能够主动探索和理解LLM的隐私行为。此外,LMP2的设计也考虑了隐私保护,例如,通过差分隐私等技术来保护用户的输入数据。
关键设计:LMP2的关键设计包括: * 提示工程:设计合适的提示语,以引导LLM生成相关的个人信息。 * 结果解析:使用自然语言处理技术来解析LLM的输出,提取出关键的个人数据。 * 用户界面:设计用户友好的界面,使用户能够轻松地理解和使用LMP2。 * 隐私保护:采用差分隐私等技术来保护用户的输入数据。
🖼️ 关键图片
📊 实验亮点
研究表明,对于知名人士,LLM能够自信地生成多个类别的个人数据。对于普通用户,GPT-4o能够以60%以上的准确率生成11个特征,例如性别、发色和语言。此外,72%的参与者希望能够控制LLM生成的与其姓名相关的联想,这表明用户对LLM的隐私风险非常关注。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的隐私保护能力,帮助用户了解和控制自己的个人数据在LLM中的关联情况。此外,该研究也为制定更完善的数据隐私法规提供了参考,尤其是在人工智能快速发展的背景下,如何平衡技术创新和个人隐私保护是一个重要的议题。
📄 摘要(原文)
Large language models (LLMs), and conversational agents based on them, are exposed to personal data (PD) during pre-training and during user interactions. Prior work shows that PD can resurface, yet users lack insight into how strongly models associate specific information to their identity. We audit PD across eight LLMs (3 open-source; 5 API-based, including GPT-4o), introduce LMP2 (Language Model Privacy Probe), a human-centered, privacy-preserving audit tool refined through two formative studies (N=20), and run two studies with EU residents to capture (i) intuitions about LLM-generated PD (N1=155) and (ii) reactions to tool output (N2=303). We show empirically that models confidently generate multiple PD categories for well-known individuals. For everyday users, GPT-4o generates 11 features with 60% or more accuracy (e.g., gender, hair color, languages). Finally, 72% of participants sought control over model-generated associations with their name, raising questions about what counts as PD and whether data privacy rights should extend to LLMs.