Toward Trustworthy Evaluation of Sustainability Rating Methodologies: A Human-AI Collaborative Framework for Benchmark Dataset Construction
作者: Xiaoran Cai, Wang Yang, Xiyu Ren, Chekun Law, Rohit Sharma, Peng Qi
分类: cs.AI
发布日期: 2026-02-19
💡 一句话要点
提出STRIDE和SR-Delta框架,构建可持续性评级基准数据集,提升评级方法的可信度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可持续性评级 ESG评估 基准数据集 人机协作 大型语言模型 差异分析 STRIDE框架 SR-Delta框架
📋 核心要点
- 现有可持续性评级机构对同一公司的评级结果差异大,影响了评级的可信度和应用价值。
- 论文提出STRIDE和SR-Delta框架,利用大型语言模型和人工协作,构建可信赖的可持续性评级基准数据集。
- 该框架旨在实现对可持续性评级方法的可扩展和可比较的评估,从而提升评级结果的可靠性。
📝 摘要(中文)
可持续性或ESG评级机构利用公司披露信息和外部数据来评估公司的环境、社会和治理绩效,并给出相应的分数或评级。然而,不同机构对同一公司的可持续性评级差异很大,这限制了评级的可比性、可信度和决策相关性。为了协调评级结果,我们提出采用一种通用的人工智能协作框架,以生成可信的基准数据集,用于评估可持续性评级方法。该框架包含两个互补部分:STRIDE(可持续性信任评级与完整性数据方程)提供原则性标准和评分系统,指导使用大型语言模型(LLM)构建公司层面的基准数据集;SR-Delta是一个差异分析程序框架,用于发现潜在调整的见解。该框架能够对可持续性评级方法进行可扩展和可比较的评估。我们呼吁更广泛的人工智能社区采用人工智能驱动的方法,以加强和推进支持和执行紧急可持续性议程的可持续性评级方法。
🔬 方法详解
问题定义:当前可持续性评级方法面临的主要问题是不同评级机构对同一公司的ESG表现评估结果存在显著差异。这种差异源于数据来源、评估标准和方法论的不同,导致评级结果缺乏可比性和一致性,降低了评级结果的可信度,阻碍了其在投资决策和企业管理中的应用。现有方法缺乏统一的基准数据集,难以客观评估和比较不同评级方法的优劣。
核心思路:论文的核心思路是构建一个高质量、可信赖的基准数据集,用于评估和比较不同的可持续性评级方法。通过引入人工参与和大型语言模型,STRIDE框架旨在提供一套标准化的评估流程和指标,确保数据集的客观性和准确性。SR-Delta框架则用于分析不同评级结果之间的差异,从而发现潜在的偏差和改进方向。
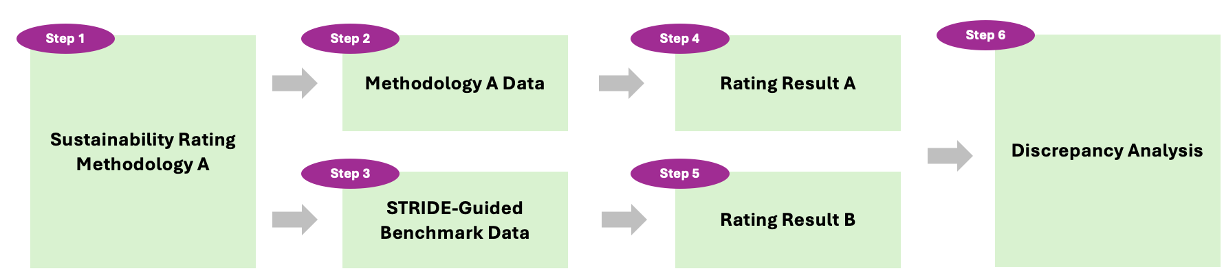
技术框架:该框架包含两个主要模块:STRIDE和SR-Delta。STRIDE负责构建基准数据集,它定义了一套原则性标准和评分系统,指导使用大型语言模型从公司披露信息和外部数据中提取相关信息,并进行评估。人工专家参与审核和校正,确保数据的准确性和一致性。SR-Delta则是一个差异分析程序框架,用于比较不同评级机构的评级结果,识别差异的来源,并提供调整建议。
关键创新:该论文的关键创新在于提出了一个通用的人工智能协作框架,用于构建可持续性评级基准数据集。该框架结合了大型语言模型的自动化数据提取和人工专家的专业知识,旨在克服现有评级方法的主观性和不一致性。通过STRIDE和SR-Delta的协同作用,该框架能够提供更客观、可信赖的评估结果。
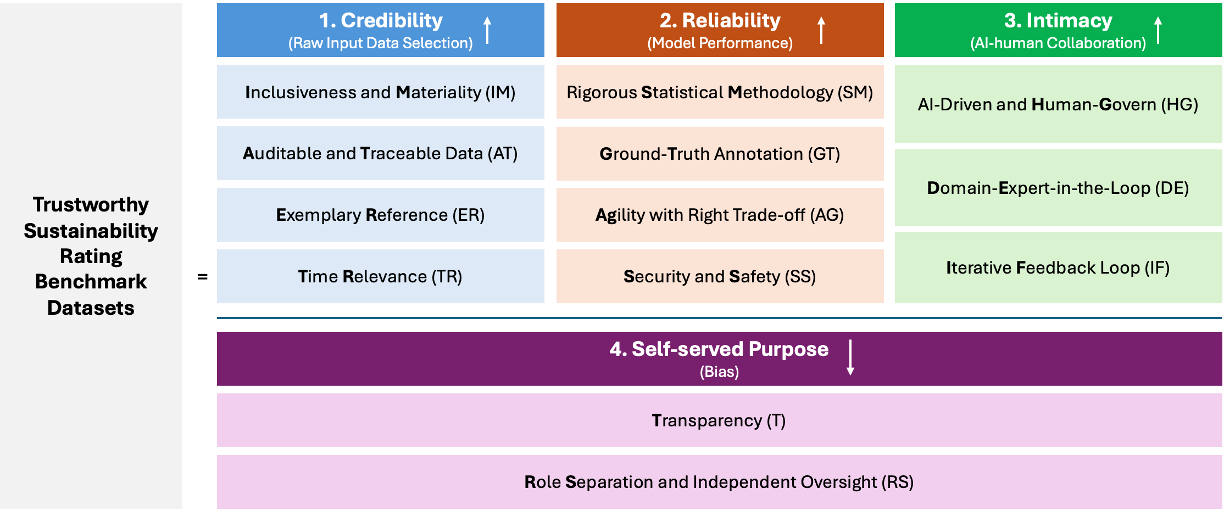
关键设计:STRIDE框架的关键设计包括:1) 定义明确的ESG评估标准和指标;2) 使用大型语言模型进行自动化数据提取和初步评估;3) 引入人工专家进行审核和校正;4) 建立评分系统,对公司的ESG表现进行量化评估。SR-Delta框架的关键设计包括:1) 定义差异分析的指标和方法;2) 比较不同评级机构的评级结果;3) 分析差异的来源;4) 提供调整建议,以提高评级结果的一致性。
🖼️ 关键图片
📊 实验亮点
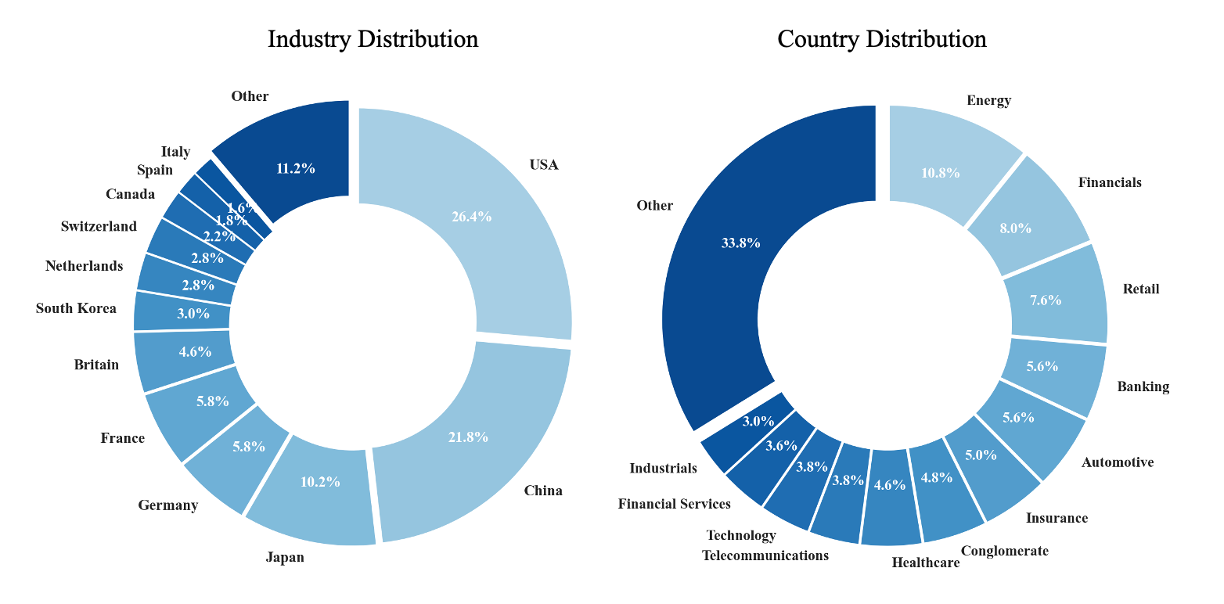
论文提出了STRIDE和SR-Delta框架,旨在构建高质量的可持续性评级基准数据集。通过结合大型语言模型和人工专家的协作,该框架能够提供更客观、可信赖的评估结果,从而提升可持续性评级方法的可信度和应用价值。具体实验数据未知,但框架本身的设计具有显著的创新性和潜在的应用价值。
🎯 应用场景
该研究成果可应用于金融投资、企业管理和政策制定等领域。投资者可以利用该基准数据集评估不同ESG评级机构的可靠性,从而做出更明智的投资决策。企业可以利用该框架改进自身的ESG表现,提升企业形象。政府部门可以利用该框架制定更有效的可持续发展政策。
📄 摘要(原文)
Sustainability or ESG rating agencies use company disclosures and external data to produce scores or ratings that assess the environmental, social, and governance performance of a company. However, sustainability ratings across agencies for a single company vary widely, limiting their comparability, credibility, and relevance to decision-making. To harmonize the rating results, we propose adopting a universal human-AI collaboration framework to generate trustworthy benchmark datasets for evaluating sustainability rating methodologies. The framework comprises two complementary parts: STRIDE (Sustainability Trust Rating & Integrity Data Equation) provides principled criteria and a scoring system that guide the construction of firm-level benchmark datasets using large language models (LLMs), and SR-Delta, a discrepancy-analysis procedural framework that surfaces insights for potential adjustments. The framework enables scalable and comparable assessment of sustainability rating methodologies. We call on the broader AI community to adopt AI-powered approaches to strengthen and advance sustainability rating methodologies that support and enforce urgent sustainability agendas.