Robustness and Reasoning Fidelity of Large Language Models in Long-Context Code Question Answering
作者: Kishan Maharaj, Nandakishore Menon, Ashita Saxena, Srikanth Tamilselvam
分类: cs.SE, cs.AI
发布日期: 2026-02-19
备注: 11 pages, 4 Figures, 5 Tables, Work in Progress
💡 一句话要点
研究长文本代码问答中大语言模型的鲁棒性和推理保真度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本代码问答 大型语言模型 鲁棒性 推理保真度 软件工程 LongCodeBench 受控实验
📋 核心要点
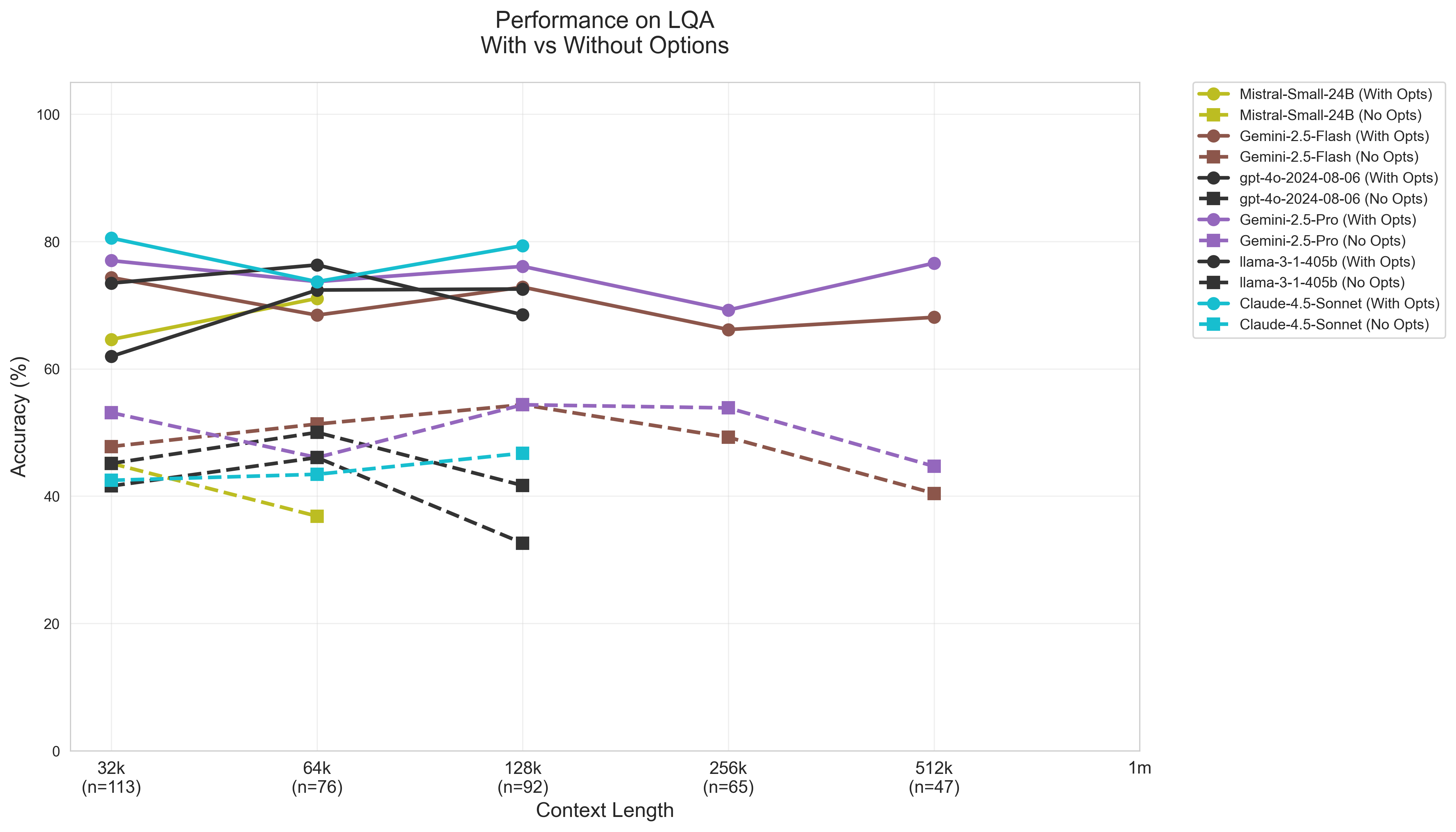
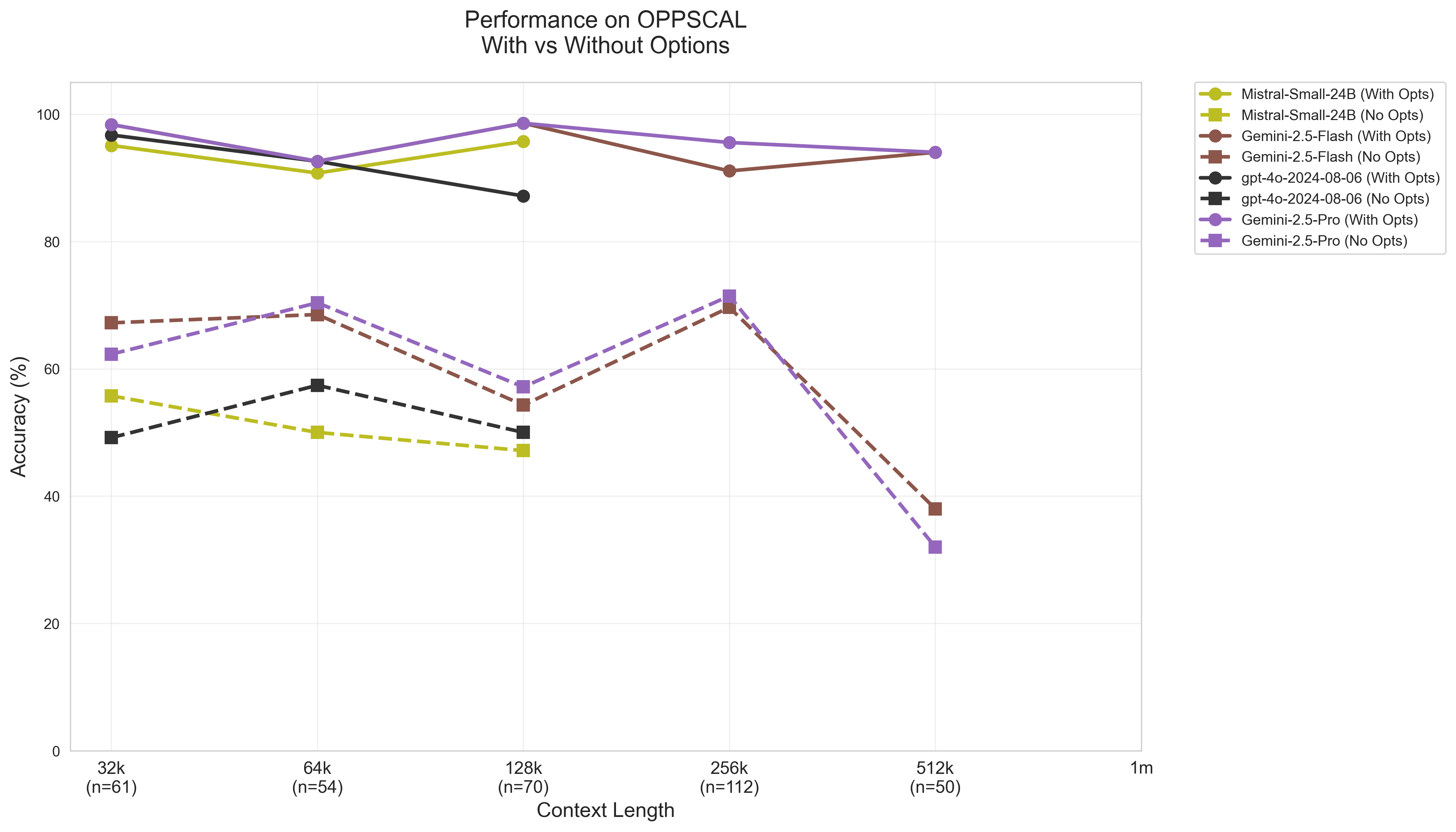
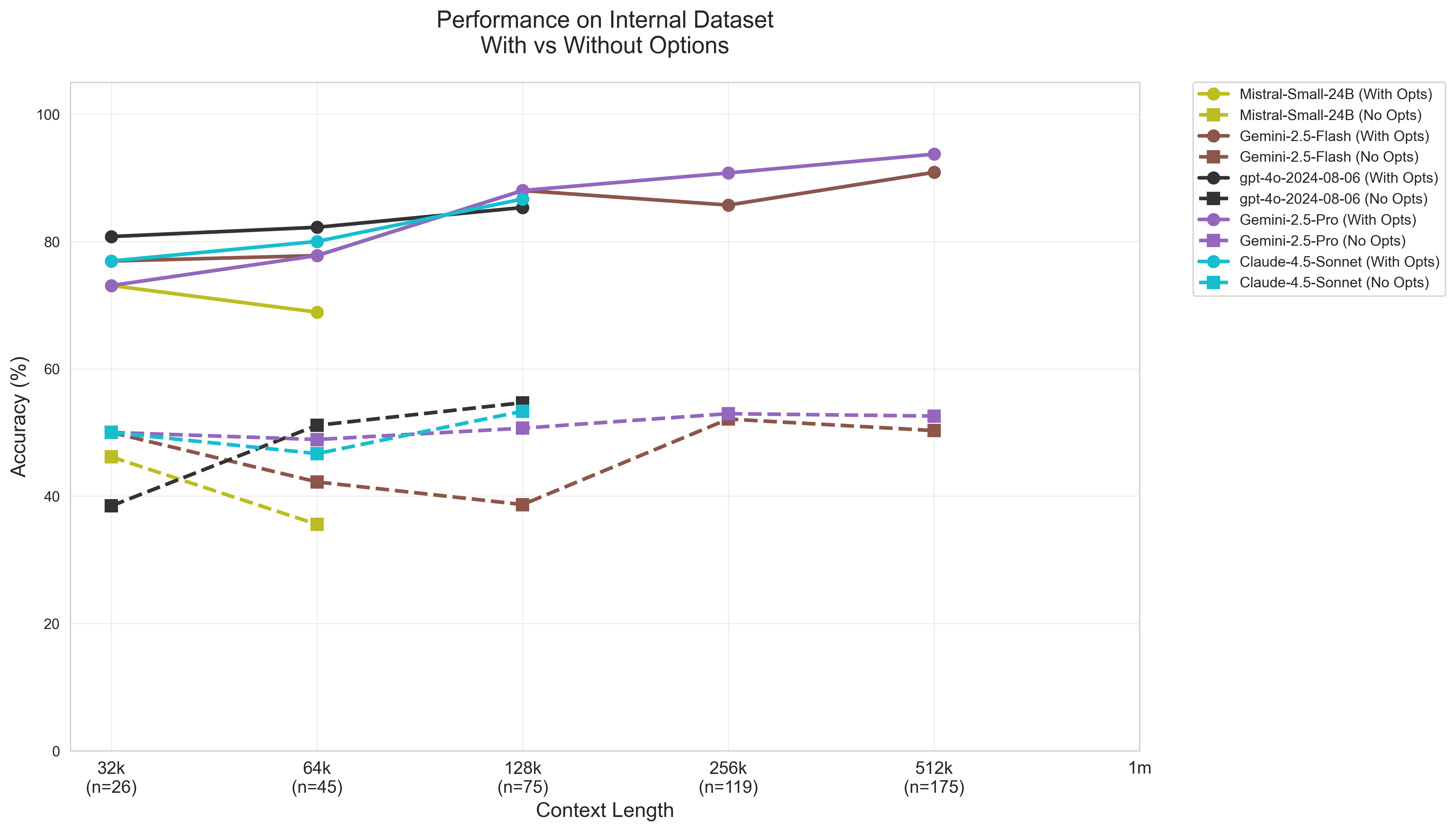
- 现有大语言模型在长文本代码问答中鲁棒性不足,易受输入格式、干扰信息等因素影响。
- 通过控制变量,系统研究大语言模型在不同输入条件下的代码问答性能,揭示其局限性。
- 扩展LongCodeBench数据集,包含COBOL和Java,并在多种设置下评估模型,发现性能显著下降。
📝 摘要(中文)
大型语言模型(LLM)越来越多地辅助需要对长代码上下文进行推理的软件工程任务,但它们在不同输入条件下的鲁棒性仍不清楚。我们对长文本代码问答进行了一项系统的研究,使用受控消融实验来测试模型对答案格式、干扰因素和上下文规模的敏感性。通过使用新的COBOL和Java问答集扩展LongCodeBench Python数据集,我们在三种设置下评估了最先进的模型:(i)打乱的多项选择选项,(ii)开放式问题,以及(iii)包含相关和对抗性无关信息的“大海捞针”上下文。结果表明,在打乱的多项选择选项和开放式问题中,性能大幅下降,并且在存在无关线索时表现出脆弱的行为。我们的发现突出了当前长文本评估的局限性,并为评估传统和现代系统中的代码推理提供了一个更广泛的基准。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本代码问答任务中鲁棒性不足的问题。现有方法在面对不同输入格式(如打乱的多项选择题)、干扰信息(“大海捞针”式上下文)时,性能会显著下降,这限制了它们在实际软件工程场景中的应用。此外,现有评估方法也存在局限性,无法全面评估模型在复杂代码推理方面的能力。
核心思路:论文的核心思路是通过系统性的受控实验,评估大型语言模型在不同输入条件下的代码问答性能。通过改变答案格式、引入干扰因素和调整上下文规模,来考察模型的鲁棒性和推理保真度。这种方法能够更清晰地揭示模型的弱点,并为改进模型提供指导。
技术框架:论文的技术框架主要包括以下几个部分:1) 数据集扩展:在LongCodeBench Python数据集的基础上,增加了COBOL和Java的问答集,以覆盖更广泛的编程语言。2) 实验设置:设计了三种实验设置,包括打乱的多项选择选项、开放式问题和“大海捞针”上下文。3) 模型评估:在不同的实验设置下,评估了最先进的大型语言模型的性能,并分析了结果。
关键创新:论文的关键创新在于其系统性的评估方法,通过控制变量来考察大型语言模型在长文本代码问答中的鲁棒性。与以往的研究相比,该论文更加关注模型在实际应用场景中的表现,并揭示了模型在面对复杂输入时的局限性。此外,扩展后的LongCodeBench数据集也为未来的研究提供了更全面的基准。
关键设计:论文的关键设计包括:1) 三种实验设置的设计,旨在模拟不同的实际应用场景,并考察模型在不同条件下的表现。2) 对抗性干扰信息的设计,旨在评估模型在面对无关信息时的鲁棒性。3) 性能指标的选择,旨在全面评估模型的准确性、召回率和推理保真度。具体的参数设置和网络结构取决于所评估的大型语言模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在打乱的多项选择选项和开放式问题中,大型语言模型的性能大幅下降。在“大海捞针”上下文中,模型容易受到无关信息的干扰,表现出脆弱的行为。这些结果突出了当前长文本评估的局限性,并为改进模型提供了重要的指导。
🎯 应用场景
该研究成果可应用于软件工程领域,帮助开发者更好地利用大型语言模型进行代码理解、问题定位和代码生成等任务。通过提高模型的鲁棒性和推理保真度,可以减少模型在实际应用中的错误率,提高开发效率。未来,该研究还可以扩展到其他领域,如自然语言处理、知识图谱等。
📄 摘要(原文)
Large language models (LLMs) increasingly assist software engineering tasks that require reasoning over long code contexts, yet their robustness under varying input conditions remains unclear. We conduct a systematic study of long-context code question answering using controlled ablations that test sensitivity to answer format, distractors, and context scale. Extending LongCodeBench Python dataset with new COBOL and Java question-answer sets, we evaluate state-of-the-art models under three settings: (i) shuffled multiple-choice options, (ii) open-ended questions and (iii) needle-in-a-haystack contexts containing relevant and adversarially irrelevant information. Results show substantial performance drops in both shuffled multiple-choice options and open-ended questions, and brittle behavior in the presence of irrelevant cues. Our findings highlight limitations of current long-context evaluations and provide a broader benchmark for assessing code reasoning in both legacy and modern systems.