Phase-Aware Mixture of Experts for Agentic Reinforcement Learning
作者: Shengtian Yang, Yu Li, Shuo He, Yewen Li, Qingpeng Cai, Peng Jiang, Lei Feng
分类: cs.AI
发布日期: 2026-02-19
备注: 16 pages
💡 一句话要点
提出Phase-Aware MoE,解决Agent强化学习中的简单任务主导问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 混合专家 阶段感知 Agent 策略网络
📋 核心要点
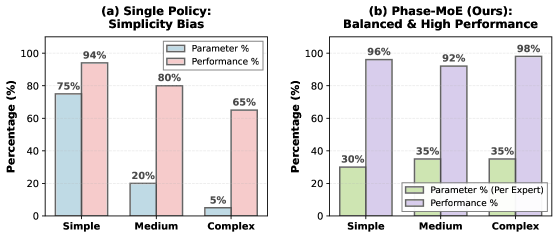
- 现有强化学习方法使用单一策略网络,导致简单任务占用过多参数,复杂任务容量不足。
- 提出Phase-Aware MoE,通过阶段路由器学习潜在阶段边界,实现专家在时间上的一致性分配。
- 实验结果表明,PA-MoE能够有效提升Agent在复杂任务中的强化学习性能。
📝 摘要(中文)
强化学习(RL)赋予了LLM Agent解决复杂任务的强大能力。然而,现有的RL方法通常使用单一策略网络,导致“简单性偏差”,即简单任务占据了大部分参数并主导梯度更新,从而为复杂任务留下了不足的容量。一个可行的补救措施是在策略网络中采用混合专家(MoE)架构,因为MoE允许不同的参数(专家)专门处理不同的任务,从而防止简单任务主导所有参数。然而,传统MoE的一个关键限制是其token级别的路由,其中路由器将每个token分配给专门的专家,这会将阶段一致的模式碎片化为分散的专家分配,从而破坏专家专业化。在本文中,我们提出了Phase-Aware混合专家(PA-MoE)。它首先采用了一个轻量级的阶段路由器,该路由器直接从RL目标中学习潜在的阶段边界,而无需预先定义阶段类别。然后,阶段路由器将时间上一致的分配分配给同一专家,从而允许专家保留特定于阶段的专业知识。实验结果证明了我们提出的PA-MoE的有效性。
🔬 方法详解
问题定义:现有基于强化学习的Agent通常采用单一策略网络,这导致了“简单性偏差”问题。具体来说,简单任务由于其普遍性,会占据策略网络的大部分参数,并主导梯度更新过程,使得策略网络难以有效学习和处理复杂任务。因此,如何提升Agent在复杂任务中的学习能力,是本文要解决的核心问题。
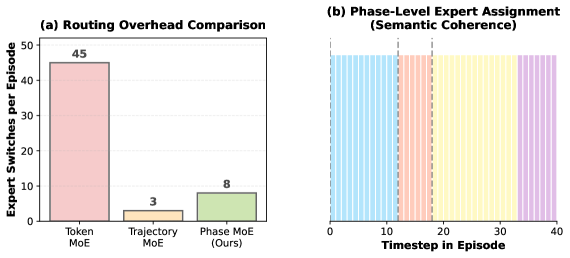
核心思路:本文的核心思路是引入混合专家(MoE)架构,并针对传统MoE在Agent强化学习中的不足进行改进。MoE允许不同的专家专注于不同的任务,从而避免简单任务主导所有参数。然而,传统的token级别路由会破坏任务阶段的一致性。因此,本文提出Phase-Aware MoE,旨在提升专家在特定任务阶段的专业性。
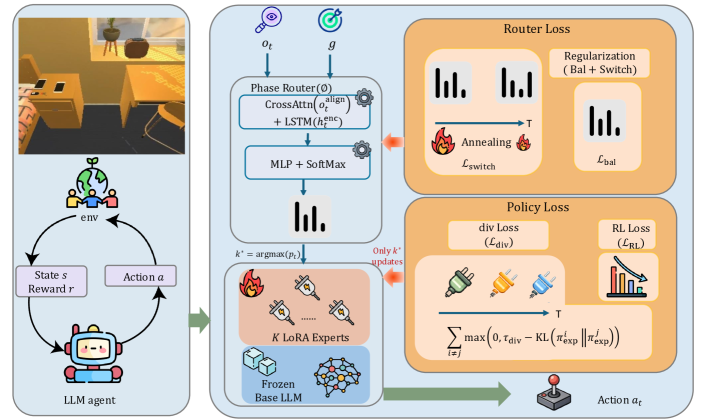
技术框架:PA-MoE主要包含两个核心模块:策略网络和阶段路由器。策略网络采用MoE架构,由多个专家网络组成。阶段路由器负责将输入分配给不同的专家。与传统MoE不同的是,PA-MoE的阶段路由器不是基于token级别进行路由,而是基于学习到的潜在阶段边界进行路由,从而保证时间上的一致性。整体流程是:Agent接收环境状态,阶段路由器根据状态确定当前所处的阶段,并将状态分配给对应的专家进行处理,专家输出动作,Agent执行动作并获得奖励,然后利用奖励更新策略网络和阶段路由器。
关键创新:PA-MoE的关键创新在于提出了阶段路由器的概念,并将其应用于Agent强化学习中。与传统的token级别路由相比,阶段路由器能够学习潜在的阶段边界,并将时间上相邻的状态分配给同一专家,从而保证专家在特定阶段的专业性。这种阶段感知的路由方式能够有效提升Agent在复杂任务中的学习能力。
关键设计:阶段路由器的设计是PA-MoE的关键。阶段路由器是一个轻量级的神经网络,其输入是Agent的状态,输出是各个阶段的概率分布。阶段路由器的训练目标是最大化Agent的累积奖励,即通过强化学习的方式学习阶段边界。具体来说,可以使用策略梯度算法或者Actor-Critic算法来训练阶段路由器。此外,还可以引入正则化项,以鼓励阶段边界的平滑性,避免出现频繁的阶段切换。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了PA-MoE的有效性。实验结果表明,PA-MoE在多个复杂任务中都取得了显著的性能提升,超过了传统的MoE方法和其他基线方法。具体的性能数据和提升幅度在论文中有详细的展示。
🎯 应用场景
PA-MoE具有广泛的应用前景,例如在机器人控制、游戏AI、自动驾驶等领域。通过将复杂任务分解为多个阶段,并让不同的专家专注于不同的阶段,可以有效提升Agent在复杂环境中的适应性和学习效率。此外,PA-MoE还可以应用于多智能体系统,让不同的Agent专注于不同的任务,从而实现更高效的协作。
📄 摘要(原文)
Reinforcement learning (RL) has equipped LLM agents with a strong ability to solve complex tasks. However, existing RL methods normally use a \emph{single} policy network, causing \emph{simplicity bias} where simple tasks occupy most parameters and dominate gradient updates, leaving insufficient capacity for complex tasks. A plausible remedy could be employing the Mixture-of-Experts (MoE) architecture in the policy network, as MoE allows different parameters (experts) to specialize in different tasks, preventing simple tasks from dominating all parameters. However, a key limitation of traditional MoE is its token-level routing, where the router assigns each token to specialized experts, which fragments phase-consistent patterns into scattered expert assignments and thus undermines expert specialization. In this paper, we propose \textbf{Phase-Aware Mixture of Experts (PA-MoE)}. It first features a lightweight \emph{phase router} that learns latent phase boundaries directly from the RL objective without pre-defining phase categories. Then, the phase router allocates temporally consistent assignments to the same expert, allowing experts to preserve phase-specific expertise. Experimental results demonstrate the effectiveness of our proposed PA-MoE.