Leveraging Large Language Models for Causal Discovery: a Constraint-based, Argumentation-driven Approach
作者: Zihao Li, Fabrizio Russo
分类: cs.AI
发布日期: 2026-02-18
备注: 26 pages, including appendix
💡 一句话要点
提出基于大语言模型的因果发现方法,结合约束推理和论证驱动,提升因果关系推断准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果发现 大语言模型 约束推理 论证驱动 语义知识 因果图 条件独立性
📋 核心要点
- 现有因果发现方法依赖专家知识或统计方法,难以有效结合数据和领域知识,且对数据质量敏感。
- 利用大语言模型(LLM)的语义理解能力,提取变量名称和描述中的结构先验知识,辅助因果关系推断。
- 实验结果表明,该方法在标准基准和合成数据集上均取得了优异的性能,并提出了缓解LLM记忆偏差的评估方案。
📝 摘要(中文)
因果发现旨在从数据中揭示因果关系,通常表示为因果图,对于预测干预措施的效果至关重要。虽然构建有原则的因果图需要专家知识,但许多统计方法已被提出,以利用具有不同形式保证的观测数据。基于因果假设的论证(ABA)是一个使用符号推理来确保输入约束和输出图之间对应关系的框架,同时提供了一种结合数据和专业知识的原则性方法。我们探索使用大型语言模型(LLM)作为因果ABA的不完美专家,从变量名称和描述中提取语义结构先验,并将其与条件独立性证据相结合。在标准基准和语义接地的合成图上的实验表明了最先进的性能,并且我们还引入了一种评估协议,以减轻在评估LLM进行因果发现时的记忆偏差。
🔬 方法详解
问题定义:论文旨在解决如何有效利用大语言模型(LLM)的语义知识来提升因果发现的准确性。现有因果发现方法通常依赖于统计数据或专家知识,难以有效地融合两者。统计方法对数据质量要求高,而专家知识的获取成本高昂且可能存在偏差。因此,如何利用LLM作为一种“不完美专家”,从变量名称和描述中提取有用的因果结构先验知识,是一个重要的挑战。
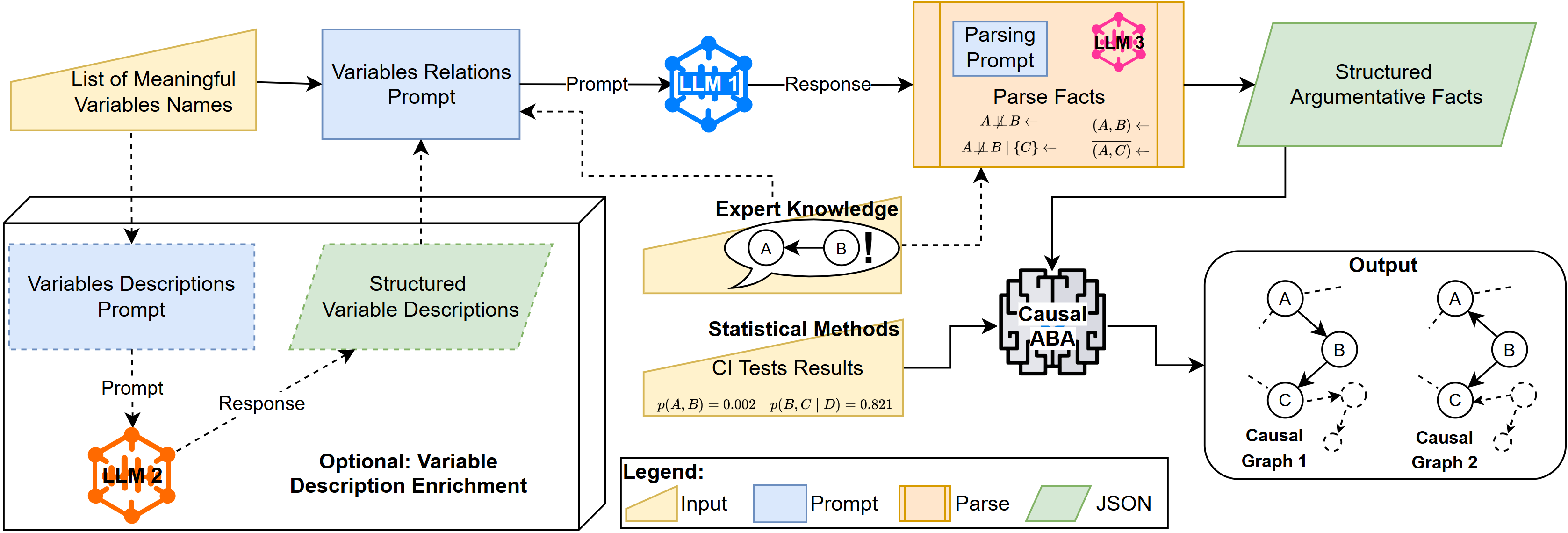
核心思路:论文的核心思路是利用LLM的语义理解能力,从变量的名称和描述中提取因果关系的先验知识,并将其融入到基于约束的因果发现框架中。具体来说,论文将LLM视为一个“不完美专家”,通过提示工程(prompt engineering)来引导LLM生成关于变量之间因果关系的假设。这些假设随后被转化为约束条件,用于指导因果图的搜索过程。
技术框架:论文采用基于因果假设的论证(Causal Assumption-based Argumentation, ABA)框架,该框架允许将数据证据和专家知识以一种原则性的方式结合起来。整体流程如下:1) 使用LLM生成关于变量之间因果关系的假设;2) 将这些假设转化为ABA框架中的约束条件;3) 利用条件独立性测试等统计方法从数据中获取证据;4) 使用ABA框架进行推理,生成最终的因果图。
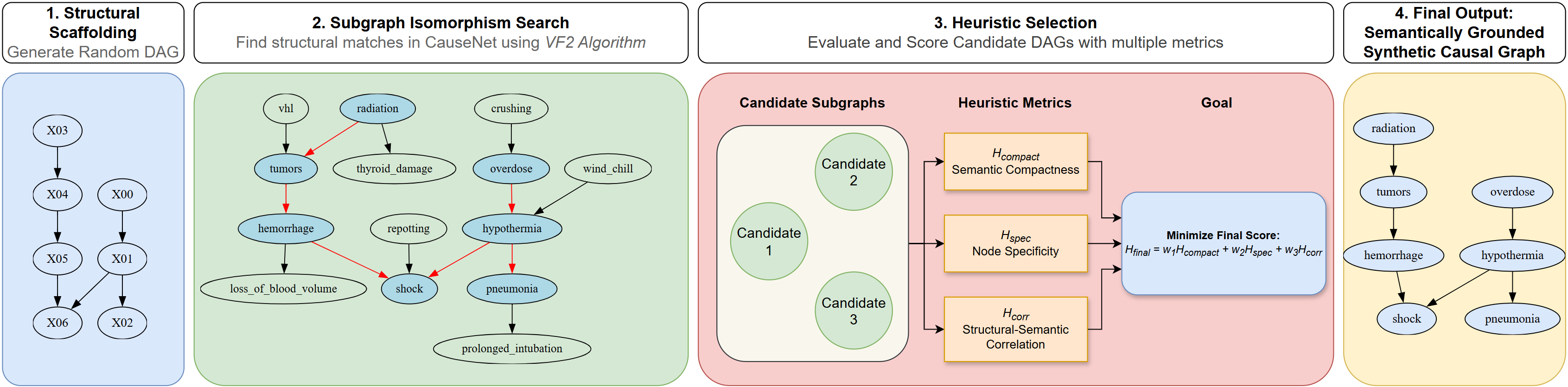
关键创新:论文的关键创新在于将LLM的语义知识融入到因果发现过程中,并提出了一种缓解LLM记忆偏差的评估方案。通过利用LLM的语义理解能力,该方法可以有效地利用变量名称和描述中蕴含的因果信息,从而提高因果发现的准确性。此外,论文还提出了一种新的评估协议,用于评估LLM在因果发现任务中的表现,并减轻了记忆偏差的影响。
关键设计:论文的关键设计包括:1) 使用特定的提示工程技术来引导LLM生成因果假设;2) 将LLM生成的假设转化为ABA框架中的约束条件;3) 使用条件独立性测试等统计方法从数据中获取证据;4) 设计了一种新的评估协议,用于评估LLM在因果发现任务中的表现,该协议通过生成语义接地的合成图来减轻记忆偏差的影响。
🖼️ 关键图片
📊 实验亮点
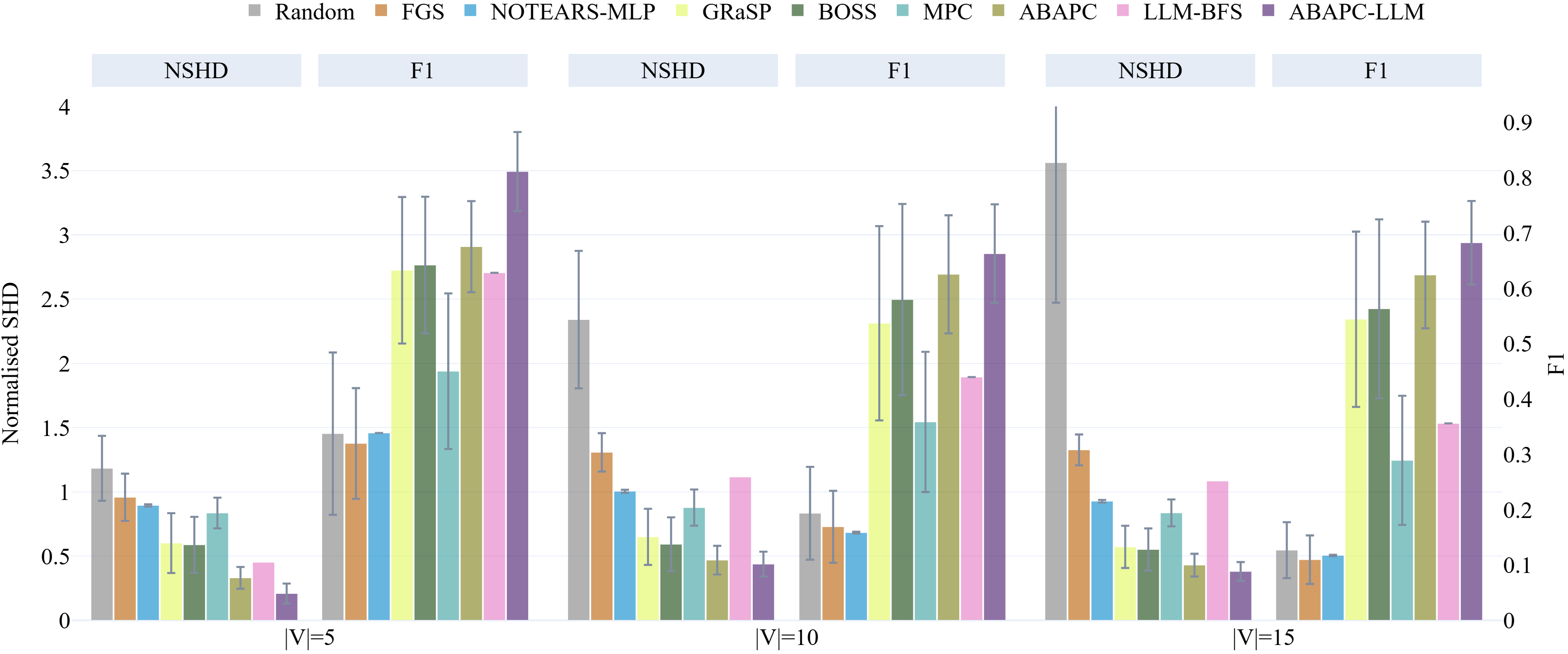
实验结果表明,该方法在标准基准数据集和语义接地的合成数据集上均取得了state-of-the-art的性能。与传统的因果发现方法相比,该方法能够更有效地利用变量名称和描述中蕴含的因果信息,从而提高因果发现的准确性。此外,论文提出的评估协议能够有效地减轻LLM的记忆偏差,使得评估结果更加可靠。
🎯 应用场景
该研究成果可应用于医疗健康、金融风控、智能推荐等领域,帮助人们更好地理解复杂系统中的因果关系,从而做出更明智的决策。例如,在医疗领域,可以利用该方法发现疾病的潜在病因,为精准医疗提供支持。在金融领域,可以用于识别影响金融风险的关键因素,提高风险预测的准确性。
📄 摘要(原文)
Causal discovery seeks to uncover causal relations from data, typically represented as causal graphs, and is essential for predicting the effects of interventions. While expert knowledge is required to construct principled causal graphs, many statistical methods have been proposed to leverage observational data with varying formal guarantees. Causal Assumption-based Argumentation (ABA) is a framework that uses symbolic reasoning to ensure correspondence between input constraints and output graphs, while offering a principled way to combine data and expertise. We explore the use of large language models (LLMs) as imperfect experts for Causal ABA, eliciting semantic structural priors from variable names and descriptions and integrating them with conditional-independence evidence. Experiments on standard benchmarks and semantically grounded synthetic graphs demonstrate state-of-the-art performance, and we additionally introduce an evaluation protocol to mitigate memorisation bias when assessing LLMs for causal discovery.