Dataless Weight Disentanglement in Task Arithmetic via Kronecker-Factored Approximate Curvature
作者: Angelo Porrello, Pietro Buzzega, Felix Dangel, Thomas Sommariva, Riccardo Salami, Lorenzo Bonicelli, Simone Calderara
分类: cs.AI
发布日期: 2026-02-19
备注: Accepted to ICLR 2026
💡 一句话要点
提出基于K-FAC的无数据权重解耦方法,解决任务算术中的跨任务干扰问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务算术 权重解耦 无数据学习 K-FAC 表征漂移 曲率矩阵 模型正则化
📋 核心要点
- 现有任务算术方法在组合多个任务向量时,容易产生跨任务干扰,导致表征漂移和性能下降。
- 论文提出一种无数据权重解耦方法,通过将表征漂移正则化转化为曲率矩阵近似问题来解决跨任务干扰。
- 该方法利用Kronecker分解近似曲率(K-FAC)构建正则化器,在任务加法和否定任务上取得了SOTA结果。
📝 摘要(中文)
任务算术提供了一种模块化、可扩展的方式来调整基础模型。然而,组合多个任务向量可能导致跨任务干扰,从而引起表征漂移和性能下降。表征漂移正则化为解耦任务向量提供了一种自然的补救方法;然而,现有方法通常需要外部任务数据,这与模块化和数据可用性约束(例如,隐私要求)相冲突。我们提出了一种无数据方法,将针对表征漂移的正则化构建为曲率矩阵近似问题。这使我们能够利用成熟的技术;特别是,我们采用Kronecker分解近似曲率(K-FAC),并获得了一种实用的正则化器,在任务加法和否定方面取得了最先进的结果。我们的方法在任务数量上具有恒定的复杂度,并提高了对任务向量重新缩放的鲁棒性,从而消除了对预留调整的需要。
🔬 方法详解
问题定义:任务算术在组合多个任务向量时,会产生跨任务干扰,导致模型性能下降。现有的表征漂移正则化方法依赖于外部任务数据,这与模块化和数据隐私保护相悖。因此,如何在不使用额外数据的情况下,有效解耦任务向量,避免跨任务干扰,是本文要解决的核心问题。
核心思路:论文的核心思路是将表征漂移正则化问题转化为曲率矩阵近似问题。通过最小化任务向量组合后的模型参数与原始模型参数之间的表征漂移,可以实现任务向量的解耦。而表征漂移可以通过曲率矩阵来近似,从而避免直接使用数据进行计算。
技术框架:该方法主要包含以下几个步骤:1) 使用任务算术生成组合后的任务向量;2) 利用Kronecker分解近似曲率(K-FAC)计算曲率矩阵;3) 构建基于曲率矩阵的正则化项,用于约束组合后的模型参数;4) 使用优化算法更新模型参数,最小化正则化损失。
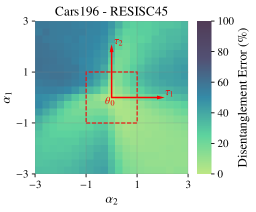
关键创新:该方法最大的创新在于提出了无数据权重解耦的方案。通过将表征漂移正则化转化为曲率矩阵近似问题,避免了对外部任务数据的依赖。此外,利用K-FAC技术,降低了计算复杂度,使得该方法可以应用于大规模模型。
关键设计:论文采用K-FAC来近似Hessian矩阵,并将其作为正则化项添加到损失函数中。具体来说,损失函数包含两部分:任务相关的损失和正则化损失。正则化损失旨在最小化组合后的模型参数与原始模型参数之间的表征漂移,其权重通过实验确定。此外,该方法对任务向量的缩放具有鲁棒性,无需额外的超参数调整。
🖼️ 关键图片
📊 实验亮点
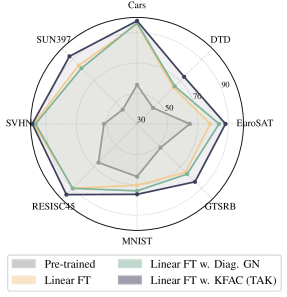
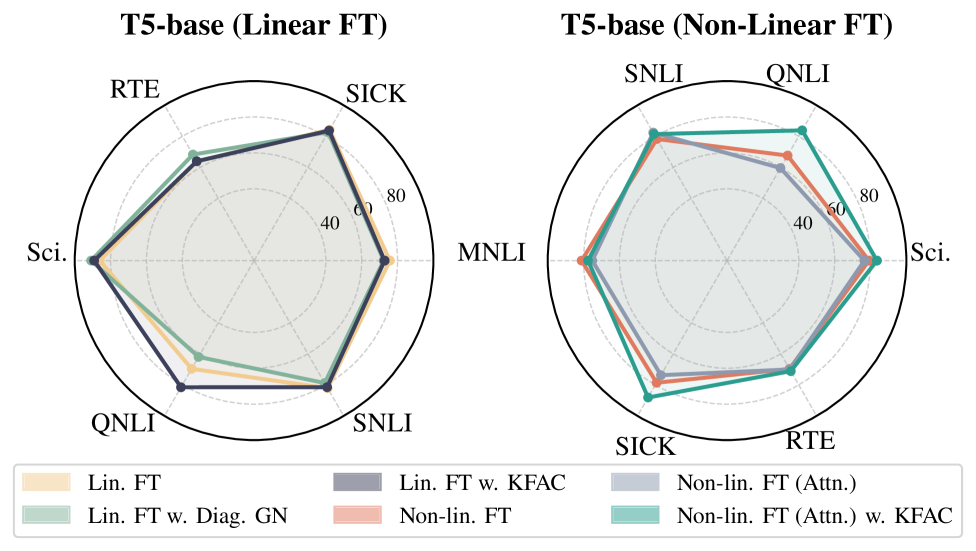
实验结果表明,该方法在任务加法和否定任务上取得了state-of-the-art的结果。与现有方法相比,该方法无需外部数据,且对任务向量的重新缩放具有鲁棒性。此外,该方法在任务数量上具有恒定的复杂度,使其适用于大规模任务组合。
🎯 应用场景
该研究成果可应用于联邦学习、持续学习等领域,在这些场景下,数据通常是分散的、隐私敏感的。通过无数据权重解耦,可以实现模型的个性化定制和任务的灵活组合,同时保护用户隐私。此外,该方法还可以用于提升模型的可解释性和鲁棒性。
📄 摘要(原文)
Task Arithmetic yields a modular, scalable way to adapt foundation models. Combining multiple task vectors, however, can lead to cross-task interference, causing representation drift and degraded performance. Representation drift regularization provides a natural remedy to disentangle task vectors; however, existing approaches typically require external task data, conflicting with modularity and data availability constraints (e.g., privacy requirements). We propose a dataless approach by framing regularization against representation drift as a curvature matrix approximation problem. This allows us to leverage well-established techniques; in particular, we adopt Kronecker-Factored Approximate Curvature and obtain a practical regularizer that achieves state-of-the-art results in task addition and negation. Our method has constant complexity in the number of tasks and promotes robustness to task vector rescaling, eliminating the need for held-out tuning.