Retrieval Augmented Generation of Literature-derived Polymer Knowledge: The Example of a Biodegradable Polymer Expert System
作者: Sonakshi Gupta, Akhlak Mahmood, Wei Xiong, Rampi Ramprasad
分类: cs.CE, cs.AI
发布日期: 2026-02-18
💡 一句话要点
提出两种检索增强生成(RAG)方法,用于从聚合物文献中提取知识,构建可信赖的生物降解聚合物专家系统。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识图谱 聚合物知识提取 生物降解聚合物 大型语言模型 材料科学 语义向量 多跳推理
📋 核心要点
- 现有聚合物知识提取方法难以处理非结构化文本和术语不一致问题,无法有效利用跨研究的上下文信息。
- 论文提出两种检索增强生成(RAG)方法,VectorRAG和GraphRAG,分别基于语义向量和知识图谱,用于聚合物知识提取。
- 实验表明,GraphRAG在精度和可解释性方面表现更优,VectorRAG则具有更广的召回率,两者各有优势。
📝 摘要(中文)
聚合物文献包含大量且不断增长的实验知识,但其中大部分隐藏在非结构化文本和不一致的术语中,使得系统检索和推理变得困难。现有工具通常孤立地提取狭窄的、特定于研究的事实,无法保留回答更广泛科学问题所需的跨研究上下文。检索增强生成(RAG)提供了一种有希望克服此限制的方法,它将大型语言模型(LLM)与外部检索相结合,但其有效性在很大程度上取决于领域知识的表示方式。在这项工作中,我们开发了两种检索管道:一种基于密集语义向量的方法(VectorRAG)和一种基于图的方法(GraphRAG)。使用超过1,000篇聚羟基脂肪酸酯(PHA)论文,我们构建了保留上下文的段落嵌入和一个规范化的结构化知识图,支持实体消歧和多跳推理。我们通过标准检索指标、与GPT和Gemini等通用最先进系统的比较以及领域化学家的定性验证来评估这些管道。结果表明,GraphRAG实现了更高的精度和可解释性,而VectorRAG提供了更广泛的召回率,突出了互补的权衡。专家验证进一步证实,定制的管道,特别是GraphRAG,产生了有充分依据、引文可靠且具有强大领域相关性的响应。通过将每个陈述都建立在证据的基础上,这些系统使研究人员能够浏览文献,比较跨研究的发现,并发现难以手动提取的模式。更广泛地说,这项工作建立了一个实用的框架,用于使用精选的语料库和检索设计来构建材料科学助手,从而减少对专有模型的依赖,同时实现大规模的可信赖的文献分析。
🔬 方法详解
问题定义:现有聚合物知识提取方法主要面临两个痛点:一是聚合物文献信息分散在大量的非结构化文本中,难以有效检索;二是不同研究中使用的术语不一致,导致知识整合困难。现有方法通常只能提取孤立的事实,无法进行跨研究的推理和知识融合。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,结合大型语言模型(LLM)的生成能力和外部知识库的检索能力,从而克服现有方法的局限性。通过构建领域相关的知识库,并设计有效的检索策略,使LLM能够生成基于证据的、可信赖的聚合物知识。
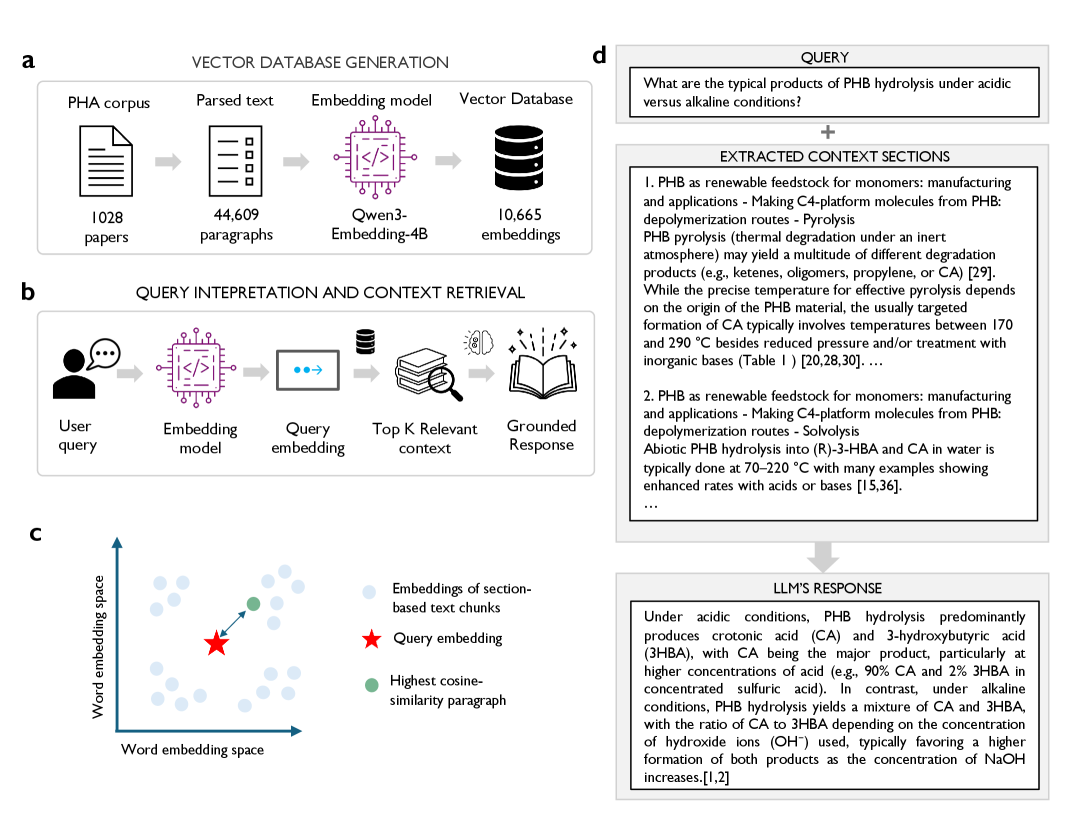
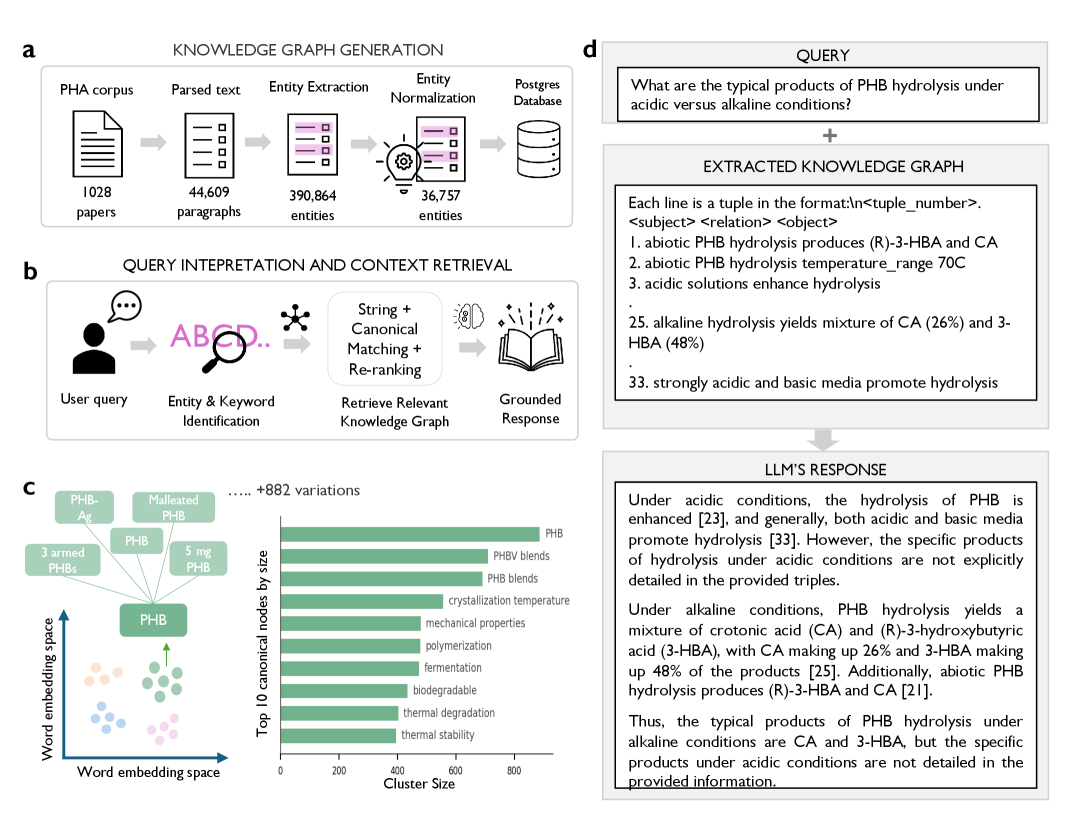
技术框架:整体框架包含两个主要的RAG管道:VectorRAG和GraphRAG。VectorRAG首先将聚合物文献段落嵌入到语义向量空间中,然后使用相似度搜索进行检索。GraphRAG则构建一个规范化的知识图谱,其中节点代表实体(如聚合物、性质),边代表关系。检索过程包括实体消歧和多跳推理,以找到与查询相关的知识。最后,检索到的信息被输入到LLM中,生成最终答案。
关键创新:论文的关键创新在于针对聚合物领域的特点,设计了两种不同的知识表示和检索方法:VectorRAG和GraphRAG。VectorRAG侧重于语义相似度,能够捕捉文献中隐含的关联。GraphRAG则侧重于结构化知识,能够进行精确的推理和知识融合。这两种方法各有优势,可以互补使用。
关键设计:在VectorRAG中,关键设计包括如何构建高质量的段落嵌入,以及如何选择合适的相似度度量方法。在GraphRAG中,关键设计包括如何进行实体消歧,如何构建规范化的知识图谱,以及如何设计多跳推理算法。论文使用了超过1000篇聚羟基脂肪酸酯(PHA)论文构建知识库,并进行了详细的实验评估。
🖼️ 关键图片
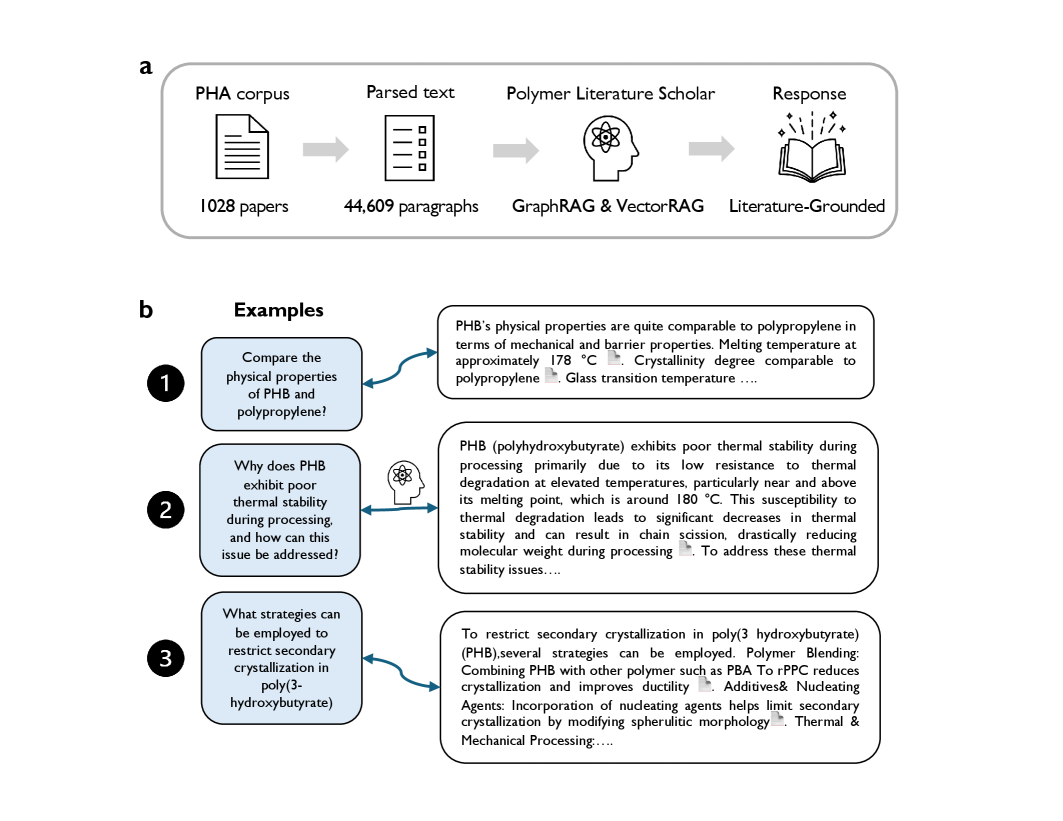
📊 实验亮点
实验结果表明,GraphRAG在精度和可解释性方面优于VectorRAG,而VectorRAG具有更广的召回率。领域专家验证表明,GraphRAG能够生成基于证据、引文可靠且具有领域相关性的响应。与通用LLM(如GPT和Gemini)相比,定制的RAG管道在聚合物知识提取方面表现更佳。
🎯 应用场景
该研究成果可应用于构建智能材料科学助手,帮助研究人员快速检索、比较和分析聚合物文献,发现新的研究方向和规律。通过减少对专有模型的依赖,并提供可信赖的文献分析,该方法有望加速新材料的研发进程。
📄 摘要(原文)
Polymer literature contains a large and growing body of experimental knowledge, yet much of it is buried in unstructured text and inconsistent terminology, making systematic retrieval and reasoning difficult. Existing tools typically extract narrow, study-specific facts in isolation, failing to preserve the cross-study context required to answer broader scientific questions. Retrieval-augmented generation (RAG) offers a promising way to overcome this limitation by combining large language models (LLMs) with external retrieval, but its effectiveness depends strongly on how domain knowledge is represented. In this work, we develop two retrieval pipelines: a dense semantic vector-based approach (VectorRAG) and a graph-based approach (GraphRAG). Using over 1,000 polyhydroxyalkanoate (PHA) papers, we construct context-preserving paragraph embeddings and a canonicalized structured knowledge graph supporting entity disambiguation and multi-hop reasoning. We evaluate these pipelines through standard retrieval metrics, comparisons with general state-of-the-art systems such as GPT and Gemini, and qualitative validation by a domain chemist. The results show that GraphRAG achieves higher precision and interpretability, while VectorRAG provides broader recall, highlighting complementary trade-offs. Expert validation further confirms that the tailored pipelines, particularly GraphRAG, produce well-grounded, citation-reliable responses with strong domain relevance. By grounding every statement in evidence, these systems enable researchers to navigate the literature, compare findings across studies, and uncover patterns that are difficult to extract manually. More broadly, this work establishes a practical framework for building materials science assistants using curated corpora and retrieval design, reducing reliance on proprietary models while enabling trustworthy literature analysis at scale.