Causally-Guided Automated Feature Engineering with Multi-Agent Reinforcement Learning
作者: Arun Vignesh Malarkkan, Wangyang Ying, Yanjie Fu
分类: cs.AI, cs.LG, cs.MA
发布日期: 2026-02-18
备注: 11 Pages, References and Appendix
💡 一句话要点
CAFE:利用因果引导的多智能体强化学习实现自动化特征工程,提升泛化性和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动化特征工程 因果推理 强化学习 多智能体系统 数据分布偏移
📋 核心要点
- 现有自动化特征工程方法依赖统计启发式,导致生成的特征在数据分布变化时表现不佳,缺乏鲁棒性。
- CAFE框架将自动化特征工程视为一个因果引导的序列决策过程,利用因果发现和强化学习相结合的方式构建特征。
- 实验结果表明,CAFE在多个基准测试中优于现有方法,尤其是在数据分布偏移的情况下,性能提升显著。
📝 摘要(中文)
自动化特征工程(AFE)旨在从原始表格数据中自主构建高效的特征表示。然而,现有的AFE方法依赖于统计启发式,导致特征脆弱且在分布偏移下失效。我们提出了CAFE,一个将AFE重构为因果引导的序列决策过程的框架,连接了因果发现和强化学习驱动的特征构建。第一阶段学习特征和目标之间的稀疏有向无环图,以获得软因果先验,根据特征对目标的影响将其分为直接、间接或其他组。第二阶段使用级联多智能体深度Q学习架构来选择因果组和转换算子,采用分层奖励塑造和因果组级别的探索策略,在控制特征复杂性的同时,倾向于因果上合理的转换。在15个公共基准测试中(宏F1分类;逆相对绝对误差回归),CAFE比强大的AFE基线提高了高达7%,减少了收敛所需的episode数,并提供了具有竞争力的目标时间。在受控的协变量偏移下,CAFE相对于非因果多智能体基线,性能下降减少了约4倍,并产生了更紧凑的特征集,具有更稳定的事后归因。这些发现强调,因果结构作为一种软归纳先验而非刚性约束,可以显著提高自动化特征工程的鲁棒性和效率。
🔬 方法详解
问题定义:论文旨在解决自动化特征工程(AFE)中,现有方法依赖统计启发式而导致的特征脆弱性问题。这些特征在面对数据分布偏移时泛化能力差,无法保证模型性能的稳定性。因此,需要一种更鲁棒、更高效的AFE方法。
核心思路:论文的核心思路是将因果推理引入到AFE过程中,利用因果结构作为一种软归纳偏置,指导特征的构建。通过学习特征与目标变量之间的因果关系,可以筛选出更具信息量和鲁棒性的特征,从而提高模型在不同数据分布下的泛化能力。
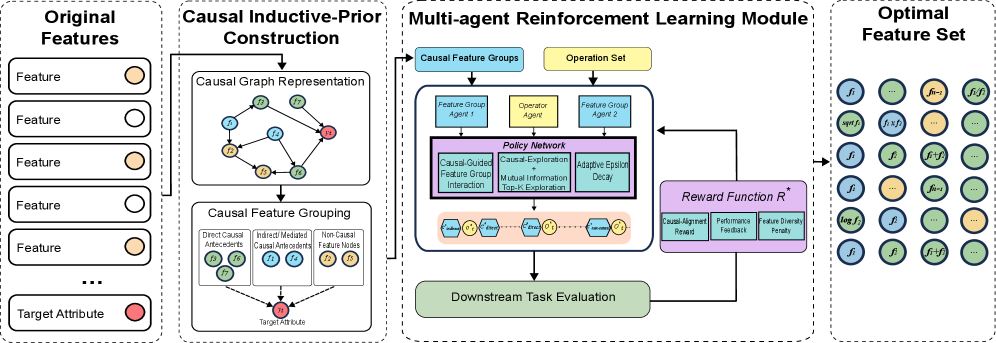
技术框架:CAFE框架包含两个主要阶段:第一阶段是因果发现阶段,利用因果发现算法学习特征和目标变量之间的稀疏有向无环图(DAG),从而获得软因果先验。第二阶段是特征构建阶段,采用级联多智能体深度Q学习架构,根据第一阶段得到的因果关系,选择合适的特征组和转换算子进行特征构建。
关键创新:该论文最重要的创新点在于将因果推理与强化学习相结合,用于自动化特征工程。与传统的基于统计启发式的AFE方法不同,CAFE利用因果结构指导特征的选择和转换,从而提高了特征的鲁棒性和泛化能力。此外,CAFE还采用了分层奖励塑造和因果组级别的探索策略,进一步优化了特征构建过程。
关键设计:在因果发现阶段,论文使用了GES算法学习DAG结构。在特征构建阶段,采用了多智能体深度Q学习架构,每个智能体负责选择一个因果组或转换算子。奖励函数的设计采用了分层结构,包括即时奖励和延迟奖励,以鼓励智能体选择因果上合理的转换。探索策略则侧重于因果组级别的探索,以提高探索效率。
🖼️ 关键图片
📊 实验亮点
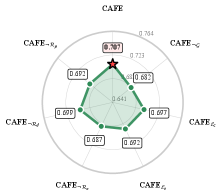
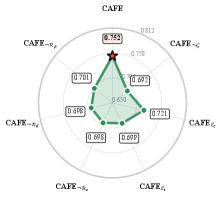
CAFE在15个公共基准测试中,相比于强大的AFE基线,性能提升高达7%。在受控的协变量偏移下,CAFE的性能下降幅度比非因果多智能体基线减少了约4倍。此外,CAFE还能够生成更紧凑的特征集,并提供更稳定的事后归因,表明其生成的特征更具解释性和鲁棒性。
🎯 应用场景
CAFE框架可应用于各种需要从表格数据中进行特征工程的领域,例如金融风控、医疗诊断、推荐系统等。通过自动构建鲁棒性强的特征,可以提高模型的性能和稳定性,降低人工特征工程的成本,并加速AI应用的开发和部署。尤其是在数据分布可能发生变化的场景下,CAFE的优势更为明显。
📄 摘要(原文)
Automated feature engineering (AFE) enables AI systems to autonomously construct high-utility representations from raw tabular data. However, existing AFE methods rely on statistical heuristics, yielding brittle features that fail under distribution shift. We introduce CAFE, a framework that reformulates AFE as a causally-guided sequential decision process, bridging causal discovery with reinforcement learning-driven feature construction. Phase I learns a sparse directed acyclic graph over features and the target to obtain soft causal priors, grouping features as direct, indirect, or other based on their causal influence with respect to the target. Phase II uses a cascading multi-agent deep Q-learning architecture to select causal groups and transformation operators, with hierarchical reward shaping and causal group-level exploration strategies that favor causally plausible transformations while controlling feature complexity. Across 15 public benchmarks (classification with macro-F1; regression with inverse relative absolute error), CAFE achieves up to 7% improvement over strong AFE baselines, reduces episodes-to-convergence, and delivers competitive time-to-target. Under controlled covariate shifts, CAFE reduces performance drop by ~4x relative to a non-causal multi-agent baseline, and produces more compact feature sets with more stable post-hoc attributions. These findings underscore that causal structure, used as a soft inductive prior rather than a rigid constraint, can substantially improve the robustness and efficiency of automated feature engineering.