Improving LLM-based Recommendation with Self-Hard Negatives from Intermediate Layers
作者: Bingqian Li, Bowen Zheng, Xiaolei Wang, Long Zhang, Jinpeng Wang, Sheng Chen, Wayne Xin Zhao, Ji-rong Wen
分类: cs.IR, cs.AI
发布日期: 2026-02-19
💡 一句话要点
提出ILRec框架,利用中间层自挖掘负样本提升LLM推荐性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推荐 负样本挖掘 偏好学习 中间层表征 自监督学习
📋 核心要点
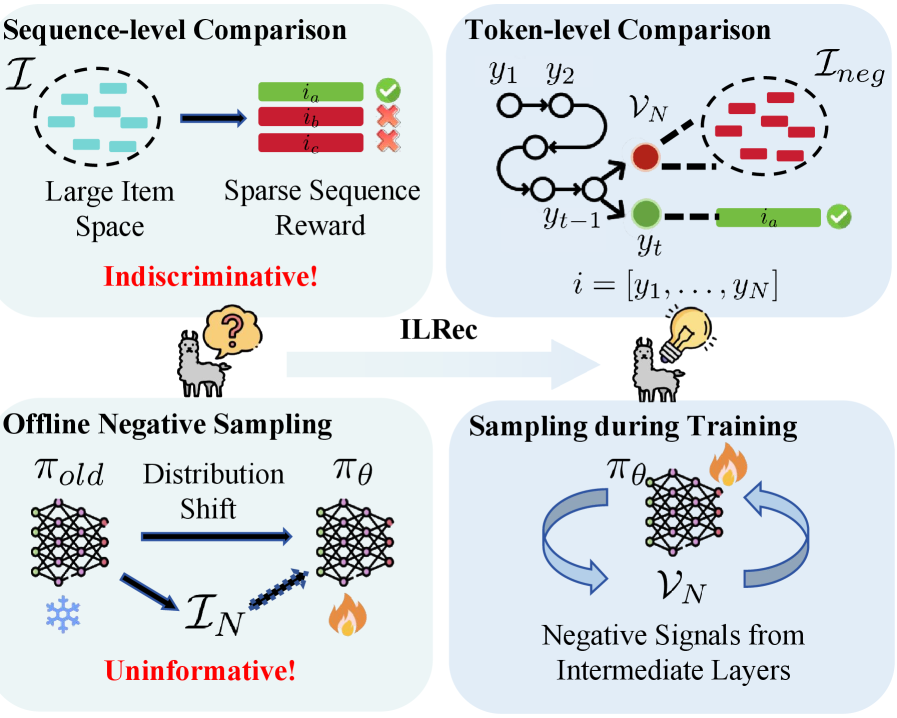
- 现有LLM推荐方法依赖序列级离线负样本,区分性和信息量不足,难以适应大规模负样本空间。
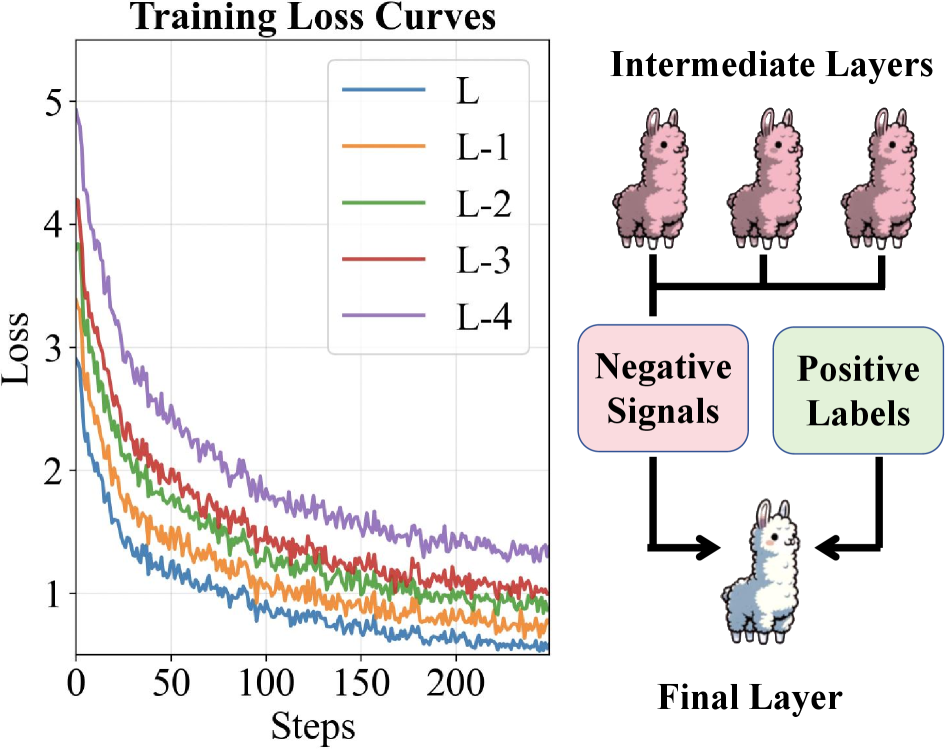
- ILRec框架从LLM中间层提取自挖掘困难负样本,作为细粒度负监督信号,动态反映偏好学习过程。
- 实验表明,ILRec在三个数据集上显著提升了LLM推荐系统的性能,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)在推荐系统中展现出巨大潜力,其中监督微调(SFT)是常用的适配方法。后续研究进一步引入偏好学习,将负样本纳入训练过程。然而,现有方法依赖于序列级别的、离线生成的负样本,当LLM适应于具有大量负样本空间的推荐任务时,这些负样本的区分性和信息量不足。为了解决这些挑战,我们提出ILRec,一种新颖的基于LLM推荐的偏好微调框架,利用从中间层提取的自挖掘困难负样本信号来改进偏好学习。具体而言,我们将中间层的自挖掘困难负样本token识别为细粒度的负监督,动态反映模型的偏好学习过程。为了有效地将这些信号集成到训练中,我们设计了一个包含跨层偏好优化和跨层偏好蒸馏的两阶段框架,使模型能够共同区分信息丰富的负样本并增强来自中间层的负样本信号的质量。此外,我们引入了一个轻量级的协同过滤模型来为负样本信号分配token级别的奖励,从而减轻过度惩罚假阴性的风险。在三个数据集上的大量实验证明了ILRec在增强基于LLM的推荐系统的性能方面的有效性。
🔬 方法详解
问题定义:现有基于LLM的推荐系统,在进行偏好学习时,通常采用序列级别的、离线生成的负样本。这种方式生成的负样本区分度不高,信息量不足,尤其是在面对大规模负样本空间时,会严重影响模型的学习效果。现有方法难以充分利用模型自身在学习过程中产生的负样本信息,导致模型性能受限。
核心思路:ILRec的核心思路是从LLM的中间层提取自挖掘的困难负样本(self-hard negatives),并将其作为细粒度的负监督信号,用于提升模型的偏好学习能力。通过动态地利用模型自身产生的负样本信息,可以更有效地训练模型区分正负样本,从而提高推荐性能。
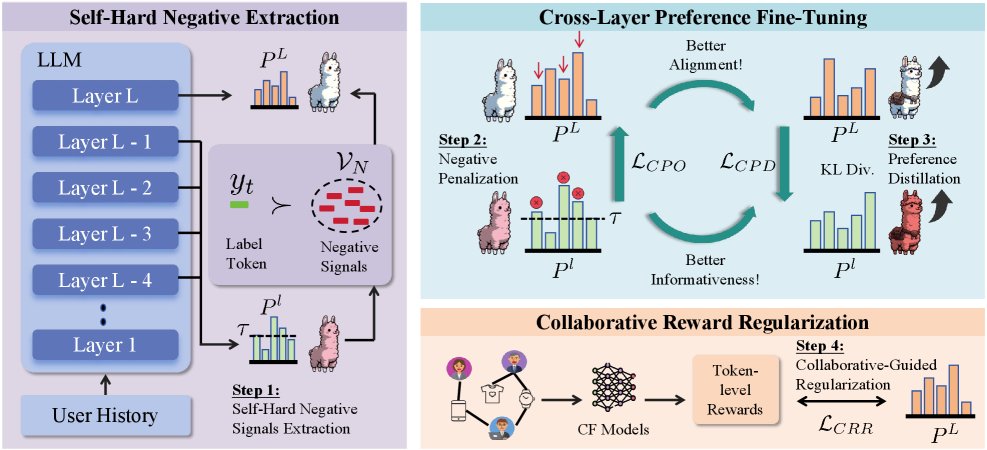
技术框架:ILRec采用两阶段训练框架:跨层偏好优化(Cross-Layer Preference Optimization)和跨层偏好蒸馏(Cross-Layer Preference Distillation)。在跨层偏好优化阶段,模型利用从中间层提取的负样本信号进行训练,目标是区分信息丰富的负样本。在跨层偏好蒸馏阶段,模型学习增强来自中间层的负样本信号的质量,提升负样本的有效性。
关键创新:ILRec的关键创新在于利用LLM中间层的表征作为负样本挖掘的来源。与传统的离线生成负样本方法相比,这种方法能够动态地捕捉模型在学习过程中产生的负样本信息,从而提供更具区分性和信息量的负监督信号。此外,引入token级别的奖励机制,缓解了过度惩罚假阴性的问题。
关键设计:ILRec使用一个轻量级的协同过滤模型来为负样本信号分配token级别的奖励。这个协同过滤模型基于用户-物品交互历史,用于评估每个token作为负样本的可靠性。奖励机制的设计旨在降低假阴性样本对模型训练的负面影响。损失函数的设计结合了交叉熵损失和token级别的奖励,以平衡正负样本的贡献。
🖼️ 关键图片
📊 实验亮点
在三个数据集上的实验结果表明,ILRec显著提升了LLM推荐系统的性能。例如,在某个数据集上,ILRec相比于基线方法提升了超过5%。实验结果验证了从中间层提取自挖掘负样本的有效性,以及两阶段训练框架的优势。
🎯 应用场景
ILRec框架可应用于各种基于LLM的推荐系统,尤其是在具有大规模负样本空间的场景下,如电商推荐、新闻推荐、视频推荐等。该研究有助于提升推荐系统的准确性和个性化程度,改善用户体验,并为LLM在推荐领域的应用提供新的思路。
📄 摘要(原文)
Large language models (LLMs) have shown great promise in recommender systems, where supervised fine-tuning (SFT) is commonly used for adaptation. Subsequent studies further introduce preference learning to incorporate negative samples into the training process. However, existing methods rely on sequence-level, offline-generated negatives, making them less discriminative and informative when adapting LLMs to recommendation tasks with large negative item spaces. To address these challenges, we propose ILRec, a novel preference fine-tuning framework for LLM-based recommendation, leveraging self-hard negative signals extracted from intermediate layers to improve preference learning. Specifically, we identify self-hard negative tokens from intermediate layers as fine-grained negative supervision that dynamically reflects the model's preference learning process. To effectively integrate these signals into training, we design a two-stage framework comprising cross-layer preference optimization and cross-layer preference distillation, enabling the model to jointly discriminate informative negatives and enhance the quality of negative signals from intermediate layers. In addition, we introduce a lightweight collaborative filtering model to assign token-level rewards for negative signals, mitigating the risk of over-penalizing false negatives. Extensive experiments on three datasets demonstrate ILRec's effectiveness in enhancing the performance of LLM-based recommender systems.