FlowPrefill: Decoupling Preemption from Prefill Scheduling Granularity to Mitigate Head-of-Line Blocking in LLM Serving
作者: Chia-chi Hsieh, Zan Zong, Xinyang Chen, Jianjiang Li, Jidong Zhai, Lijie Wen
分类: cs.DC, cs.AI
发布日期: 2026-02-18
备注: 13 pages
💡 一句话要点
FlowPrefill:解耦抢占与预填充调度粒度,缓解LLM服务中的队头阻塞
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM服务 队头阻塞 预填充调度 抢占机制 服务质量优化
📋 核心要点
- LLM服务中,预填充阶段的队头阻塞导致高优先级请求延迟,现有分块预填充方法在响应性和吞吐量之间存在权衡。
- FlowPrefill通过解耦抢占粒度与调度频率,实现算子级抢占和事件驱动调度,从而优化TTFT和吞吐量。
- 实验表明,FlowPrefill在满足异构SLO的同时,最大goodput相比现有系统提升高达5.6倍。
📝 摘要(中文)
大型语言模型(LLM)日益增长的需求要求服务系统处理具有不同服务级别目标(SLO)的多个并发请求。这加剧了计算密集型预填充阶段的队头(HoL)阻塞,其中长时间运行的请求垄断资源并延迟更高优先级的请求,导致广泛的首个token时间(TTFT)SLO违规。虽然分块预填充实现了可中断性,但它引入了响应性和吞吐量之间的固有权衡:减小块大小可改善响应延迟,但会降低计算效率,而增大块大小可最大程度地提高吞吐量,但会加剧阻塞。这需要一种自适应抢占机制。然而,动态平衡执行粒度与调度开销仍然是一个关键挑战。本文提出了FlowPrefill,一种TTFT-goodput优化的服务系统,通过解耦抢占粒度与调度频率来解决此冲突。为了实现自适应预填充调度,FlowPrefill引入了两项关键创新:1) 算子级抢占,它利用算子边界来实现细粒度的执行中断,而不会造成与固定小块相关的效率损失;2) 事件驱动调度,它仅在请求到达或完成事件时触发调度决策,从而支持高效的抢占响应性,同时最大限度地减少控制平面开销。在真实生产跟踪上的评估表明,与最先进的系统相比,FlowPrefill将最大goodput提高了高达5.6倍,同时满足了异构SLO。
🔬 方法详解
问题定义:大型语言模型服务中,预填充阶段的队头阻塞问题严重影响服务质量。现有方法,如分块预填充,虽然可以实现中断,但需要在响应速度和吞吐量之间进行权衡。小块尺寸降低延迟但降低效率,大块尺寸提高吞吐量但加剧阻塞。因此,需要一种自适应的抢占机制,但动态平衡执行粒度与调度开销是一个挑战。
核心思路:FlowPrefill的核心思路是将抢占的粒度与调度的频率解耦。通过更细粒度的抢占(算子级)来提高响应性,同时通过更低频率的调度(事件驱动)来减少调度开销。这样可以在保证高吞吐量的同时,降低高优先级请求的延迟。
技术框架:FlowPrefill包含两个主要组件:算子级抢占和事件驱动调度。当有新的请求到达或现有请求完成时,事件驱动调度器会根据请求的优先级和服务级别目标(SLO)来决定是否需要抢占当前正在执行的请求。如果需要抢占,则在当前算子执行完成后进行抢占,而不是强制中断。
关键创新:FlowPrefill的关键创新在于算子级抢占和事件驱动调度。算子级抢占允许更细粒度的中断,避免了固定大小分块带来的效率损失。事件驱动调度减少了调度频率,降低了控制平面开销,同时保持了对高优先级请求的快速响应。
关键设计:FlowPrefill的关键设计包括:1) 算子边界的确定,需要仔细分析LLM的计算图,选择合适的算子作为抢占点;2) 事件驱动调度器的设计,需要考虑请求的优先级、SLO以及系统资源利用率等因素,制定合理的调度策略;3) 抢占开销的控制,需要尽量减少抢占带来的额外计算和内存开销。
🖼️ 关键图片
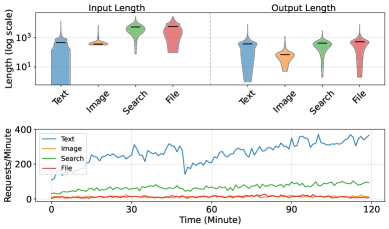
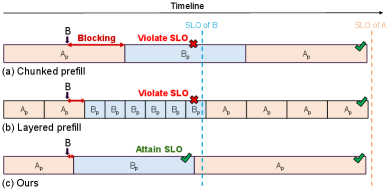
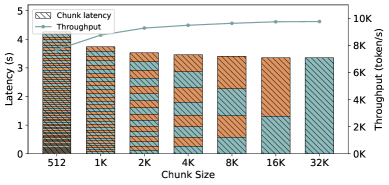
📊 实验亮点
FlowPrefill在真实生产跟踪上的评估表明,与最先进的系统相比,FlowPrefill将最大goodput提高了高达5.6倍,同时满足了异构SLO。这表明FlowPrefill能够有效地解决LLM服务中的队头阻塞问题,并在保证服务质量的同时提高系统吞吐量。
🎯 应用场景
FlowPrefill适用于需要处理大量并发请求且具有不同服务级别目标(SLO)的大型语言模型服务系统。它可以提高系统的吞吐量和响应速度,保证高优先级请求的低延迟,从而提升用户体验和资源利用率。该技术也可应用于其他计算密集型服务,如视频处理、科学计算等。
📄 摘要(原文)
The growing demand for large language models (LLMs) requires serving systems to handle many concurrent requests with diverse service level objectives (SLOs). This exacerbates head-of-line (HoL) blocking during the compute-intensive prefill phase, where long-running requests monopolize resources and delay higher-priority ones, leading to widespread time-to-first-token (TTFT) SLO violations. While chunked prefill enables interruptibility, it introduces an inherent trade-off between responsiveness and throughput: reducing chunk size improves response latency but degrades computational efficiency, whereas increasing chunk size maximizes throughput but exacerbates blocking. This necessitates an adaptive preemption mechanism. However, dynamically balancing execution granularity against scheduling overheads remains a key challenge. In this paper, we propose FlowPrefill, a TTFT-goodput-optimized serving system that resolves this conflict by decoupling preemption granularity from scheduling frequency. To achieve adaptive prefill scheduling, FlowPrefill introduces two key innovations: 1) Operator-Level Preemption, which leverages operator boundaries to enable fine-grained execution interruption without the efficiency loss associated with fixed small chunking; and 2) Event-Driven Scheduling, which triggers scheduling decisions only upon request arrival or completion events, thereby supporting efficient preemption responsiveness while minimizing control-plane overhead. Evaluation on real-world production traces shows that FlowPrefill improves maximum goodput by up to 5.6$\times$ compared to state-of-the-art systems while satisfying heterogeneous SLOs.