CARE Drive A Framework for Evaluating Reason-Responsiveness of Vision Language Models in Automated Driving
作者: Lucas Elbert Suryana, Farah Bierenga, Sanne van Buuren, Pepijn Kooij, Elsefien Tulleners, Federico Scari, Simeon Calvert, Bart van Arem, Arkady Zgonnikov
分类: cs.AI, cs.CV
发布日期: 2026-02-17
备注: 21 pages, on submission to Transportation Research Part C
💡 一句话要点
CARE Drive:评估自动驾驶中视觉语言模型对人类理由的响应性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉语言模型 理由响应性 可解释性 模型评估
📋 核心要点
- 现有自动驾驶视觉语言模型评估侧重结果,忽略了模型决策是否基于人类可理解的理由,存在安全隐患。
- CARE Drive框架通过对比基线和理由增强模型在不同上下文下的决策,评估模型对人类理由的响应程度。
- 实验表明,人类理由能显著影响模型决策,但不同理由的影响程度存在差异,揭示模型响应性的不均衡性。
📝 摘要(中文)
基础模型,包括视觉语言模型,越来越多地应用于自动驾驶中,以解释场景、推荐行动并生成自然语言解释。然而,现有的评估方法主要评估基于结果的性能,例如安全性和轨迹准确性,而没有确定模型决策是否反映了与人类相关的考虑因素。因此,此类模型产生的解释是否对应于真正的理由响应式决策,还是仅仅是事后合理化,仍然不清楚。这种局限性在安全关键领域尤为重要,因为它会产生虚假的信心。为了解决这一差距,我们提出了CARE Drive,即Context Aware Reasons Evaluation for Driving,这是一个与模型无关的框架,用于评估应用于自动驾驶的视觉语言模型中的理由响应性。CARE Drive比较了在受控上下文变化下,基线模型和理由增强模型的决策,以评估人类理由是否因果地影响决策行为。该框架采用两阶段评估过程。提示校准确保输出稳定。然后,系统性的上下文扰动测量决策对人类理由的敏感性,例如安全裕度、社会压力和效率约束。我们通过一个涉及竞争规范性考虑因素的骑自行车者超车场景来演示CARE Drive。结果表明,明确的人类理由显着影响模型决策,从而提高了与专家推荐行为的一致性。然而,响应性因上下文因素而异,表明对不同类型理由的敏感性不均匀。这些发现提供了经验证据,表明可以在不修改模型参数的情况下系统地评估基础模型中的理由响应性。
🔬 方法详解
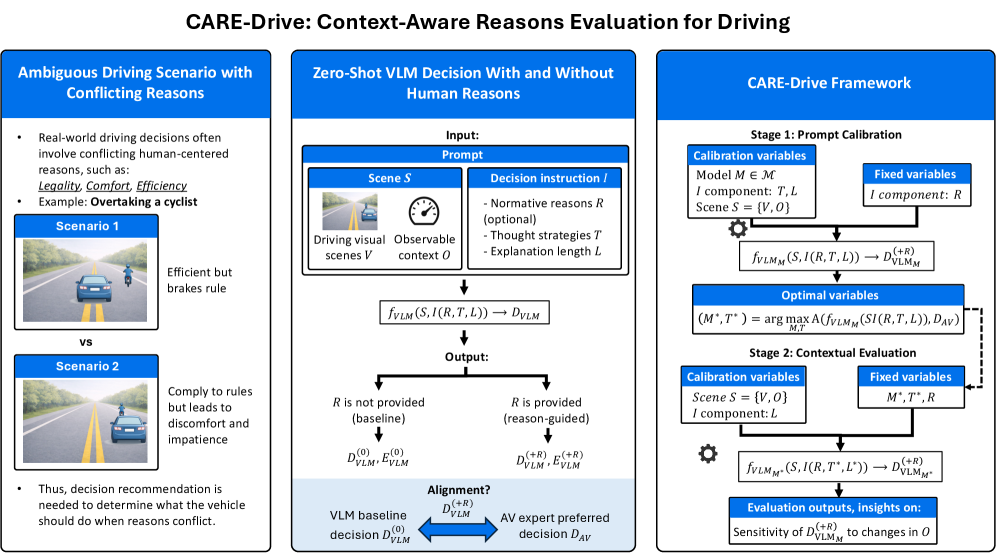
问题定义:现有自动驾驶视觉语言模型的评估方法主要关注安全性、轨迹精度等结果指标,缺乏对模型决策过程是否符合人类逻辑和价值观的评估。这导致模型可能做出看似正确但缺乏合理理由的决策,尤其是在安全攸关的场景下,会带来潜在风险。现有方法无法区分模型是真正基于理由做出决策,还是仅仅事后对决策进行合理化解释。
核心思路:CARE Drive的核心思路是通过系统性地改变场景上下文,并引入与人类理由相关的因素,观察视觉语言模型的决策是否随之发生变化。如果模型决策对这些因素敏感,则表明模型具有一定的理由响应性。通过比较基线模型和理由增强模型的决策差异,可以量化理由对决策的影响程度。
技术框架:CARE Drive框架包含两个主要阶段:提示校准和上下文扰动。首先,提示校准阶段旨在确保模型输出的稳定性,减少随机性带来的干扰。然后,上下文扰动阶段通过系统性地改变场景中的关键因素,例如安全裕度、社会压力和效率约束,来观察模型决策的变化。框架通过比较不同上下文下的模型决策,评估模型对不同类型理由的响应程度。
关键创新:CARE Drive的关键创新在于提出了一个与模型无关的框架,用于评估视觉语言模型在自动驾驶场景中的理由响应性。该框架不依赖于特定的模型结构或训练方法,可以应用于各种不同的视觉语言模型。此外,该框架通过系统性的上下文扰动,能够量化不同类型理由对模型决策的影响程度,从而更全面地评估模型的理由响应性。
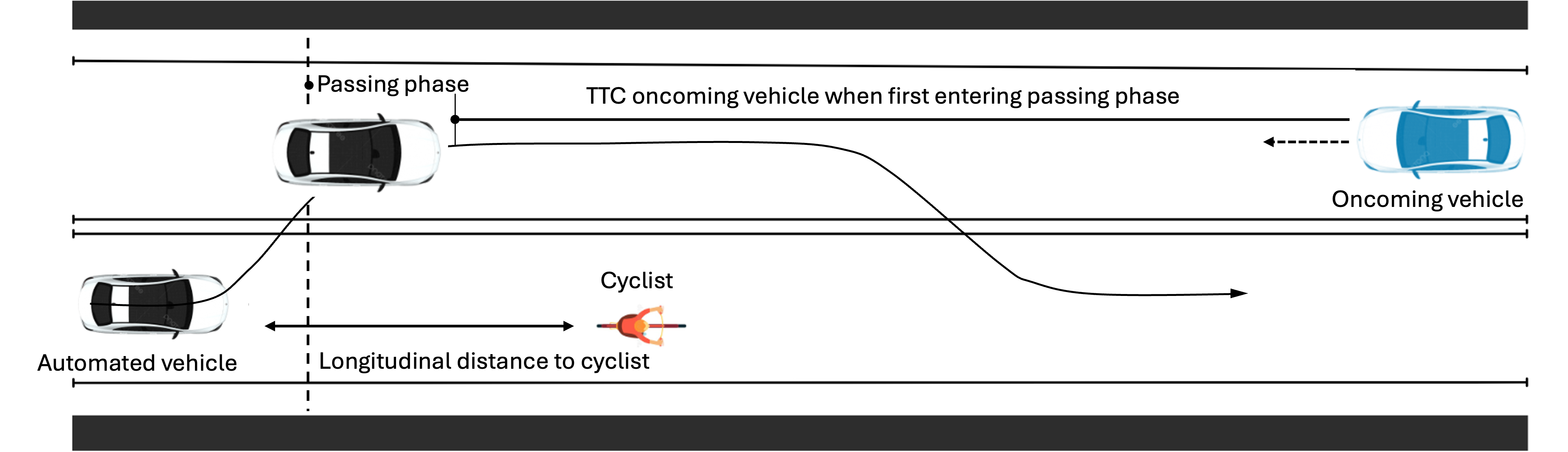
关键设计:CARE Drive框架的关键设计包括:1) 使用提示校准技术来减少模型输出的随机性;2) 设计合理的上下文扰动策略,以系统性地改变场景中的关键因素;3) 定义明确的评估指标,以量化模型对不同类型理由的响应程度。例如,在骑自行车者超车场景中,可以通过改变骑自行车者与车辆之间的距离来模拟安全裕度的变化,并通过改变周围车辆的数量来模拟社会压力。
🖼️ 关键图片

📊 实验亮点
在骑自行车者超车场景的实验中,CARE Drive表明,明确的人类理由能够显著影响模型决策,提高与专家推荐行为的一致性。实验结果还表明,模型对不同类型理由的响应程度存在差异,例如对安全裕度的响应性高于对社会压力的响应性,这揭示了模型在理由理解和推理方面的局限性。
🎯 应用场景
CARE Drive框架可用于评估和改进自动驾驶系统中视觉语言模型的决策能力,确保模型在复杂场景下做出符合人类价值观和安全规范的决策。该框架还有助于提高自动驾驶系统的透明度和可解释性,增强用户对系统的信任感。未来,该框架可扩展到其他安全关键领域,例如医疗诊断和金融风险评估。
📄 摘要(原文)
Foundation models, including vision language models, are increasingly used in automated driving to interpret scenes, recommend actions, and generate natural language explanations. However, existing evaluation methods primarily assess outcome based performance, such as safety and trajectory accuracy, without determining whether model decisions reflect human relevant considerations. As a result, it remains unclear whether explanations produced by such models correspond to genuine reason responsive decision making or merely post hoc rationalizations. This limitation is especially significant in safety critical domains because it can create false confidence. To address this gap, we propose CARE Drive, Context Aware Reasons Evaluation for Driving, a model agnostic framework for evaluating reason responsiveness in vision language models applied to automated driving. CARE Drive compares baseline and reason augmented model decisions under controlled contextual variation to assess whether human reasons causally influence decision behavior. The framework employs a two stage evaluation process. Prompt calibration ensures stable outputs. Systematic contextual perturbation then measures decision sensitivity to human reasons such as safety margins, social pressure, and efficiency constraints. We demonstrate CARE Drive in a cyclist overtaking scenario involving competing normative considerations. Results show that explicit human reasons significantly influence model decisions, improving alignment with expert recommended behavior. However, responsiveness varies across contextual factors, indicating uneven sensitivity to different types of reasons. These findings provide empirical evidence that reason responsiveness in foundation models can be systematically evaluated without modifying model parameters.