Exploring LLMs for User Story Extraction from Mockups
作者: Diego Firmenich, Leandro Antonelli, Bruno Pazos, Fabricio Lozada, Leonardo Morales
分类: cs.SE, cs.AI, cs.CL
发布日期: 2026-02-19
备注: 14 pages, 6 figures. Preprint of the paper published in the 28th Workshop on Requirements Engineering (WER 2025)
期刊: Proceedings of the 28th Workshop on Requirements Engineering (WER2025)
💡 一句话要点
探索大型语言模型从模型草图中提取用户故事
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 用户故事提取 需求工程 模型草图 自动化 语言扩展词典 软件开发
📋 核心要点
- 软件需求工程中,用户故事定义至关重要,但传统方法依赖人工,效率低且易出错。
- 该研究探索利用大型语言模型(LLM)自动从高保真模型草图中提取用户故事,提升效率。
- 实验表明,在LLM提示中加入语言扩展词典(LEL)词汇表,显著提高了用户故事的准确性和适用性。
📝 摘要(中文)
用户故事是软件行业中定义功能需求最广泛使用的工件之一。同时,高保真模型草图的使用有助于最终用户参与定义他们的需求。本文探讨了如何将这些技术与大型语言模型(LLM)相结合,从而实现从模型草图中敏捷且自动地生成用户故事。为此,我们提出了一个案例研究,分析了LLM从高保真模型草图中提取用户故事的能力,包括在提示中包含和不包含语言扩展词典(LEL)的词汇表。结果表明,结合LEL显著提高了生成的用户故事的准确性和适用性。这种方法代表了人工智能集成到需求工程中的一步,有可能改善用户和开发人员之间的沟通。
🔬 方法详解
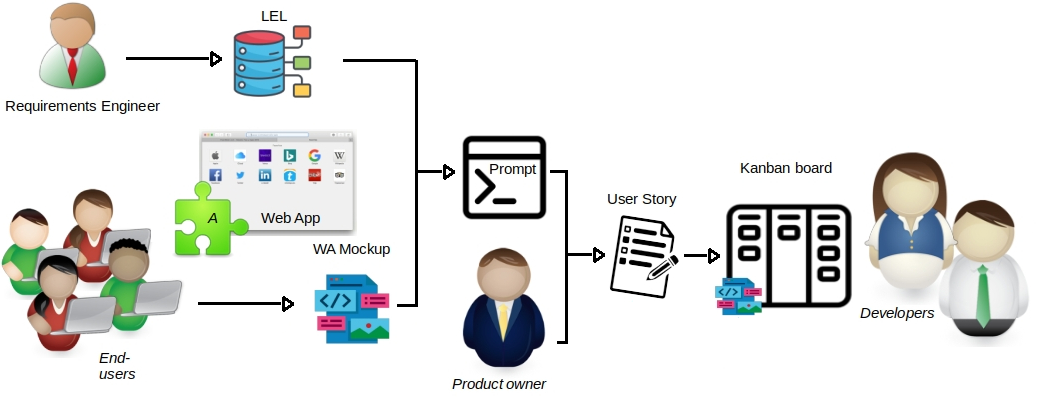
问题定义:论文旨在解决软件开发中用户故事提取的自动化问题。现有方法依赖人工编写,耗时且容易引入主观偏差,难以保证用户故事的质量和完整性。此外,如何有效地将用户需求(通常以模型草图的形式呈现)转化为可执行的用户故事也是一个挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解和生成能力,直接从高保真模型草图中提取用户故事。通过将模型草图作为LLM的输入,并结合领域知识(如语言扩展词典LEL),引导LLM生成符合要求的用户故事。这样可以减少人工干预,提高用户故事生成的效率和一致性。
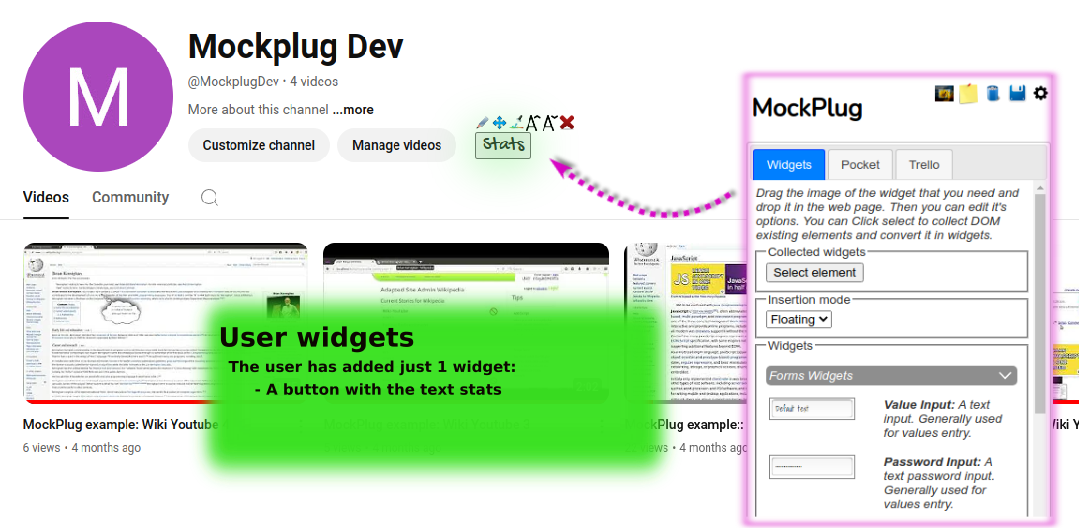
技术框架:该研究采用案例研究方法,主要流程包括:1) 收集高保真模型草图;2) 构建包含或不包含LEL词汇表的LLM提示;3) 使用LLM生成用户故事;4) 对生成的用户故事进行评估,包括准确性和适用性。整体框架较为简洁,重点在于LLM提示的设计和实验结果的分析。
关键创新:该研究的关键创新在于探索了LLM在用户故事提取领域的应用,并验证了领域知识(LEL)对LLM生成质量的提升作用。与传统方法相比,该方法实现了用户故事生成的自动化,并能够更好地利用模型草图中的信息。
关键设计:论文的关键设计在于LLM提示的设计,包括如何将模型草图的信息有效地传递给LLM,以及如何利用LEL词汇表引导LLM生成符合要求的用户故事。具体的参数设置和网络结构未在论文中详细描述,可能使用了现有的LLM模型(具体模型未知)并进行了微调或提示工程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在LLM提示中加入语言扩展词典(LEL)词汇表,显著提高了生成的用户故事的准确性和适用性。具体性能数据和提升幅度未在摘要中明确给出,但强调了LEL的重要性。这表明领域知识可以有效提升LLM在特定任务中的表现。
🎯 应用场景
该研究成果可应用于软件开发的各个阶段,尤其是在需求分析和设计阶段。通过自动化用户故事提取,可以加速软件开发流程,降低开发成本,并提高用户满意度。未来,该技术可扩展到其他类型的需求文档,例如用例图、流程图等,实现更全面的需求自动化。
📄 摘要(原文)
User stories are one of the most widely used artifacts in the software industry to define functional requirements. In parallel, the use of high-fidelity mockups facilitates end-user participation in defining their needs. In this work, we explore how combining these techniques with large language models (LLMs) enables agile and automated generation of user stories from mockups. To this end, we present a case study that analyzes the ability of LLMs to extract user stories from high-fidelity mockups, both with and without the inclusion of a glossary of the Language Extended Lexicon (LEL) in the prompts. Our results demonstrate that incorporating the LEL significantly enhances the accuracy and suitability of the generated user stories. This approach represents a step forward in the integration of AI into requirements engineering, with the potential to improve communication between users and developers.