Retaining Suboptimal Actions to Follow Shifting Optima in Multi-Agent Reinforcement Learning
作者: Yonghyeon Jo, Sunwoo Lee, Seungyul Han
分类: cs.AI
发布日期: 2026-02-19
备注: 10 technical page followed by references and appendix. Accepted to ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出S2Q算法,解决MARL中价值函数漂移导致策略次优问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 价值分解 价值函数漂移 次优动作保留 探索策略
📋 核心要点
- 现有MARL方法依赖单一最优动作,在价值函数漂移时难以适应,易收敛至次优策略。
- S2Q算法学习多个子价值函数,保留高价值的替代动作,提升对价值函数变化的适应性。
- 实验表明,S2Q在多个MARL基准测试中超越现有算法,验证了其适应性和整体性能的提升。
📝 摘要(中文)
价值分解是合作式多智能体强化学习(MARL)的核心方法。然而,现有方法依赖于单一最优动作,难以适应训练过程中价值函数的漂移,常收敛到次优策略。为解决此局限,我们提出Successive Sub-value Q-learning (S2Q),学习多个子价值函数以保留替代的高价值动作。通过将这些子价值函数融入基于Softmax的行为策略,S2Q鼓励持续探索,使$Q^{ ext{tot}}$能够快速适应变化的最优动作。在具有挑战性的MARL基准测试中,实验结果表明S2Q始终优于各种MARL算法,展示了改进的适应性和整体性能。代码已开源。
🔬 方法详解
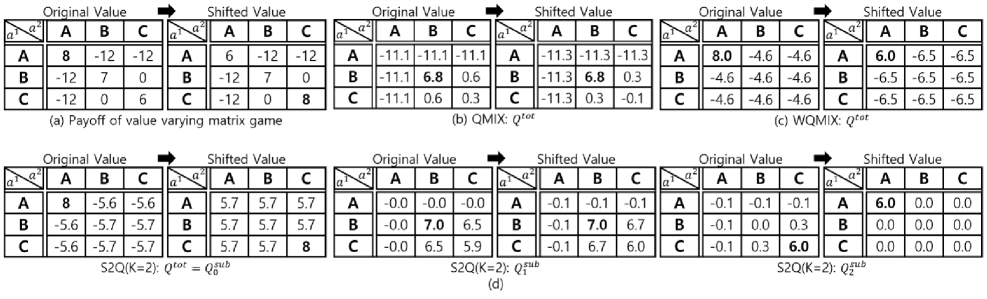
问题定义:现有基于价值分解的MARL算法在面对价值函数漂移时,由于过度依赖单一最优动作,导致策略难以快速适应新的最优动作,最终收敛到次优策略。这种现象在动态变化的环境中尤为明显,限制了MARL算法的实际应用。
核心思路:S2Q的核心思路是学习多个子价值函数,每个子价值函数对应一个潜在的高价值动作。通过保留这些次优但仍然具有较高价值的动作,S2Q能够更好地应对价值函数的漂移,并在新的最优动作出现时快速切换到相应的策略。这种方法鼓励持续探索,避免过早收敛到局部最优。
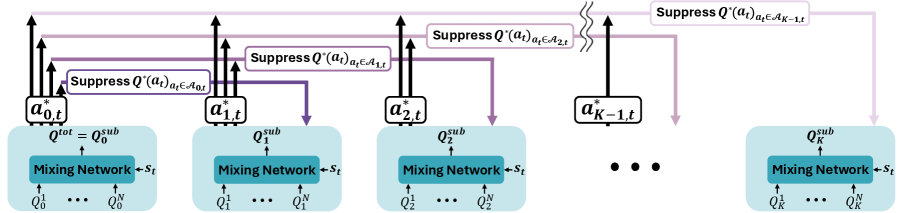
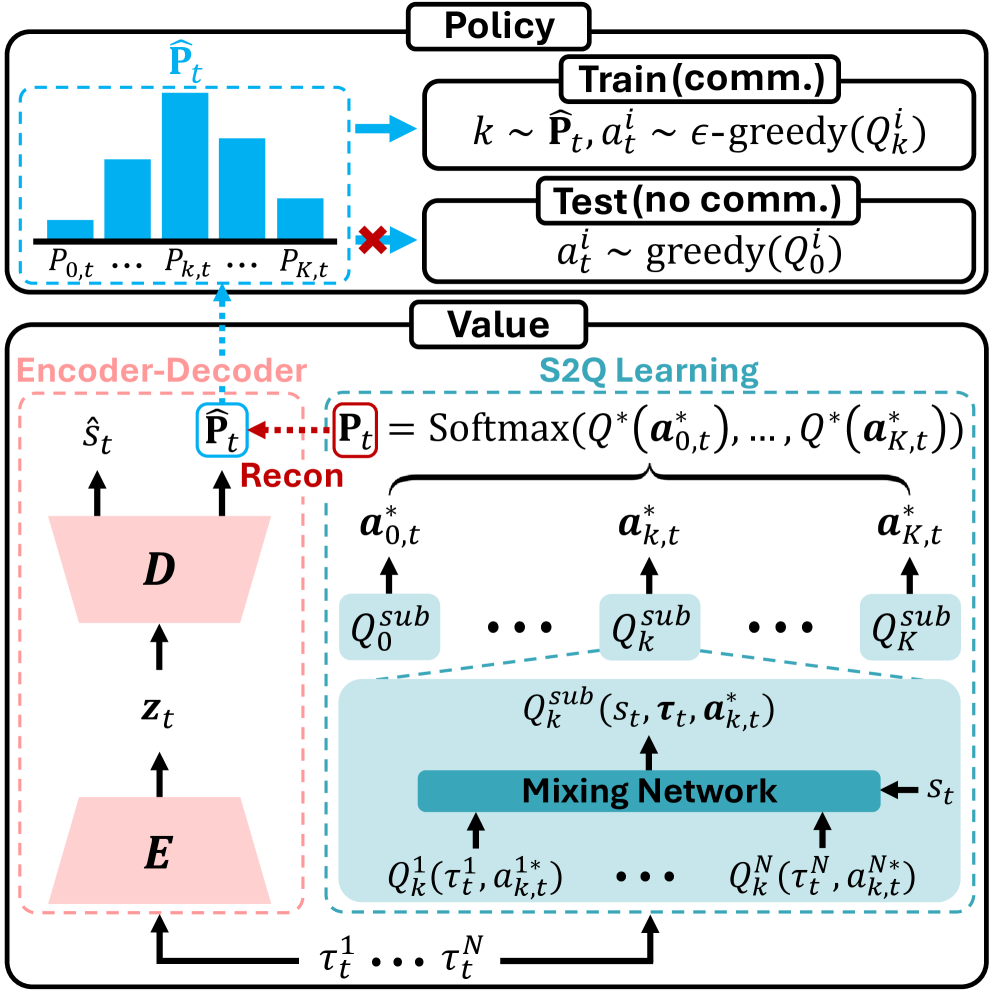
技术框架:S2Q的整体框架基于标准的MARL架构,主要包括以下几个模块:1) 多个子价值函数学习模块,用于学习不同动作的子价值;2) 基于Softmax的行为策略,该策略将所有子价值函数纳入考虑,并根据其价值分配动作概率;3) 联合Q值函数($Q^{ ext{tot}}$)更新模块,用于根据环境反馈更新所有子价值函数。算法流程为:智能体根据Softmax策略选择动作,与环境交互获得奖励,然后使用TD-learning更新$Q^{ ext{tot}}$,并反向传播更新子价值函数。
关键创新:S2Q的关键创新在于引入了多个子价值函数,并将其融入到行为策略中。与传统的只关注单一最优动作的方法不同,S2Q能够保留多个高价值的替代动作,从而更好地适应价值函数的漂移。此外,S2Q使用Softmax策略来平衡不同子价值函数的影响,鼓励持续探索,避免过早收敛。
关键设计:S2Q的关键设计包括:1) 子价值函数的数量:需要根据具体任务进行调整,数量过多会增加计算复杂度,数量过少则可能无法保留足够多的替代动作;2) Softmax温度参数:控制探索的程度,温度越高,探索的概率越大;3) 损失函数:采用TD-error来更新$Q^{ ext{tot}}$和子价值函数,确保价值函数的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,S2Q在多个具有挑战性的MARL基准测试中,例如StarCraft II和Multi-Particle Environment,显著优于包括QMIX、VDN等在内的多种主流MARL算法。具体而言,S2Q在适应价值函数漂移方面表现出更快的收敛速度和更高的最终性能,验证了其在动态环境中的优越性。在某些场景下,S2Q的性能提升幅度超过10%。
🎯 应用场景
S2Q算法适用于需要智能体快速适应环境变化的合作式多智能体系统,例如:动态交通调度、资源分配、机器人协同等。该算法能够提升智能体在非静态环境中的适应性和鲁棒性,使其能够更好地完成协作任务。未来,S2Q可以应用于更复杂的现实场景,例如:智能制造、智慧城市等。
📄 摘要(原文)
Value decomposition is a core approach for cooperative multi-agent reinforcement learning (MARL). However, existing methods still rely on a single optimal action and struggle to adapt when the underlying value function shifts during training, often converging to suboptimal policies. To address this limitation, we propose Successive Sub-value Q-learning (S2Q), which learns multiple sub-value functions to retain alternative high-value actions. Incorporating these sub-value functions into a Softmax-based behavior policy, S2Q encourages persistent exploration and enables $Q^{\text{tot}}$ to adjust quickly to the changing optima. Experiments on challenging MARL benchmarks confirm that S2Q consistently outperforms various MARL algorithms, demonstrating improved adaptability and overall performance. Our code is available at https://github.com/hyeon1996/S2Q.