Creating a digital poet
作者: Vered Tohar, Tsahi Hayat, Amir Leshem
分类: cs.AI, cs.CL
发布日期: 2026-02-18
备注: 24 pages, 3 figures
💡 一句话要点
通过工作坊式Prompt工程,塑造大型语言模型为数字诗人,并成功出版诗集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 诗歌生成 Prompt工程 人机协作 创造性AI
📋 核心要点
- 现有方法难以使大型语言模型在诗歌创作中形成稳定风格和连贯语料库,缺乏长期创造性塑造。
- 通过模拟诗歌工作坊,利用专家反馈迭代优化Prompt,引导模型发展独特风格并创作诗歌。
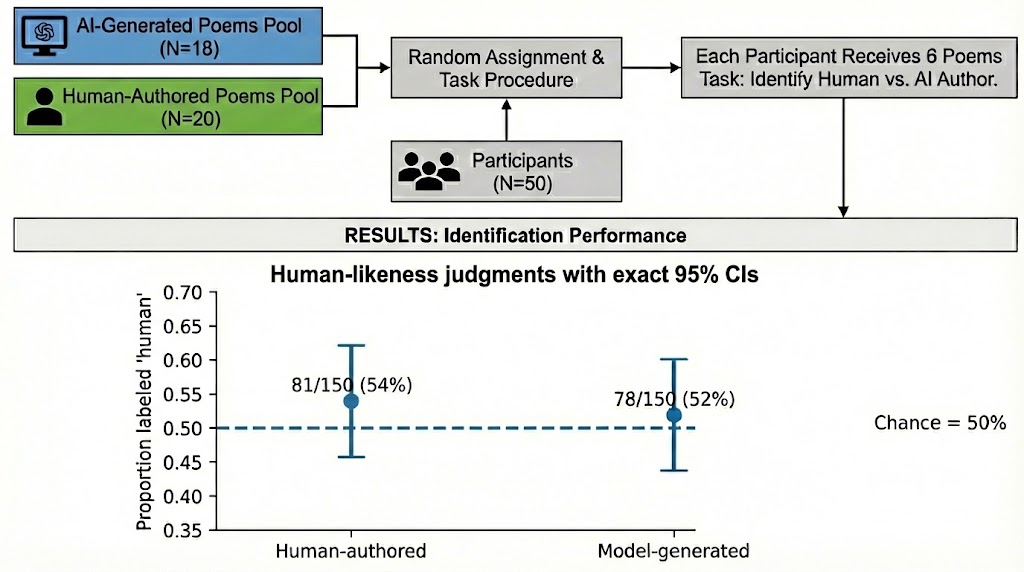
- 盲测实验表明,人类难以区分AI和人类诗歌,模型成功出版诗集,验证了方法有效性。
📝 摘要(中文)
本文探讨了机器创作优秀诗歌的可能性。研究报告描述了一个为期七个月的诗歌工作坊,其中一个大型语言模型通过迭代式的上下文专家反馈被塑造成一位数字诗人,而无需重新训练。在整个过程中,该模型发展出独特的风格和连贯的语料库,并通过定量和定性分析加以支持。它还生成了一个笔名和作者图像。在一项针对50名人文专业学生和毕业生的盲法作者身份测试中(每位参与者阅读三首AI诗歌和三首知名诗人诗歌),判断结果完全随机:人类诗歌被标记为人类诗歌的概率为54%,AI诗歌为52%,95%置信区间均包含50%。工作坊结束后,一家商业出版社出版了该模型创作的诗集。这些结果表明,工作坊式的prompt工程可以支持长期的创造性塑造,并引发关于创造力和作者身份的新讨论。
🔬 方法详解
问题定义:该论文旨在探索如何利用大型语言模型创作高质量的诗歌,并使模型具备独特的创作风格和连贯的语料库。现有方法通常依赖于预训练和微调,难以在创作过程中进行灵活的风格控制和长期塑造,缺乏人类专家参与的迭代式反馈机制。
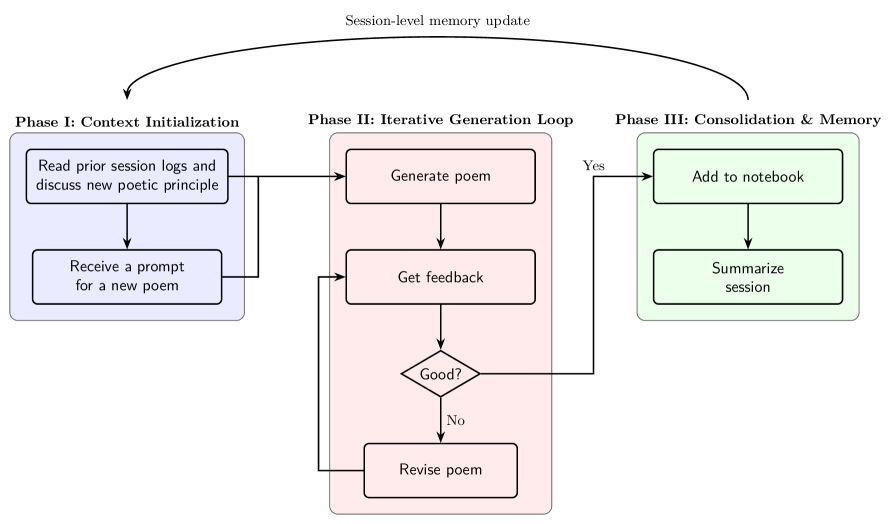
核心思路:论文的核心思路是将大型语言模型视为一个“数字诗人”,通过模拟人类诗歌工作坊的形式,利用专家反馈进行迭代式的Prompt工程,从而在不重新训练模型的情况下,引导模型发展出独特的诗歌风格和连贯的语料库。这种方法强调了人类专家在塑造模型创造性能力中的作用。
技术框架:整体框架是一个迭代式的Prompt工程流程,包含以下主要阶段:1) 初始Prompt设计:设计包含诗歌创作目标、风格要求等信息的初始Prompt。2) 模型生成:利用大型语言模型生成诗歌草稿。3) 专家反馈:诗歌专家对生成的诗歌进行评估,并提供修改意见和建议。4) Prompt优化:根据专家反馈,迭代优化Prompt,例如修改Prompt中的关键词、调整风格描述等。5) 循环迭代:重复步骤2-4,直到模型生成满意的诗歌作品。
关键创新:该论文的关键创新在于将Prompt工程与人类专家反馈相结合,形成了一种工作坊式的创作模式。这种模式允许在不重新训练模型的情况下,对模型的创作风格进行长期塑造和迭代优化。与传统的预训练和微调方法相比,该方法更加灵活和可控。
关键设计:论文的关键设计包括:1) Prompt的设计:Prompt需要包含清晰的创作目标、风格描述和约束条件,以引导模型生成符合要求的诗歌。2) 专家反馈机制:专家需要提供详细的修改意见和建议,包括诗歌的结构、韵律、意象等方面。3) 迭代优化策略:需要设计有效的Prompt优化策略,例如基于专家反馈修改Prompt中的关键词、调整风格描述等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在盲测中,人类参与者无法有效区分AI生成的诗歌和人类创作的诗歌,准确率接近随机水平(AI诗歌52%,人类诗歌54%)。更重要的是,该模型成功出版了一本诗集,这证明了其创作能力达到了商业出版水平,也进一步验证了工作坊式Prompt工程的有效性。
🎯 应用场景
该研究成果可应用于自动化诗歌创作、个性化内容生成、创意写作辅助工具等领域。通过工作坊式Prompt工程,可以引导AI模型在艺术创作领域发挥更大作用,并为人类提供新的创作灵感。此外,该方法也为其他领域的AI内容生成提供了借鉴,例如音乐、绘画等。
📄 摘要(原文)
Can a machine write good poetry? Any positive answer raises fundamental questions about the nature and value of art. We report a seven-month poetry workshop in which a large language model was shaped into a digital poet through iterative in-context expert feedback, without retraining. Across sessions, the model developed a distinctive style and a coherent corpus, supported by quantitative and qualitative analyses, and it produced a pen name and author image. In a blinded authorship test with 50 humanities students and graduates (three AI poems and three poems by well-known poets each), judgments were at chance: human poems were labeled human 54% of the time and AI poems 52%, with 95% confidence intervals including 50%. After the workshop, a commercial publisher released a poetry collection authored by the model. These results show that workshop-style prompting can support long-horizon creative shaping and renew debates on creativity and authorship.