How Vision Becomes Language: A Layer-wise Information-Theoretic Analysis of Multimodal Reasoning
作者: Hongxuan Wu, Yukun Zhang, Xueqing Zhou
分类: cs.AI
发布日期: 2026-02-17
💡 一句话要点
提出基于信息论的层级分析框架,解析多模态Transformer的推理机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 信息论 分部信息分解 Transformer 视觉问答 模态转换 因果推断
📋 核心要点
- 现有方法难以量化多模态Transformer中视觉、语言和跨模态信息在推理过程中的作用。
- 提出PID Flow框架,结合降维、高斯化和闭式PID估计,分析各层的信息贡献。
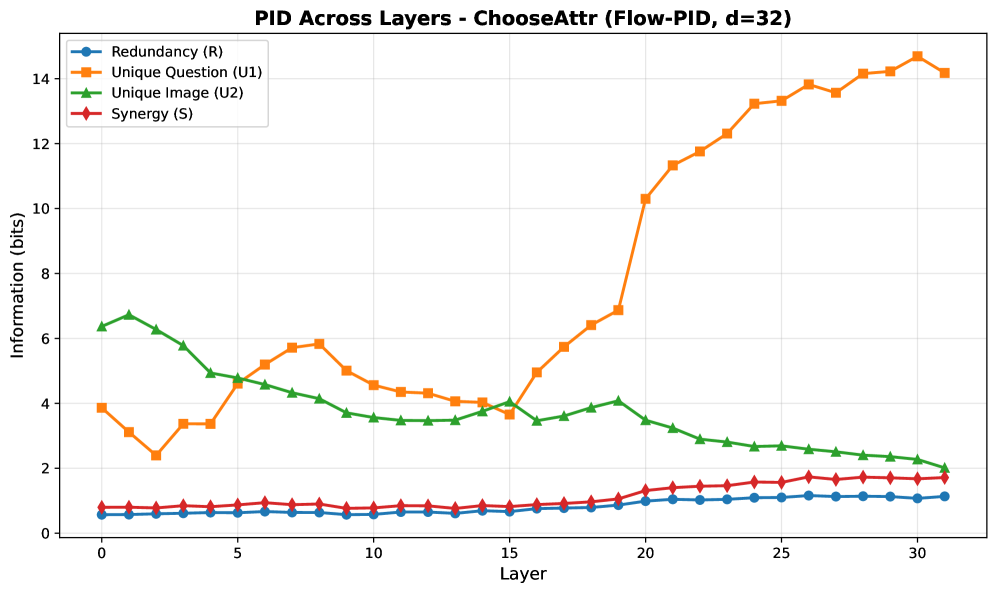
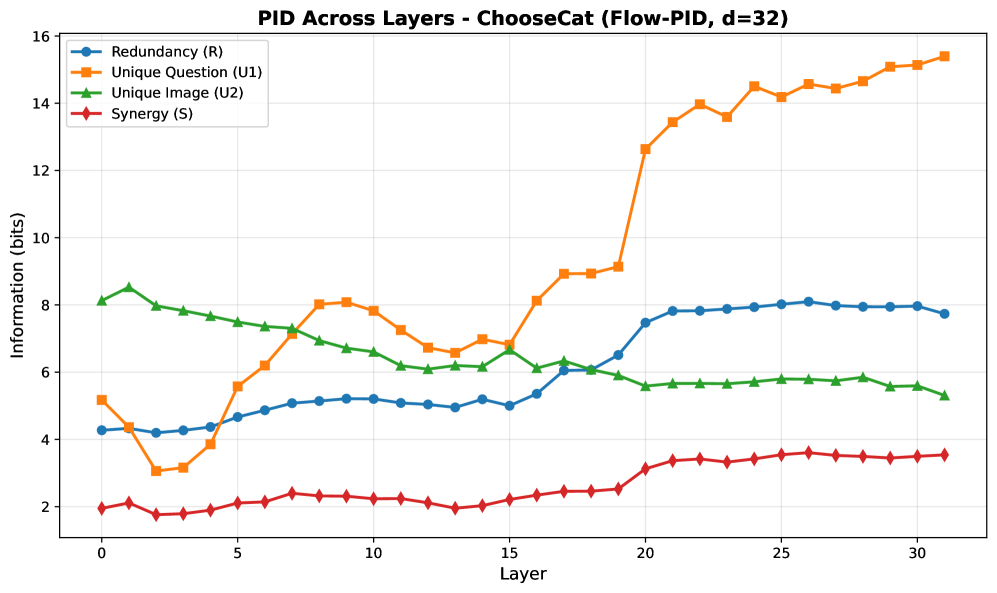
- 实验表明视觉信息早期重要,语言信息后期主导,跨模态协同作用较小,且任务依赖性强。
📝 摘要(中文)
本文提出一个基于分部信息分解(PID)的层级框架,旨在分析多模态Transformer在回答视觉问题时,预测是由视觉证据、语言推理还是真正的跨模态融合驱动,以及这种结构如何在不同层演变。为了使PID能够处理高维神经表征,作者引入了PID Flow,该流程结合了降维、归一化流高斯化和闭式高斯PID估计。将此框架应用于LLaVA-1.5-7B和LLaVA-1.6-7B在六个GQA推理任务上,揭示了一种一致的模态转换模式:视觉唯一信息在早期达到峰值并随深度衰减,语言唯一信息在后期激增,约占最终预测的82%,而跨模态协同作用保持在2%以下。这种轨迹在模型变体中高度稳定(层级相关性> 0.96),但强烈依赖于任务,语义冗余控制着详细的信息指纹。为了建立因果关系,作者进行了有针对性的Image→Question注意力剔除实验,表明破坏主要的转换路径会导致捕获的视觉唯一信息、补偿性协同作用和总信息成本的可预测增加,这些影响在视觉依赖任务中最强,在高冗余任务中最弱。总之,这些结果提供了一个信息论的、因果的解释,说明了多模态Transformer中视觉如何转化为语言,并为识别模态特定信息丢失的架构瓶颈提供了定量指导。
🔬 方法详解
问题定义:论文旨在解决多模态Transformer在视觉问答任务中,视觉信息、语言信息以及跨模态融合信息各自对最终预测结果的贡献程度问题。现有方法难以有效分离和量化这些信息的贡献,尤其是在高维神经表征的情况下,缺乏对模型内部信息流动的细粒度理解。
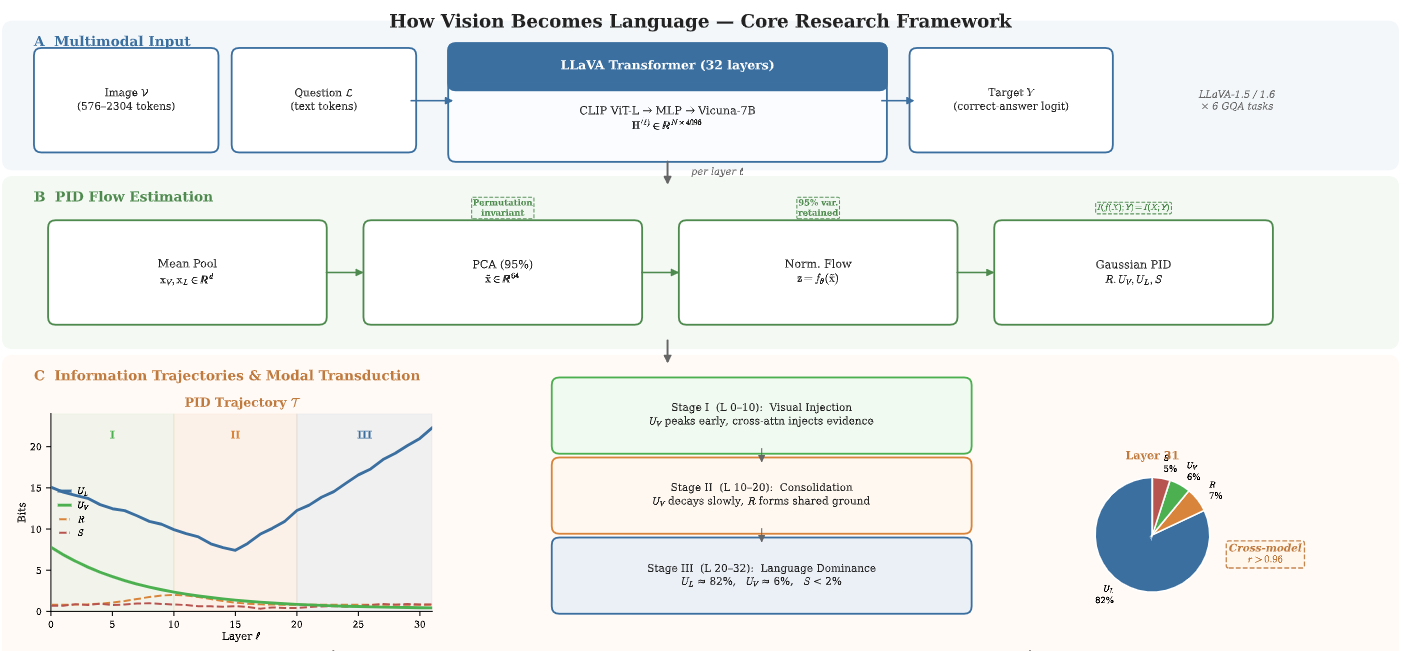
核心思路:论文的核心思路是利用信息论中的分部信息分解(Partial Information Decomposition, PID)方法,将每一层Transformer的预测信息分解为冗余信息、视觉唯一信息、语言唯一信息和协同信息。通过分析这些信息成分在不同层的变化,揭示视觉信息如何逐渐转化为语言信息,以及跨模态融合的作用。
技术框架:整体框架包含以下几个主要步骤:1) 使用多模态Transformer(如LLaVA)处理视觉问答任务;2) 提取Transformer每一层的神经表征;3) 使用PID Flow对高维表征进行处理,包括降维、归一化流高斯化;4) 使用闭式高斯PID估计计算各个信息成分;5) 分析不同层的信息成分变化趋势,并进行因果干预实验。
关键创新:论文的关键创新在于提出了PID Flow,这是一个将PID应用于高维神经表征的实用流程。PID Flow结合了降维技术(例如PCA),归一化流(Normalizing Flow)将神经表征转换为高斯分布,从而可以使用闭式公式进行PID估计。这使得对大型多模态模型的层级信息分析成为可能。
关键设计:PID Flow的关键设计包括:1) 使用PCA等降维方法降低神经表征的维度,减少计算复杂度;2) 使用归一化流将神经表征转换为高斯分布,以便使用闭式公式计算PID;3) 设计了Image→Question注意力剔除实验,通过干预注意力机制来验证信息流动的因果关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在LLaVA模型中,视觉唯一信息在早期层达到峰值并逐渐衰减,而语言唯一信息在后期层激增,占据最终预测的约82%。跨模态协同作用始终较低,表明模型主要依赖于单模态信息。注意力剔除实验验证了信息流动的因果关系,并揭示了任务依赖性。
🎯 应用场景
该研究成果可应用于多模态模型的理解与优化,例如,通过识别信息瓶颈来改进模型架构,或通过增强跨模态协同作用来提高模型性能。此外,该方法还可以用于评估不同多模态模型的推理能力,并指导模型在特定任务上的部署。
📄 摘要(原文)
When a multimodal Transformer answers a visual question, is the prediction driven by visual evidence, linguistic reasoning, or genuinely fused cross-modal computation -- and how does this structure evolve across layers? We address this question with a layer-wise framework based on Partial Information Decomposition (PID) that decomposes the predictive information at each Transformer layer into redundant, vision-unique, language-unique, and synergistic components. To make PID tractable for high-dimensional neural representations, we introduce \emph{PID Flow}, a pipeline combining dimensionality reduction, normalizing-flow Gaussianization, and closed-form Gaussian PID estimation. Applying this framework to LLaVA-1.5-7B and LLaVA-1.6-7B across six GQA reasoning tasks, we uncover a consistent \emph{modal transduction} pattern: visual-unique information peaks early and decays with depth, language-unique information surges in late layers to account for roughly 82\% of the final prediction, and cross-modal synergy remains below 2\%. This trajectory is highly stable across model variants (layer-wise correlations $>$0.96) yet strongly task-dependent, with semantic redundancy governing the detailed information fingerprint. To establish causality, we perform targeted Image$\rightarrow$Question attention knockouts and show that disrupting the primary transduction pathway induces predictable increases in trapped visual-unique information, compensatory synergy, and total information cost -- effects that are strongest in vision-dependent tasks and weakest in high-redundancy tasks. Together, these results provide an information-theoretic, causal account of how vision becomes language in multimodal Transformers, and offer quantitative guidance for identifying architectural bottlenecks where modality-specific information is lost.