Continual learning and refinement of causal models through dynamic predicate invention
作者: Enrique Crespo-Fernandez, Oliver Ray, Telmo de Menezes e Silva Filho, Peter Flach
分类: cs.AI
发布日期: 2026-02-19
💡 一句话要点
提出基于动态谓词发明的持续学习框架,用于构建和优化因果模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 持续学习 因果模型 元解释学习 谓词发明 符号推理
📋 核心要点
- 现有世界建模方法在样本效率、透明性和可扩展性方面存在不足,难以应对复杂环境。
- 该论文提出了一种基于元解释学习和谓词发明的在线学习框架,用于构建符号因果世界模型。
- 实验证明,该方法在复杂关系动态领域具有更高的样本效率,优于传统的PPO神经网络方法。
📝 摘要(中文)
本文提出了一种框架,用于完全在线地构建符号因果世界模型。该框架将连续模型学习和修复集成到智能体的决策循环中,利用元解释学习和谓词发明的力量来寻找语义上有意义且可重用的抽象概念,从而使智能体能够从其观察中构建一个解耦的、高质量概念的层次结构。实验表明,我们的提升推理方法可以扩展到具有复杂关系动态的领域,在这些领域中,命题方法会遭受组合爆炸。同时,我们的方法实现了比基于PPO神经网络的基线高几个数量级的样本效率。
🔬 方法详解
问题定义:现有世界建模方法在复杂环境中面临挑战,主要体现在三个方面:样本效率低,需要大量的训练数据才能学习到有效的模型;缺乏透明性,难以理解模型内部的推理过程;可扩展性差,难以处理具有复杂关系动态的领域。这些问题限制了智能体在复杂环境中的学习和决策能力。
核心思路:该论文的核心思路是利用符号推理和因果建模的优势,结合元解释学习和谓词发明技术,构建一个可解释、可扩展且样本高效的因果世界模型。通过在线学习和模型修复,智能体可以不断完善其对环境的理解,并利用学到的知识进行推理和决策。
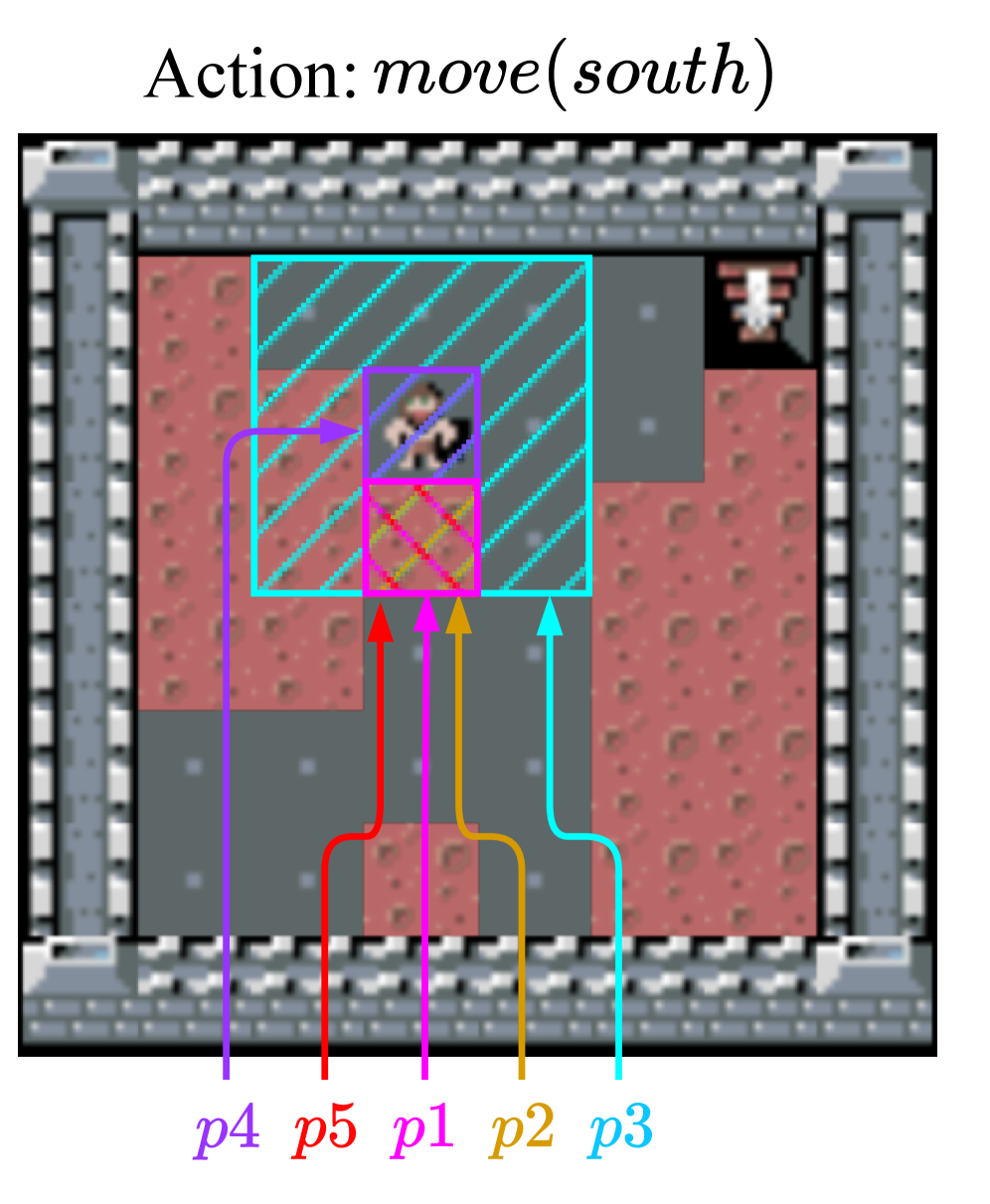
技术框架:该框架包含以下主要模块:1) 观察模块:负责从环境中获取观察数据。2) 模型学习模块:利用元解释学习和谓词发明技术,从观察数据中学习因果关系,构建符号因果模型。3) 模型修复模块:检测模型中的错误或不一致性,并利用谓词发明技术生成新的谓词,从而修复模型。4) 推理模块:利用构建的因果模型进行推理和预测,为智能体的决策提供依据。5) 决策模块:根据推理结果和环境反馈,制定智能体的行动策略。整个框架以在线方式运行,智能体在与环境交互的过程中不断学习和完善其因果模型。
关键创新:该论文的关键创新在于将元解释学习和谓词发明技术应用于因果模型构建,从而实现了符号因果模型的在线学习和修复。与传统的基于神经网络的方法相比,该方法具有更高的样本效率和更好的可解释性。此外,该方法还能够自动发现新的概念和关系,从而扩展模型的表达能力。
关键设计:论文中使用了Meta-Interpretive Learning (MIL) 来学习和完善因果模型。MIL 是一种归纳逻辑编程技术,可以从少量示例中学习复杂的逻辑规则。谓词发明是MIL的一个关键组成部分,它允许系统自动生成新的谓词,从而扩展模型的表达能力。具体的损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在具有复杂关系动态的领域中,实现了比基于PPO神经网络的基线高几个数量级的样本效率。这表明该方法在处理复杂环境时具有显著的优势。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、智能制造等领域。通过构建可解释的因果模型,智能体可以更好地理解环境,做出更合理的决策。此外,该方法还可以用于知识发现和推理,帮助人们更好地理解复杂系统。
📄 摘要(原文)
Efficiently navigating complex environments requires agents to internalize the underlying logic of their world, yet standard world modelling methods often struggle with sample inefficiency, lack of transparency, and poor scalability. We propose a framework for constructing symbolic causal world models entirely online by integrating continuous model learning and repair into the agent's decision loop, by leveraging the power of Meta-Interpretive Learning and predicate invention to find semantically meaningful and reusable abstractions, allowing an agent to construct a hierarchy of disentangled, high-quality concepts from its observations. We demonstrate that our lifted inference approach scales to domains with complex relational dynamics, where propositional methods suffer from combinatorial explosion, while achieving sample-efficiency orders of magnitude higher than the established PPO neural-network-based baseline.