Visual Model Checking: Graph-Based Inference of Visual Routines for Image Retrieval
作者: Adrià Molina, Oriol Ramos Terrades, Josep Lladós
分类: cs.AI, cs.IR
发布日期: 2026-02-19
备注: Submitted for ICPR Review
💡 一句话要点
提出一种基于图推理视觉程序的图像检索方法,结合形式验证与深度学习。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 图像检索 形式验证 图推理 视觉程序 自然语言查询
📋 核心要点
- 现有图像检索方法在处理涉及复杂关系、对象组合或精确约束的自然语言查询时存在不足。
- 该论文提出一种新框架,结合图验证和神经代码生成,将形式验证融入深度学习图像检索,提升检索结果的可信度和可验证性。
- 该方法通过验证查询中的每个原子真值,不仅返回匹配结果,还能识别满足和未满足的约束,提升检索透明度。
📝 摘要(中文)
信息检索是现代数字产业的基石。尽管近年来基于嵌入的模型和大规模预训练推动了自然语言搜索的显著进步,但该领域仍面临重大挑战。具体而言,涉及复杂关系、对象组合或精确约束(如身份、计数和比例)的查询在当前框架中通常仍未解决或不可靠。本文提出了一种新颖的框架,通过基于图的验证方法和神经代码生成协同结合,将形式验证集成到基于深度学习的图像检索中。我们的方法旨在支持开放词汇自然语言查询,同时产生可信且可验证的结果。通过将检索结果置于形式推理系统中,我们超越了向量表示中常见的模糊性和近似性。我们的框架明确地针对检索到的内容验证用户查询中的每个原子真值,而不是接受不确定性。这使我们不仅可以返回匹配的结果,还可以识别和标记哪些特定约束得到满足,哪些仍未满足,从而提供更透明和负责任的检索过程,同时提升最流行的基于嵌入的方法的结果。
🔬 方法详解
问题定义:现有图像检索方法,特别是基于嵌入的方法,在处理涉及复杂关系、对象组合以及精确约束(如身份、计数、比例等)的自然语言查询时,表现出不足或不可靠。这些方法难以准确捕捉和推理查询中蕴含的复杂语义关系,导致检索结果不尽如人意。现有方法通常依赖于向量表示的相似度匹配,而忽略了对查询语句的精确逻辑验证。
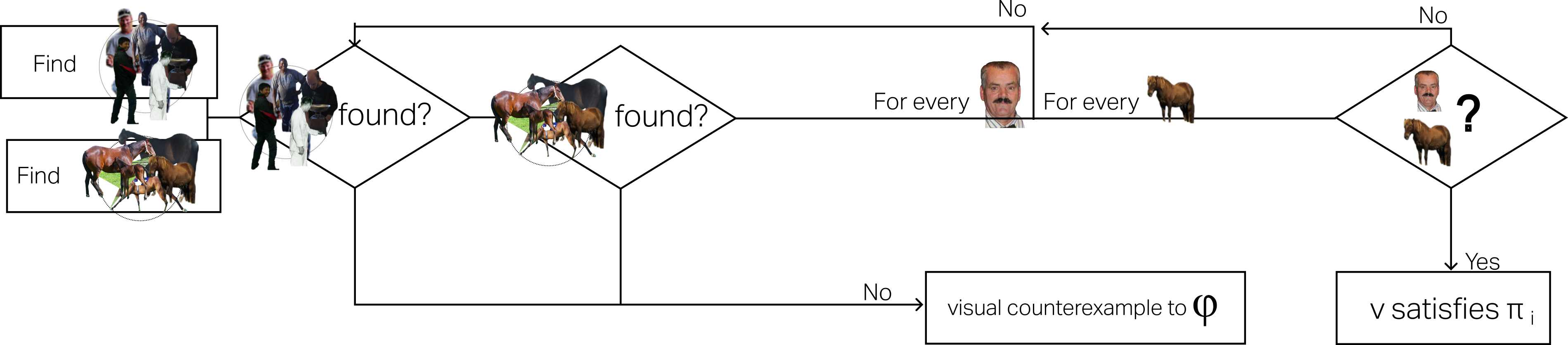
核心思路:该论文的核心思路是将形式验证的概念引入到图像检索任务中。通过将自然语言查询转化为可验证的图结构,并设计相应的视觉程序来验证图像内容是否满足查询约束,从而实现更精确、可信的图像检索。这种方法的核心在于将模糊的向量相似度匹配转化为明确的逻辑真值判断。
技术框架:该框架主要包含以下几个模块:1) 自然语言查询解析模块:将自然语言查询解析为形式化的图结构,节点表示对象或属性,边表示关系。2) 视觉程序生成模块:基于查询图,生成相应的视觉程序,该程序定义了验证图像内容是否满足查询约束的步骤。3) 图像内容提取模块:从图像中提取相关的视觉信息,例如对象检测、属性识别等。4) 形式验证模块:执行视觉程序,验证提取的视觉信息是否满足查询图定义的约束。5) 结果排序与呈现模块:根据验证结果对检索到的图像进行排序,并呈现满足查询约束的图像,同时标记哪些约束得到满足,哪些未满足。
关键创新:该论文最重要的创新在于将形式验证的思想引入到图像检索任务中,通过构建基于图的视觉程序来验证图像内容是否满足查询约束。与传统的基于嵌入的方法相比,该方法能够更精确地捕捉和推理查询中蕴含的复杂语义关系,并提供可验证的检索结果。此外,该方法还能够识别和标记哪些约束得到满足,哪些未满足,从而提供更透明和负责任的检索过程。
关键设计:论文中关键的设计包括:1) 查询图的构建方式,如何将自然语言查询转化为形式化的图结构。2) 视觉程序的生成算法,如何根据查询图自动生成相应的视觉程序。3) 形式验证模块的实现细节,如何高效地执行视觉程序并验证图像内容是否满足查询约束。4) 如何将形式验证的结果与传统的基于嵌入的方法相结合,以进一步提升检索性能。具体的参数设置、损失函数、网络结构等技术细节在摘要中未提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
摘要中未提供具体的实验数据和对比结果,因此无法总结实验亮点。但论文强调该方法能够提升最流行的基于嵌入的方法的结果,并提供更透明和负责任的检索过程。具体提升幅度未知。
🎯 应用场景
该研究成果可应用于智能搜索引擎、图像内容审核、视觉问答系统等领域。通过提供更精确、可信和可解释的图像检索结果,该方法能够提升用户体验,增强系统的可靠性,并为未来的图像检索技术发展提供新的思路。
📄 摘要(原文)
Information retrieval lies at the foundation of the modern digital industry. While natural language search has seen dramatic progress in recent years largely driven by embedding-based models and large-scale pretraining, the field still faces significant challenges. Specifically, queries that involve complex relationships, object compositions, or precise constraints such as identities, counts and proportions often remain unresolved or unreliable within current frameworks. In this paper, we propose a novel framework that integrates formal verification into deep learning-based image retrieval through a synergistic combination of graph-based verification methods and neural code generation. Our approach aims to support open-vocabulary natural language queries while producing results that are both trustworthy and verifiable. By grounding retrieval results in a system of formal reasoning, we move beyond the ambiguity and approximation that often characterize vector representations. Instead of accepting uncertainty as a given, our framework explicitly verifies each atomic truth in the user query against the retrieved content. This allows us to not only return matching results, but also to identify and mark which specific constraints are satisfied and which remain unmet, thereby offering a more transparent and accountable retrieval process while boosting the results of the most popular embedding-based approaches.