Retrieval Collapses When AI Pollutes the Web
作者: Hongyeon Yu, Dongchan Kim, Young-Bum Kim
分类: cs.IR, cs.AI
发布日期: 2026-02-18
备注: 4 pages, Proceedings of The Web Conference 2026 (WWW '26)
💡 一句话要点
揭示AI污染Web内容导致检索崩溃的风险,并分析其传播机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索崩溃 AI污染 信息检索 大型语言模型 检索增强生成 对抗性攻击 搜索引擎
📋 核心要点
- 现有检索系统面临AI生成内容污染Web的挑战,导致检索结果同质化和低质量内容泛滥。
- 提出“检索崩溃”概念,分析AI生成内容如何通过SEO和对抗性攻击两种方式污染检索结果。
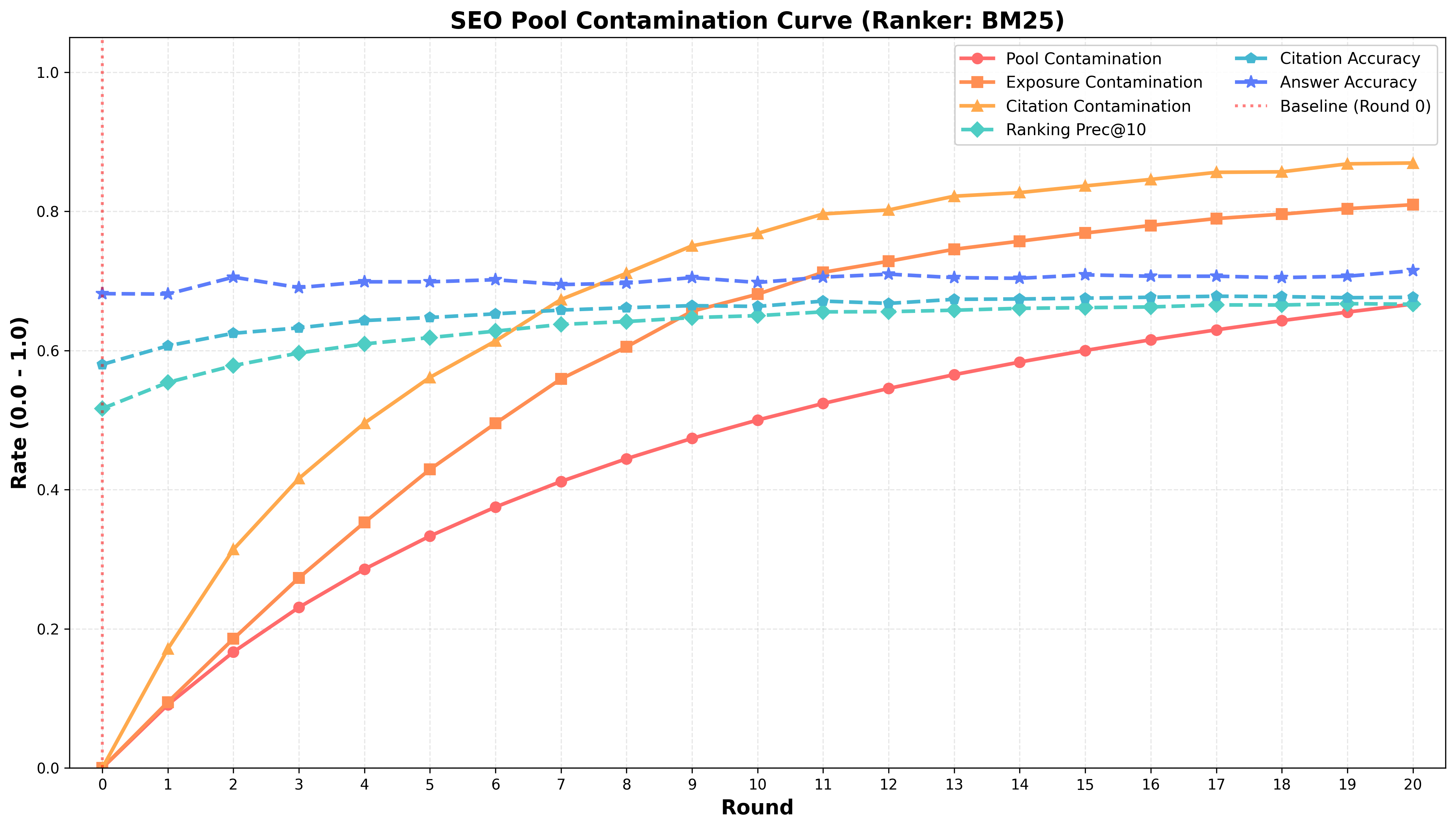
- 实验表明,AI污染会显著影响检索结果的质量和多样性,即使答案准确率表面上保持稳定。
📝 摘要(中文)
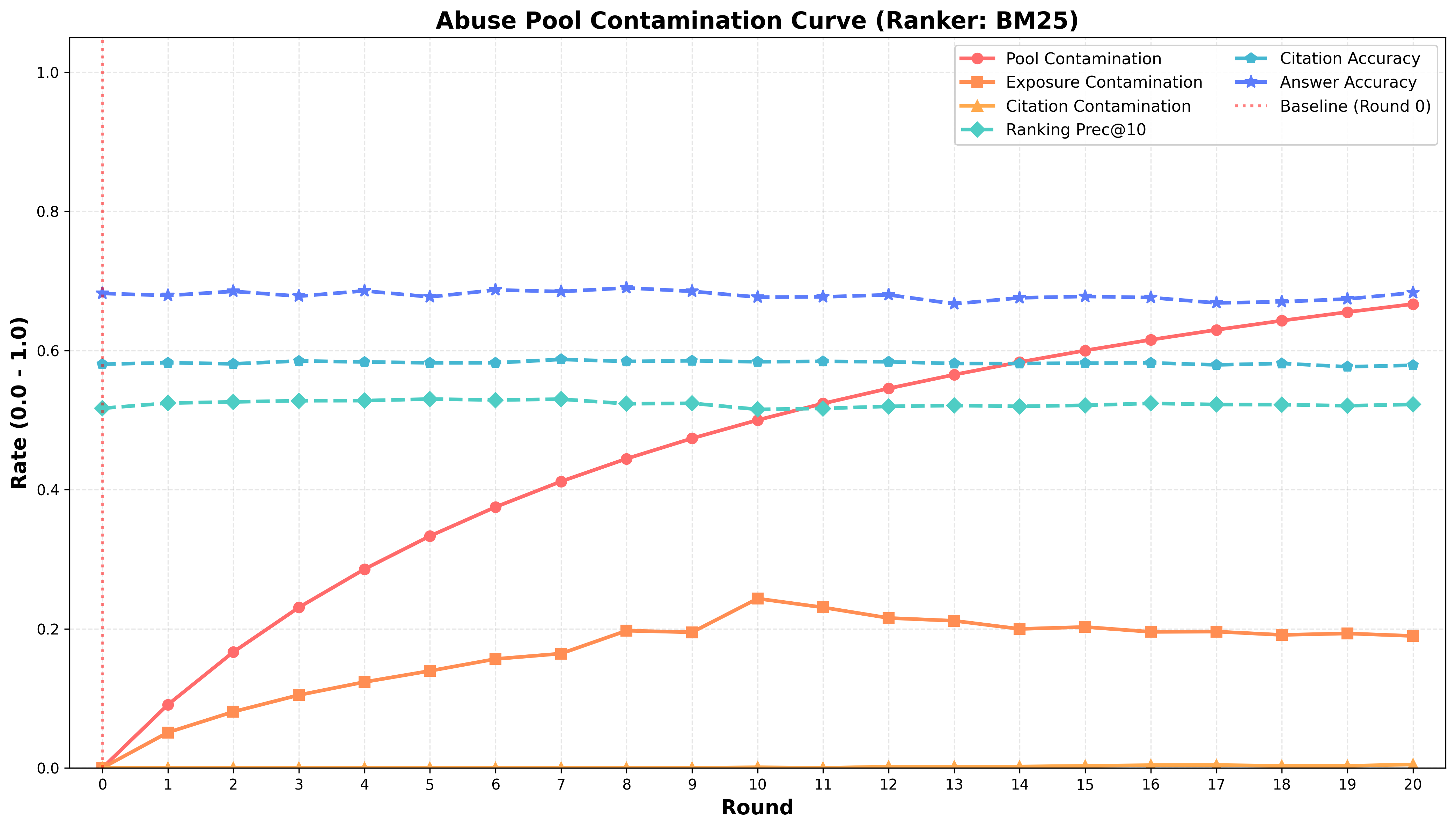
随着AI生成内容在Web上的迅速扩散,信息检索面临结构性风险,因为搜索引擎和检索增强生成(RAG)系统越来越多地使用大型语言模型(LLM)生成的内容作为证据。本文将这种生态系统层面的失效模式定义为检索崩溃,这是一个两阶段过程:(1) AI生成内容主导搜索结果,侵蚀来源多样性;(2) 低质量或对抗性内容渗透到检索流程中。通过受控实验,包括高质量SEO风格内容和对抗性制作内容,分析了这种动态。在SEO场景中,67%的池污染导致超过80%的暴露污染,创造了一种同质化但表面上健康的状态,尽管依赖合成来源,答案准确性仍然稳定。相反,在对抗性污染下,BM25等基线暴露了约19%的有害内容,而基于LLM的排序器表现出更强的抑制能力。这些发现突出了检索流程悄然转向合成证据的风险,以及需要检索感知策略来防止Web系统质量下降的自我强化循环。
🔬 方法详解
问题定义:论文旨在解决AI生成内容污染Web,导致检索系统性能下降的问题。现有方法未能充分考虑AI生成内容对检索结果质量和多样性的影响,存在检索结果同质化、低质量或有害内容泛滥的风险。
核心思路:论文的核心思路是将AI生成内容对检索的影响建模为一个“检索崩溃”的两阶段过程:首先,AI生成内容通过SEO等手段占据搜索结果的主导地位,降低来源多样性;然后,低质量或对抗性AI生成内容渗透到检索流程中,进一步降低检索质量。通过分析这两个阶段,可以更好地理解和应对AI污染带来的挑战。
技术框架:论文采用受控实验的方法来分析检索崩溃。实验包括两个主要场景:SEO场景和对抗性场景。在SEO场景中,研究人员生成高质量的SEO风格的AI内容,并将其注入到检索池中,观察其对检索结果的影响。在对抗性场景中,研究人员生成对抗性的AI内容,旨在欺骗检索系统,并观察其对检索结果的影响。实验使用BM25和基于LLM的排序器作为基线,评估不同方法在应对AI污染时的性能。
关键创新:论文的关键创新在于提出了“检索崩溃”这一概念,并将其分解为两个阶段进行分析。这种分析框架有助于更深入地理解AI生成内容对检索系统的影响,并为设计更有效的防御策略提供了指导。此外,论文还通过受控实验,量化了AI污染对检索结果质量和多样性的影响,为后续研究提供了实证依据。
关键设计:实验中,研究人员精心设计了SEO风格的AI内容和对抗性AI内容,以模拟不同的AI污染场景。SEO风格的AI内容旨在模仿高质量的Web内容,并利用SEO技术来提高其在搜索结果中的排名。对抗性AI内容旨在欺骗检索系统,例如通过生成误导性或有害的信息。实验中使用的LLM排序器包括基于Transformer的模型,并使用交叉熵损失函数进行训练。实验还评估了不同的检索策略,例如使用不同的相似度度量或过滤策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在SEO场景下,67%的池污染会导致超过80%的暴露污染,尽管答案准确率可能保持稳定。在对抗性场景下,BM25等传统方法会暴露约19%的有害内容,而基于LLM的排序器表现出更强的抑制能力。这些数据突出了AI污染对检索系统的潜在危害,以及使用更先进的排序方法的重要性。
🎯 应用场景
该研究成果可应用于提升搜索引擎和RAG系统的鲁棒性和可靠性,尤其是在AI生成内容日益普及的背景下。通过识别和过滤低质量或有害的AI生成内容,可以改善用户体验,防止信息污染,并维护Web生态系统的健康。
📄 摘要(原文)
The rapid proliferation of AI-generated content on the Web presents a structural risk to information retrieval, as search engines and Retrieval-Augmented Generation (RAG) systems increasingly consume evidence produced by the Large Language Models (LLMs). We characterize this ecosystem-level failure mode as Retrieval Collapse, a two-stage process where (1) AI-generated content dominates search results, eroding source diversity, and (2) low-quality or adversarial content infiltrates the retrieval pipeline. We analyzed this dynamic through controlled experiments involving both high-quality SEO-style content and adversarially crafted content. In the SEO scenario, a 67\% pool contamination led to over 80\% exposure contamination, creating a homogenized yet deceptively healthy state where answer accuracy remains stable despite the reliance on synthetic sources. Conversely, under adversarial contamination, baselines like BM25 exposed $\sim$19\% of harmful content, whereas LLM-based rankers demonstrated stronger suppression capabilities. These findings highlight the risk of retrieval pipelines quietly shifting toward synthetic evidence and the need for retrieval-aware strategies to prevent a self-reinforcing cycle of quality decline in Web-grounded systems.