SPARC: Scenario Planning and Reasoning for Automated C Unit Test Generation
作者: Jaid Monwar Chowdhury, Chi-An Fu, Reyhaneh Jabbarvand
分类: cs.SE, cs.AI
发布日期: 2026-02-18
备注: 9 pages, 6 figures, 4 tables
💡 一句话要点
SPARC:基于场景规划与推理的自动化C单元测试生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化单元测试生成 大型语言模型 神经符号方法 C语言 控制流分析 场景规划 代码覆盖率
📋 核心要点
- 现有C单元测试生成方法难以弥合高级意图与底层代码约束的语义鸿沟,导致生成质量不佳。
- SPARC框架通过控制流分析、操作映射和路径目标测试合成,引导LLM进行更有效的代码生成。
- 实验表明,SPARC在代码覆盖率和可维护性方面显著优于现有方法,并能有效应用于工业级C代码测试。
📝 摘要(中文)
由于高级程序意图与C语言指针运算和手动内存管理的严格语法约束之间存在语义鸿沟,C语言的自动化单元测试生成仍然是一个巨大的挑战。大型语言模型(LLM)虽然表现出强大的生成能力,但直接的意图到代码合成经常遭受“跃迁到代码”的失败模式,即模型在没有扎根于程序结构、约束和语义的情况下过早地生成代码。这将导致不可编译的测试、幻觉函数签名、低分支覆盖率以及无法正确捕获错误的语义无关断言。我们引入SPARC,一个神经符号的、基于场景的框架,通过四个阶段弥合了这一差距:(1)控制流图(CFG)分析,(2)一个操作映射,将LLM推理建立在经过验证的实用程序助手之上,(3)路径目标测试合成,以及(4)一个使用编译器和运行时反馈的迭代、自我纠正验证循环。我们在59个真实世界和算法主题上评估SPARC,在线覆盖率方面优于vanilla prompt生成基线31.36%,在分支覆盖率方面优于26.01%,在变异分数方面优于20.78%,在复杂主题上匹配或超过符号执行工具KLEE。SPARC通过迭代修复保留了94.3%的测试,并生成了具有更高开发者评价的可读性和可维护性的代码。通过将LLM推理与程序结构对齐,SPARC为工业级测试遗留C代码库提供了一条可扩展的路径。
🔬 方法详解
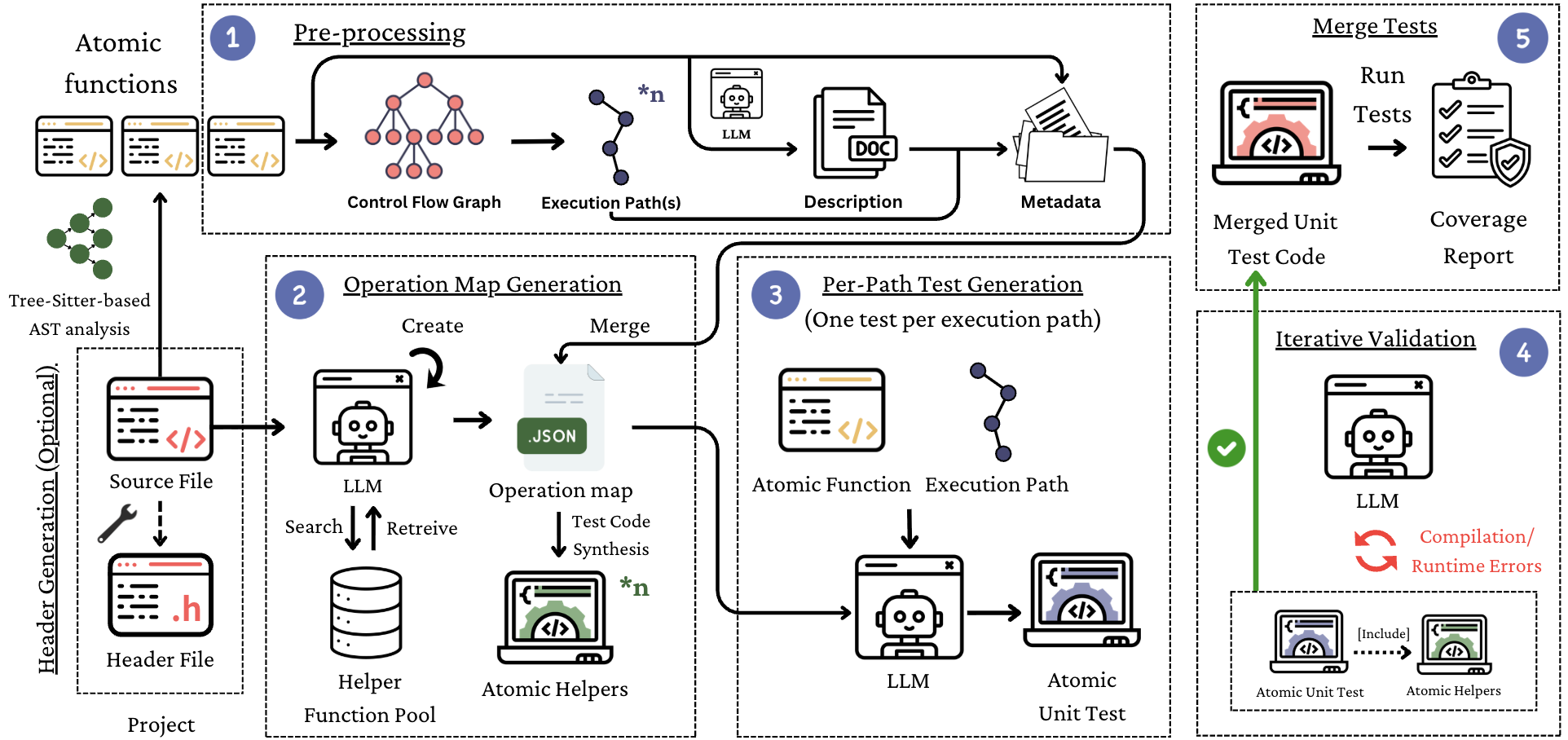
问题定义:C语言自动化单元测试生成面临的挑战在于,如何将高层次的程序意图转化为符合C语言语法和语义约束的代码。现有方法,特别是直接使用大型语言模型生成代码,容易出现“跃迁到代码”的问题,即模型在没有充分理解程序结构和约束的情况下就开始生成代码,导致生成的测试用例无法编译、语义不正确,并且覆盖率低。
核心思路:SPARC的核心思路是将LLM的生成能力与程序的结构化信息相结合,通过场景规划和推理来引导LLM生成更有效的测试用例。具体来说,SPARC首先分析程序的控制流图,然后利用操作映射将LLM的推理建立在经过验证的实用程序助手之上,最后进行路径目标测试合成。这种方法可以避免LLM直接生成代码时可能出现的错误,并提高生成测试用例的质量。
技术框架:SPARC框架包含四个主要阶段:(1)控制流图(CFG)分析:分析目标C代码的控制流结构。(2)操作映射:构建一个操作映射,将LLM的推理与经过验证的实用程序助手相关联。(3)路径目标测试合成:基于控制流图和操作映射,生成针对特定路径的测试用例。(4)迭代自我纠正验证循环:使用编译器和运行时反馈,迭代地修复和改进生成的测试用例。
关键创新:SPARC的关键创新在于其神经符号的、基于场景的框架,该框架将LLM的生成能力与程序的结构化信息相结合。通过控制流分析和操作映射,SPARC可以引导LLM生成更有效的测试用例,并避免直接生成代码时可能出现的错误。此外,SPARC的迭代自我纠正验证循环可以进一步提高生成测试用例的质量。
关键设计:操作映射的设计是SPARC的关键。操作映射包含一组经过验证的实用程序助手,这些助手可以帮助LLM理解C语言的语法和语义,并生成符合C语言约束的代码。迭代自我纠正验证循环使用编译器和运行时反馈来检测和修复生成的测试用例中的错误。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
SPARC在59个真实世界和算法主题上的实验结果表明,其在线覆盖率方面优于vanilla prompt生成基线31.36%,在分支覆盖率方面优于26.01%,在变异分数方面优于20.78%,在复杂主题上匹配或超过符号执行工具KLEE。此外,SPARC通过迭代修复保留了94.3%的测试,并生成了具有更高开发者评价的可读性和可维护性的代码。
🎯 应用场景
SPARC框架可应用于工业界遗留C代码库的自动化单元测试生成,降低测试成本,提高代码质量。该方法能够有效处理复杂的C语言特性,为大规模C代码的测试提供可扩展的解决方案,并有望推广到其他编程语言的自动化测试领域。
📄 摘要(原文)
Automated unit test generation for C remains a formidable challenge due to the semantic gap between high-level program intent and the rigid syntactic constraints of pointer arithmetic and manual memory management. While Large Language Models (LLMs) exhibit strong generative capabilities, direct intent-to-code synthesis frequently suffers from the leap-to-code failure mode, where models prematurely emit code without grounding in program structure, constraints, and semantics. This will result in non-compilable tests, hallucinated function signatures, low branch coverage, and semantically irrelevant assertions that cannot properly capture bugs. We introduce SPARC, a neuro-symbolic, scenario-based framework that bridges this gap through four stages: (1) Control Flow Graph (CFG) analysis, (2) an Operation Map that grounds LLM reasoning in validated utility helpers, (3) Path-targeted test synthesis, and (4) an iterative, self-correction validation loop using compiler and runtime feedback. We evaluate SPARC on 59 real-world and algorithmic subjects, where it outperforms the vanilla prompt generation baseline by 31.36% in line coverage, 26.01% in branch coverage, and 20.78% in mutation score, matching or exceeding the symbolic execution tool KLEE on complex subjects. SPARC retains 94.3% of tests through iterative repair and produces code with significantly higher developer-rated readability and maintainability. By aligning LLM reasoning with program structure, SPARC provides a scalable path for industrial-grade testing of legacy C codebases.