Decision Quality Evaluation Framework at Pinterest
作者: Yuqi Tian, Robert Paine, Attila Dobi, Kevin O'Sullivan, Aravindh Manickavasagam, Faisal Farooq
分类: stat.AP, cs.AI
发布日期: 2026-02-17
💡 一句话要点
Pinterest提出决策质量评估框架,用于提升内容安全策略执行效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容安全 决策质量评估 黄金数据集 智能抽样 大型语言模型
📋 核心要点
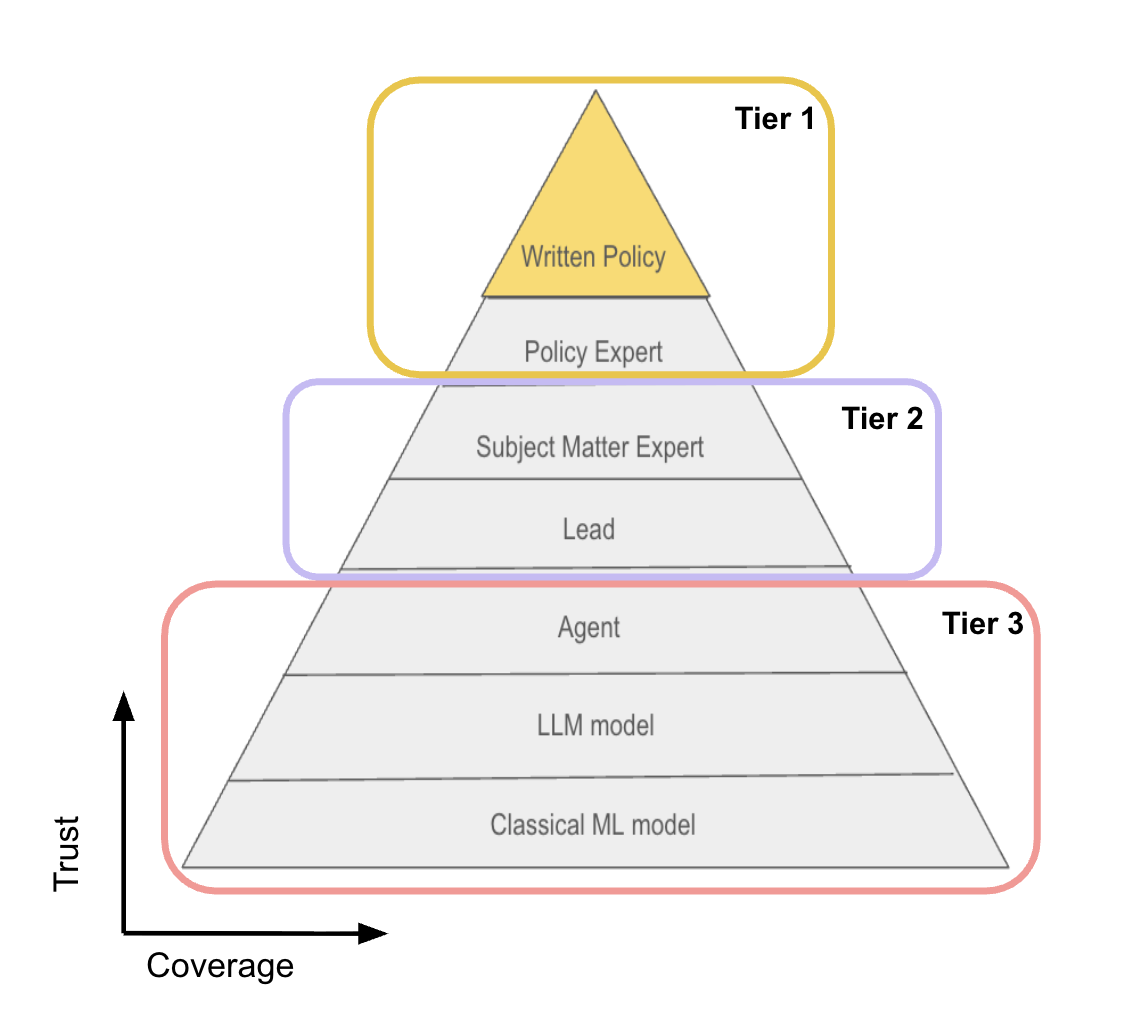
- 在线平台内容安全面临挑战,人工和LLM审核决策质量难以评估,存在成本、规模和信任度之间的权衡。
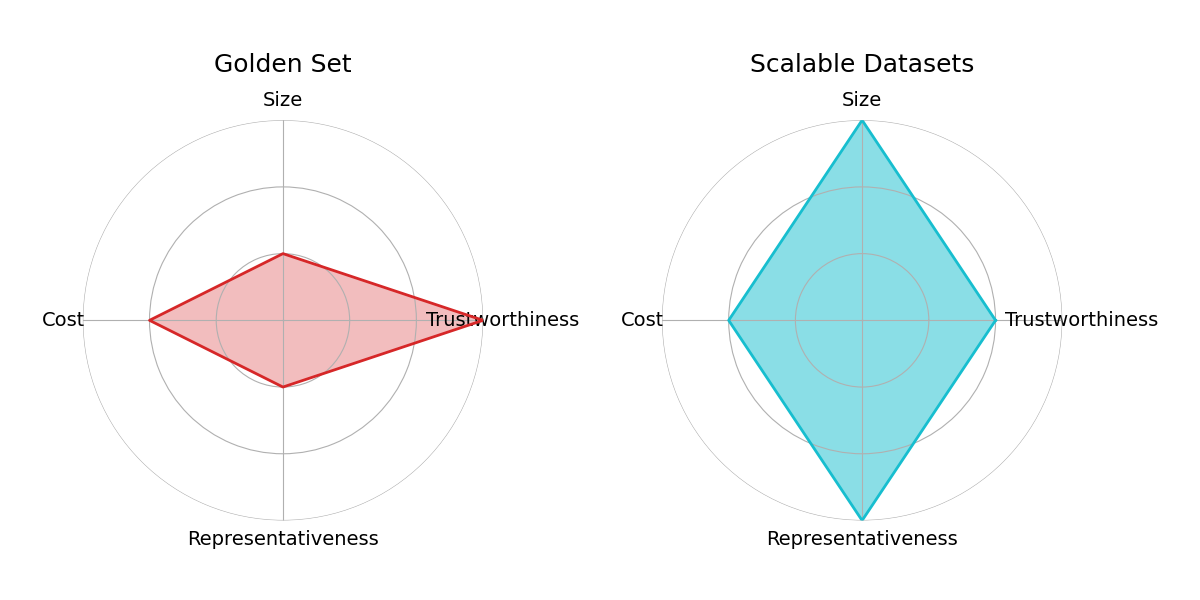
- 提出决策质量评估框架,核心是构建高可信黄金数据集(GDS)并结合智能抽样扩展数据覆盖。
- 框架应用于LLM性能基准测试、prompt优化、策略演变管理和内容流行度指标验证,实现数据驱动的内容安全管理。
📝 摘要(中文)
在线平台需要强大的系统来大规模执行内容安全策略。评估人工审核员和大型语言模型(LLM)所做决策的质量至关重要。然而,由于成本、规模和可信度之间的固有权衡,以及不断演变的策略的复杂性,这种评估具有挑战性。为了解决这个问题,我们提出了一个在Pinterest开发和部署的综合决策质量评估框架。该框架以主题专家(SME)策划的高可信黄金数据集(GDS)为中心,作为ground truth基准。我们引入了一个自动化的智能抽样流程,该流程使用倾向得分来有效地扩展数据集覆盖范围。我们展示了该框架在几个关键领域的实际应用:对各种LLM代理的成本-性能权衡进行基准测试,建立严格的数据驱动的prompt优化方法,管理复杂的策略演变,并通过持续验证确保策略内容流行度指标的完整性。该框架使内容安全系统的管理从主观评估转变为数据驱动和定量实践。
🔬 方法详解
问题定义:论文旨在解决在线平台内容审核决策质量评估的问题。现有方法依赖于主观评估,缺乏客观标准和可扩展性,难以应对不断变化的策略和大规模内容。此外,人工审核成本高昂,而LLM审核的准确性有待验证。因此,需要一种能够量化评估审核决策质量,并支持策略优化和模型选择的框架。
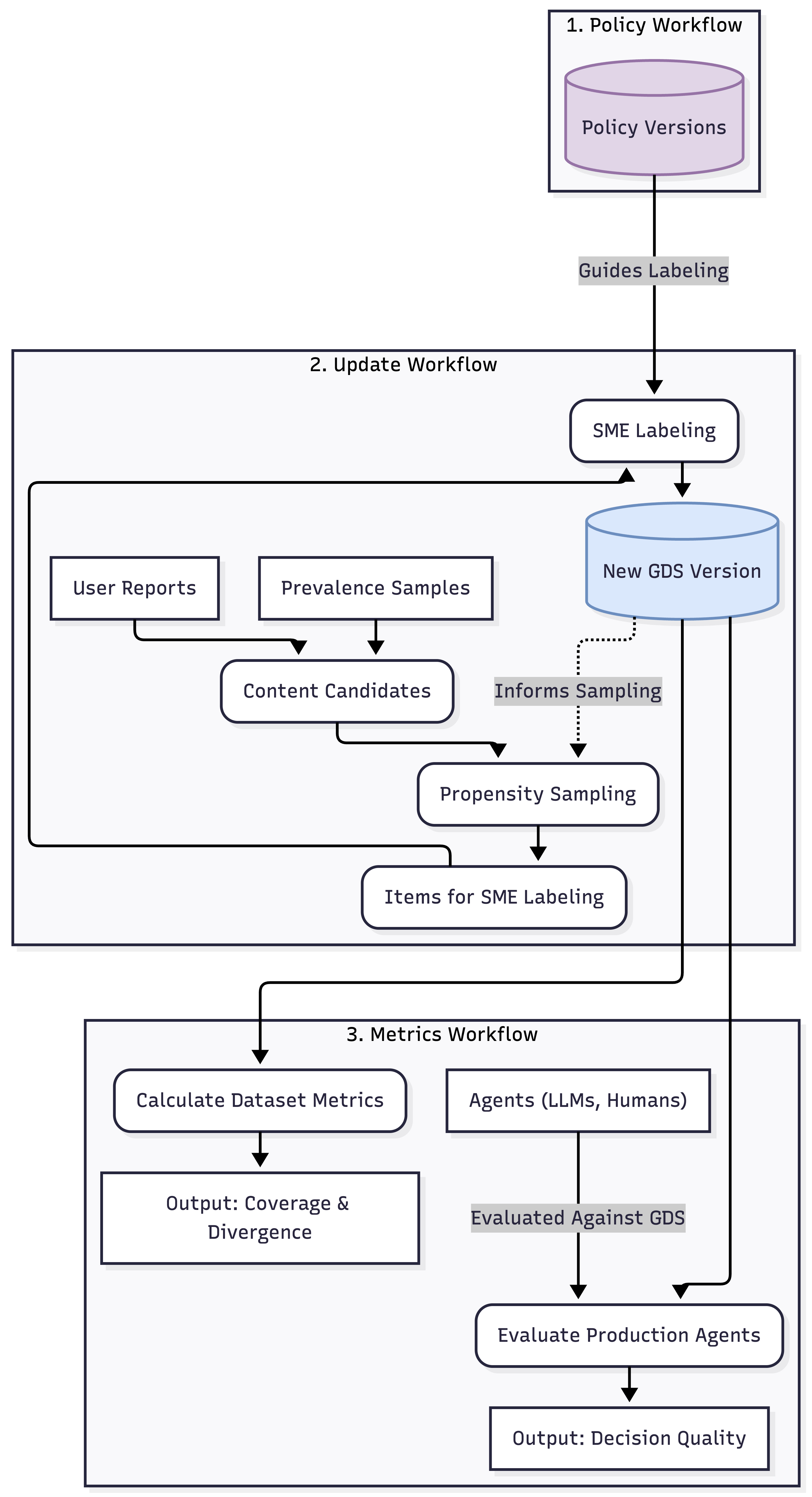
核心思路:论文的核心思路是构建一个基于黄金数据集(Golden Set, GDS)的决策质量评估框架。GDS由领域专家标注,作为审核决策的ground truth。通过将审核结果与GDS进行比较,可以量化评估审核决策的准确性。此外,论文还引入了智能抽样方法,以提高GDS的覆盖范围和效率。
技术框架:该框架包含以下几个主要模块:1) 黄金数据集(GDS)构建:由主题专家(SME)人工标注,确保高质量的ground truth。2) 智能抽样:使用倾向得分(propensity scores)来选择具有代表性的样本,以扩展GDS的覆盖范围。3) 决策评估:将人工审核或LLM审核的决策与GDS进行比较,计算准确率、召回率等指标。4) 策略优化:基于评估结果,优化内容安全策略和LLM prompt。5) 持续验证:定期更新GDS并重新评估,以确保框架的有效性。
关键创新:该框架的关键创新在于:1) 高可信的黄金数据集(GDS):由领域专家标注,保证了评估的准确性。2) 智能抽样方法:利用倾向得分,提高了GDS的覆盖范围和效率,降低了标注成本。3) 数据驱动的策略优化:基于评估结果,可以量化地优化内容安全策略和LLM prompt。
关键设计:智能抽样中的倾向得分计算方法是关键设计之一。具体来说,倾向得分可以基于内容的特征(例如文本、图像、用户行为等)来计算,反映了内容被违反策略的可能性。通过优先选择倾向得分高的样本进行标注,可以更有效地扩展GDS的覆盖范围。此外,评估指标的选择也很重要,需要根据具体的应用场景选择合适的指标,例如准确率、召回率、F1值等。
🖼️ 关键图片
📊 实验亮点
该框架通过构建高可信黄金数据集和智能抽样方法,实现了对内容审核决策质量的量化评估。实验结果表明,该框架可以有效地评估不同LLM的性能,并支持数据驱动的prompt优化,从而提升内容安全策略的执行效果。具体性能数据未知,但论文强调了从主观评估到数据驱动的转变。
🎯 应用场景
该研究成果可广泛应用于各类在线平台的内容安全管理,例如社交媒体、电商平台、新闻网站等。通过该框架,平台可以更有效地评估和提升内容审核决策的质量,降低违规内容的传播风险,维护用户体验和平台声誉。此外,该框架还可以用于评估不同LLM在内容审核任务中的性能,为模型选择提供依据。
📄 摘要(原文)
Online platforms require robust systems to enforce content safety policies at scale. A critical component of these systems is the ability to evaluate the quality of moderation decisions made by both human agents and Large Language Models (LLMs). However, this evaluation is challenging due to the inherent trade-offs between cost, scale, and trustworthiness, along with the complexity of evolving policies. To address this, we present a comprehensive Decision Quality Evaluation Framework developed and deployed at Pinterest. The framework is centered on a high-trust Golden Set (GDS) curated by subject matter experts (SMEs), which serves as a ground truth benchmark. We introduce an automated intelligent sampling pipeline that uses propensity scores to efficiently expand dataset coverage. We demonstrate the framework's practical application in several key areas: benchmarking the cost-performance trade-offs of various LLM agents, establishing a rigorous methodology for data-driven prompt optimization, managing complex policy evolution, and ensuring the integrity of policy content prevalence metrics via continuous validation. The framework enables a shift from subjective assessments to a data-driven and quantitative practice for managing content safety systems.