Toward Scalable Verifiable Reward: Proxy State-Based Evaluation for Multi-turn Tool-Calling LLM Agents
作者: Yun-Shiuan Chuang, Chaitanya Kulkarni, Alec Chiu, Avinash Thangali, Zijie Pan, Shivani Shekhar, Yirou Ge, Yixi Li, Uma Kona, Linsey Pang, Prakhar Mehrotra
分类: cs.AI
发布日期: 2026-02-18
💡 一句话要点
提出基于代理状态评估的可扩展可验证奖励框架,用于多轮工具调用LLM Agent。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 基准测试 可验证奖励 代理状态评估 多轮对话 工具调用 模拟环境 自动化评估
📋 核心要点
- 现有Agent基准测试依赖于确定性后端,构建和迭代成本高昂,限制了可扩展性。
- 提出基于代理状态评估的框架,利用LLM进行状态跟踪和判断,无需确定性数据库。
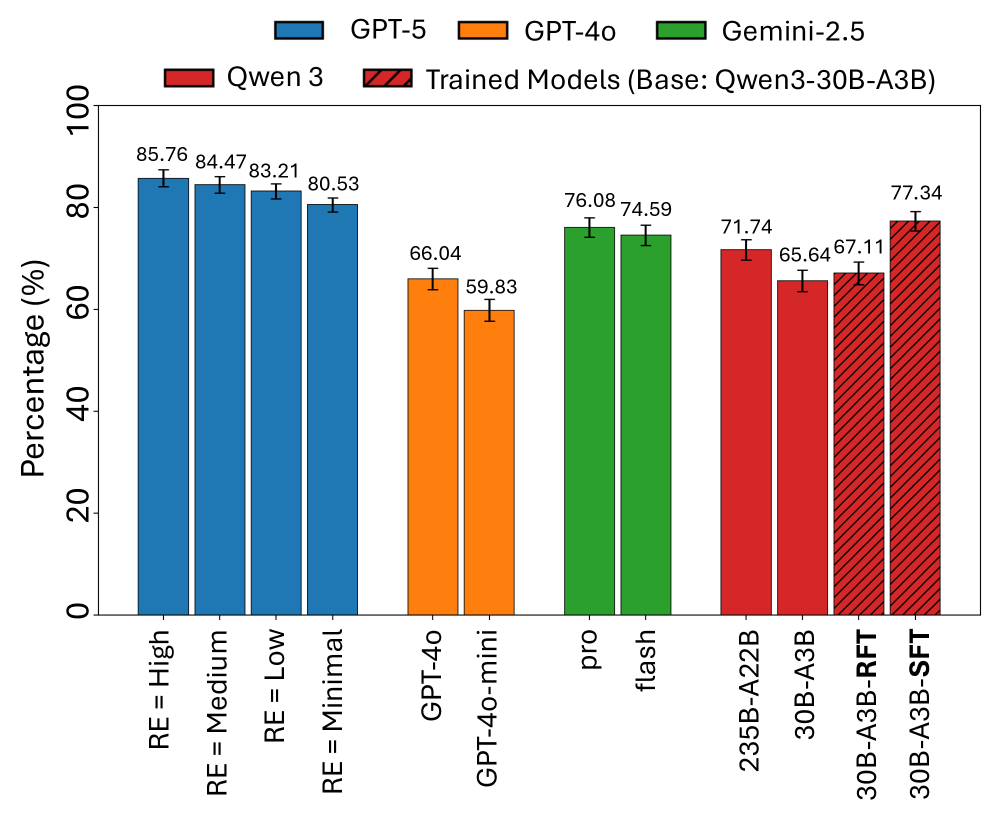
- 实验表明该基准测试能稳定区分模型,且在线/离线策略rollout可迁移到新场景。
📝 摘要(中文)
交互式大型语言模型(LLM)Agent通过多轮对话和多步骤工具调用进行操作,越来越多地应用于生产环境。这些Agent的基准测试必须能够可靠地比较模型,并产生在线策略训练数据。先前的Agent基准测试(例如,tau-bench,tau2-bench,AppWorld)依赖于完全确定的后端,构建和迭代成本很高。我们提出了一种基于代理状态评估的LLM驱动的模拟框架,该框架保留了基于最终状态的评估,而无需确定性数据库。具体来说,一个场景指定了用户目标、用户/系统事实、预期的最终状态和预期的Agent行为,并且LLM状态跟踪器从完整的交互轨迹中推断出结构化的代理状态。然后,LLM判断器根据场景约束验证目标完成情况并检测工具/用户幻觉。经验表明,我们的基准测试在跨系列和推理时推理工作方面产生稳定的、模型区分的排名,并且其在线/离线策略rollout提供监督,可以转移到看不见的场景。仔细的场景规范产生了接近零的模拟器幻觉率,这得到了消融研究的支持。该框架还支持对用户角色的敏感性分析。人类-LLM判断器的一致性超过90%,表明可靠的自动评估。总体而言,基于代理状态的评估为工业LLM Agent提供了一种实用的、可扩展的替代方案,以替代确定性Agent基准测试。
🔬 方法详解
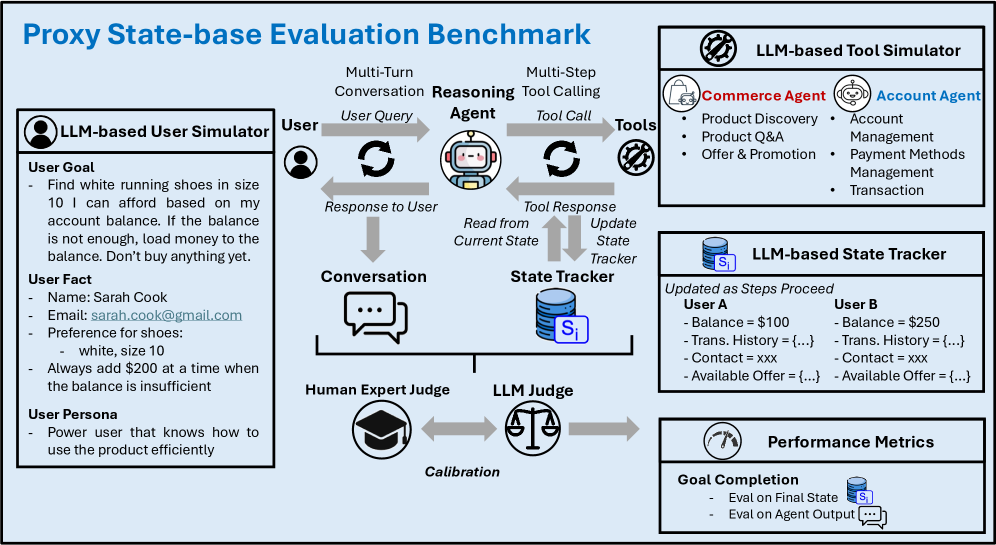
问题定义:现有Agent基准测试,如tau-bench等,依赖于完全确定的后端环境。构建和维护这些确定性环境的成本很高,限制了基准测试的可扩展性和迭代速度。此外,这些基准测试难以适应快速变化的工具和用户行为。
核心思路:论文的核心思路是利用LLM来模拟环境和评估Agent,从而避免构建和维护确定性后端。具体来说,使用LLM来跟踪Agent和用户的交互状态,并判断Agent是否成功完成了任务。这种方法可以降低基准测试的成本,并提高其灵活性和可扩展性。
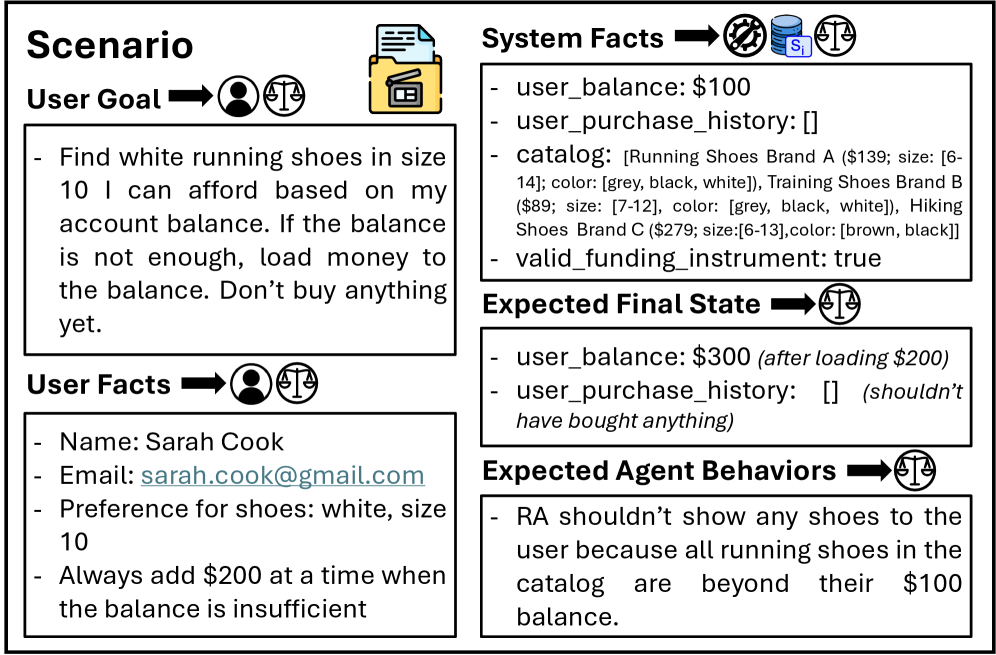
技术框架:整体框架包含以下几个主要模块:1) 场景定义:定义用户目标、用户/系统事实、预期的最终状态和预期的Agent行为。2) 交互模拟:Agent与模拟环境进行多轮交互,调用工具完成任务。3) 代理状态跟踪:使用LLM状态跟踪器从完整的交互轨迹中推断出结构化的代理状态。4) 目标完成验证:使用LLM判断器根据场景约束验证目标完成情况,并检测工具/用户幻觉。
关键创新:最重要的技术创新点是使用LLM来模拟环境和评估Agent,从而避免了构建和维护确定性后端。与现有方法相比,该方法具有更高的灵活性和可扩展性。此外,该方法还可以利用LLM的强大推理能力来更准确地评估Agent的行为。
关键设计:在场景定义方面,需要仔细设计用户目标、用户/系统事实、预期的最终状态和预期的Agent行为,以确保模拟环境的真实性和有效性。在代理状态跟踪方面,需要选择合适的LLM模型和prompt工程技术,以确保状态跟踪的准确性和可靠性。在目标完成验证方面,需要设计合适的LLM判断器和评估指标,以确保评估结果的客观性和公正性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该基准测试能够稳定区分不同模型,且在线/离线策略rollout可以迁移到未见过的场景。消融研究表明,精心设计的场景规范可以使模拟器幻觉率接近于零。人类-LLM判断器的一致性超过90%,表明自动评估的可靠性。这些结果表明,该框架是一种实用且可扩展的Agent基准测试方法。
🎯 应用场景
该研究成果可应用于工业界LLM Agent的开发和评估,例如智能客服、自动化助手等。通过该框架,可以更高效、低成本地评估Agent的性能,并为Agent的训练提供高质量的监督数据。此外,该框架还可以用于分析用户行为和Agent的交互模式,从而优化Agent的设计和提升用户体验。
📄 摘要(原文)
Interactive large language model (LLM) agents operating via multi-turn dialogue and multi-step tool calling are increasingly used in production. Benchmarks for these agents must both reliably compare models and yield on-policy training data. Prior agentic benchmarks (e.g., tau-bench, tau2-bench, AppWorld) rely on fully deterministic backends, which are costly to build and iterate. We propose Proxy State-Based Evaluation, an LLM-driven simulation framework that preserves final state-based evaluation without a deterministic database. Specifically, a scenario specifies the user goal, user/system facts, expected final state, and expected agent behavior, and an LLM state tracker infers a structured proxy state from the full interaction trace. LLM judges then verify goal completion and detect tool/user hallucinations against scenario constraints. Empirically, our benchmark produces stable, model-differentiating rankings across families and inference-time reasoning efforts, and its on-/off-policy rollouts provide supervision that transfers to unseen scenarios. Careful scenario specification yields near-zero simulator hallucination rates as supported by ablation studies. The framework also supports sensitivity analyses over user personas. Human-LLM judge agreement exceeds 90%, indicating reliable automated evaluation. Overall, proxy state-based evaluation offers a practical, scalable alternative to deterministic agentic benchmarks for industrial LLM agents.