Learning Personalized Agents from Human Feedback
作者: Kaiqu Liang, Julia Kruk, Shengyi Qian, Xianjun Yang, Shengjie Bi, Yuanshun Yao, Shaoliang Nie, Mingyang Zhang, Lijuan Liu, Jaime Fernández Fisac, Shuyan Zhou, Saghar Hosseini
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-18
💡 一句话要点
提出PAHF框架,通过人机交互在线学习个性化Agent,解决用户偏好动态变化问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 个性化Agent 人机交互 在线学习 用户偏好 显式记忆
📋 核心要点
- 现有AI Agent难以适应个体用户动态变化的偏好,依赖静态数据导致泛化性差,无法有效处理新用户和偏好漂移。
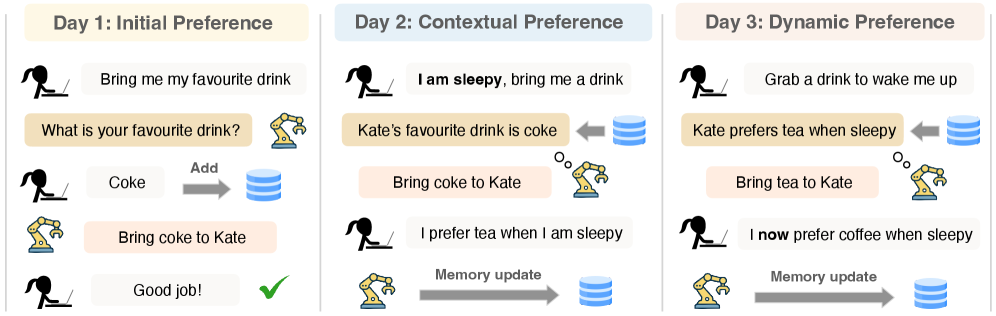
- PAHF框架通过显式用户记忆和在线学习,实现Agent对用户偏好的持续个性化,包含预先澄清、偏好检索和反馈更新三个步骤。
- 实验表明,PAHF在具身操作和在线购物任务中,学习速度更快,性能优于无记忆和单通道基线,能有效减少个性化误差。
📝 摘要(中文)
现代AI Agent功能强大,但通常难以与个体用户独特且不断变化的偏好保持一致。现有方法通常依赖静态数据集,要么在交互历史中训练隐式偏好模型,要么将用户配置文件编码到外部存储器中。然而,这些方法在新用户和随时间变化的偏好方面存在困难。我们引入了基于人类反馈的个性化Agent(PAHF),这是一个持续个性化的框架,其中Agent通过显式的用户记忆,从实时交互中在线学习。PAHF实现了三个步骤的循环:(1)寻求预先行动的澄清以消除歧义,(2)将行动建立在从记忆中检索到的偏好之上,以及(3)整合行动后的反馈以在偏好漂移时更新记忆。为了评估这种能力,我们开发了一个四阶段协议和两个在具身操作和在线购物中的基准。这些基准量化了Agent从头开始学习初始偏好并随后适应角色转变的能力。我们的理论分析和实验结果表明,将显式记忆与双反馈通道相结合至关重要:PAHF学习速度明显更快,并且始终优于无记忆和单通道基线,从而减少了初始个性化误差,并能够快速适应偏好转变。
🔬 方法详解
问题定义:现有AI Agent难以适应个体用户动态变化的偏好,主要痛点在于依赖静态数据集,无法有效处理新用户和用户偏好随时间的变化。隐式偏好模型难以捕捉细微的用户差异,而外部记忆方法则难以适应偏好的动态漂移。
核心思路:PAHF的核心思路是通过显式的用户记忆和在线学习,使Agent能够持续适应用户的个性化偏好。通过预先行动的澄清,Agent可以主动消除歧义,更好地理解用户意图。利用用户记忆存储和检索偏好信息,Agent可以根据用户的历史行为和反馈进行决策。通过整合行动后的反馈,Agent可以及时更新用户记忆,适应偏好的动态变化。
技术框架:PAHF框架包含三个主要步骤:(1) 预先行动澄清:Agent在执行动作前,向用户请求澄清,以消除歧义,更好地理解用户意图。(2) 偏好检索:Agent从用户记忆中检索相关的偏好信息,用于指导动作选择。(3) 反馈更新:Agent根据用户对动作的反馈,更新用户记忆,以适应偏好的动态变化。这三个步骤形成一个循环,使Agent能够持续学习和适应用户的个性化偏好。
关键创新:PAHF的关键创新在于将显式用户记忆与双反馈通道相结合。显式用户记忆能够存储和检索用户的个性化偏好信息,而双反馈通道(预先行动澄清和行动后反馈)能够提供更丰富的用户反馈信号。这种结合使得Agent能够更准确地理解用户意图,并及时适应偏好的动态变化。与现有方法相比,PAHF能够更好地处理新用户和偏好漂移问题。
关键设计:用户记忆采用键值对存储,键表示用户状态或情境,值表示用户偏好。预先行动澄清通过自然语言问题进行,例如“您是想要红色的还是蓝色的?”,答案用于更新用户记忆。行动后反馈可以是奖励信号或明确的偏好指示。损失函数包括偏好预测损失和反馈一致性损失,用于优化用户记忆的更新。
🖼️ 关键图片

📊 实验亮点
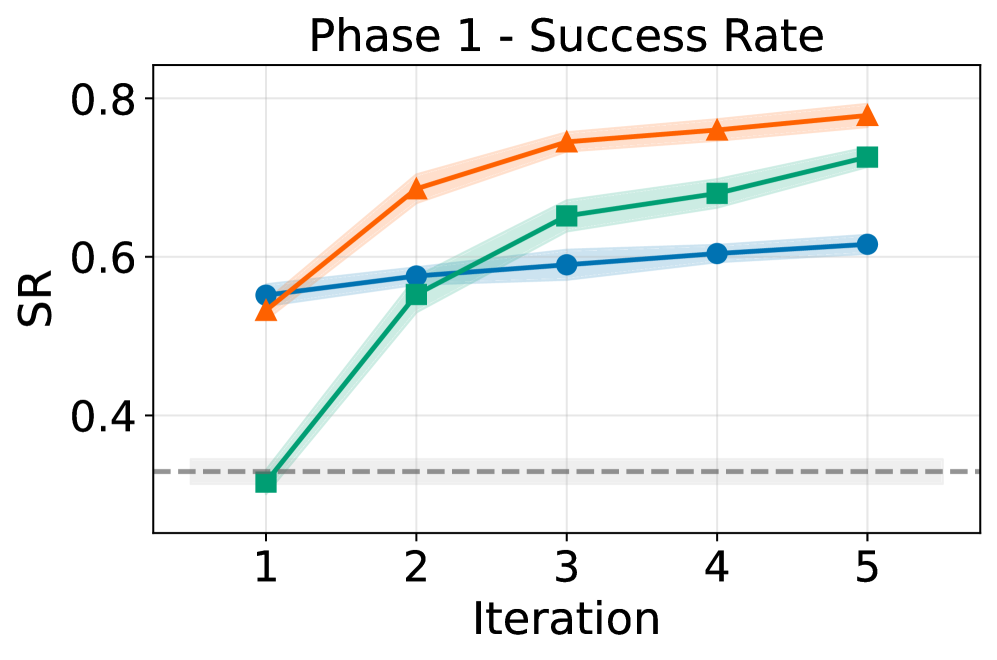
实验结果表明,PAHF在具身操作和在线购物任务中,学习速度明显快于无记忆和单通道基线。在初始个性化阶段,PAHF能够更快地学习用户的初始偏好,减少个性化误差。在偏好转变阶段,PAHF能够快速适应新的偏好,保持较高的性能水平。具体性能提升幅度未知,但实验结果一致表明PAHF优于其他基线方法。
🎯 应用场景
PAHF框架可应用于各种需要个性化交互的场景,例如智能家居、在线购物、个性化推荐、人机协作机器人等。通过学习用户的个性化偏好,Agent可以提供更符合用户需求的定制化服务,提升用户体验和满意度。该研究对于开发更智能、更人性化的AI Agent具有重要意义。
📄 摘要(原文)
Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.