Mechanistic Interpretability of Cognitive Complexity in LLMs via Linear Probing using Bloom's Taxonomy
作者: Bianca Raimondi, Maurizio Gabbrielli
分类: cs.AI, cs.CL
发布日期: 2026-02-19
备注: Preprint. Under review
💡 一句话要点
利用Bloom分类学线性探测LLM认知复杂度的机制可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 认知复杂度 Bloom分类学 线性探测 可解释性 神经表征 残差流
📋 核心要点
- 大型语言模型缺乏可解释性,难以理解其内部认知过程,阻碍了对其能力和局限性的深入评估。
- 该研究通过线性探测技术,分析LLM在处理不同认知复杂度的任务时,其内部表征的线性可分性,以此揭示模型如何编码认知难度。
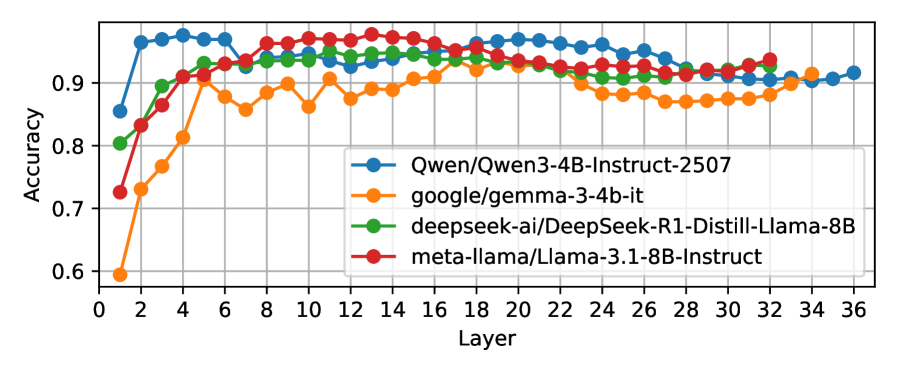
- 实验结果表明,LLM的内部表征在不同认知水平上具有高度的线性可分性,且这种可分性随着网络层数的加深而增强,验证了模型对认知复杂度的有效编码。
📝 摘要(中文)
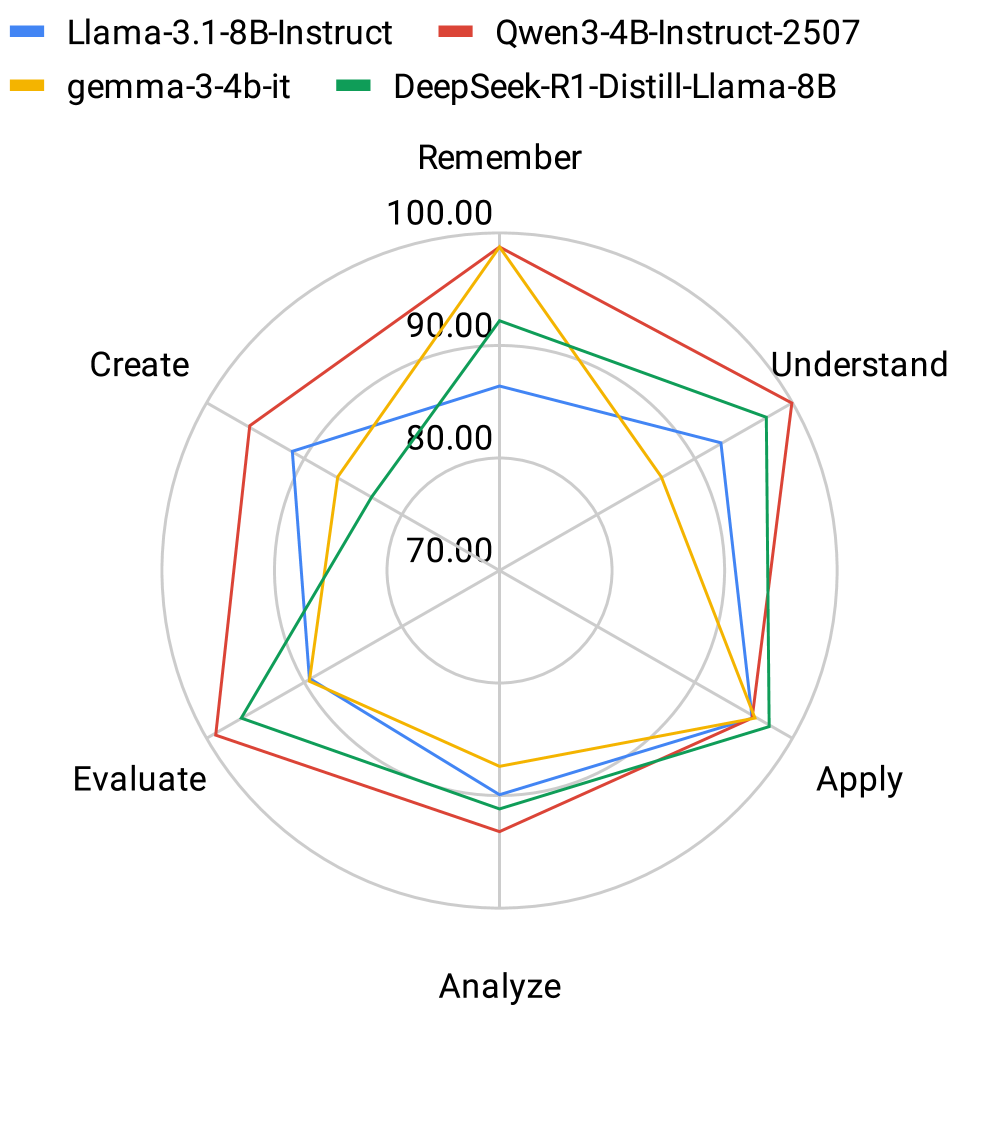
大型语言模型的黑盒特性需要超越表面性能指标的全新评估框架。本研究使用Bloom分类学作为分层视角,研究认知复杂度的内部神经表征。通过分析来自不同LLM的高维激活向量,我们探测不同的认知水平(从基本的记忆(Remember)到抽象的创造(Create))是否在模型的残差流中线性可分。结果表明,线性分类器在所有Bloom水平上实现了约95%的平均准确率,这有力地证明了认知水平被编码在模型表征的线性可访问子空间中。这些发现表明,模型在正向传递的早期就解决了提示的认知难度,并且表征在各层之间变得越来越可分离。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的认知复杂性如何在其内部表征中体现的问题。现有方法主要关注LLM的表面性能,缺乏对其内部认知机制的深入理解,难以解释模型如何处理不同认知难度的任务。因此,如何有效地评估和理解LLM的认知能力成为一个重要的研究挑战。
核心思路:论文的核心思路是利用Bloom分类学作为认知复杂度的分层标准,通过线性探测技术分析LLM在处理不同认知水平任务时的内部表征。具体来说,通过训练线性分类器来区分不同认知水平的激活向量,如果线性分类器能够达到较高的准确率,则表明LLM的内部表征中包含了可线性分离的认知信息。
技术框架:整体框架包括以下几个主要步骤:1) 选择LLM作为研究对象;2) 使用Bloom分类学定义不同的认知水平(例如,记忆、理解、应用、分析、综合、创造);3) 构建包含不同认知水平任务的提示数据集;4) 将提示输入LLM,提取不同层的激活向量;5) 使用激活向量训练线性分类器,用于区分不同的认知水平;6) 评估线性分类器的性能,分析LLM内部表征的认知复杂性编码情况。
关键创新:该研究的关键创新在于将Bloom分类学与线性探测技术相结合,为理解LLM的认知复杂性提供了一种新的视角。与以往主要关注模型输出结果的研究不同,该研究深入分析了LLM的内部表征,揭示了模型如何编码和处理不同认知难度的任务。此外,该研究还发现,LLM在正向传递的早期就解决了提示的认知难度,并且表征在各层之间变得越来越可分离。
关键设计:论文的关键设计包括:1) 选择合适的LLM模型,例如Bloom;2) 精心设计包含不同Bloom分类学水平的任务提示;3) 选择合适的激活向量提取层,例如模型的残差流;4) 使用线性支持向量机(SVM)作为线性分类器;5) 使用交叉验证等方法评估分类器的性能,并进行统计显著性分析。
🖼️ 关键图片

📊 实验亮点
实验结果表明,线性分类器在所有Bloom水平上实现了约95%的平均准确率,这有力地证明了认知水平被编码在模型表征的线性可访问子空间中。此外,研究还发现,模型在正向传递的早期就解决了提示的认知难度,并且表征在各层之间变得越来越可分离。这些结果表明LLM能够有效地编码和处理不同认知复杂度的任务。
🎯 应用场景
该研究成果可应用于评估和改进LLM的认知能力,例如,通过分析模型在不同认知水平上的表现,可以发现模型的优势和不足,并针对性地进行优化。此外,该研究还可以用于开发更具可解释性和鲁棒性的LLM,提高模型在实际应用中的可靠性。未来,该方法有望推广到其他类型的AI模型,促进人工智能的可解释性研究。
📄 摘要(原文)
The black-box nature of Large Language Models necessitates novel evaluation frameworks that transcend surface-level performance metrics. This study investigates the internal neural representations of cognitive complexity using Bloom's Taxonomy as a hierarchical lens. By analyzing high-dimensional activation vectors from different LLMs, we probe whether different cognitive levels, ranging from basic recall (Remember) to abstract synthesis (Create), are linearly separable within the model's residual streams. Our results demonstrate that linear classifiers achieve approximately 95% mean accuracy across all Bloom levels, providing strong evidence that cognitive level is encoded in a linearly accessible subspace of the model's representations. These findings provide evidence that the model resolves the cognitive difficulty of a prompt early in the forward pass, with representations becoming increasingly separable across layers.