Quantifying construct validity in large language model evaluations
作者: Ryan Othniel Kearns
分类: cs.AI, cs.LG
发布日期: 2026-02-17
💡 一句话要点
提出结构化能力模型,用于量化大语言模型评估中的构建效度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 构建效度 潜在因子模型 缩放定律 结构化能力模型 模型能力 基准测试
📋 核心要点
- 现有LLM基准测试存在污染和标注错误等问题,难以准确反映模型真实能力,构建效度面临挑战。
- 论文提出结构化能力模型,结合缩放定律和潜在因子模型,分离模型规模与能力,提升模型能力的可解释性和泛化性。
- 实验表明,结构化能力模型在拟合指标和分布外预测方面优于现有方法,验证了其在量化构建效度方面的有效性。
📝 摘要(中文)
大语言模型(LLM)领域通常将基准测试结果等同于模型的一般能力。然而,基准测试可能存在问题,例如测试集污染和标注错误,从而扭曲性能。如何确定基准测试能够可靠地指示我们想要测量的某种能力?这个问题关系到LLM基准测试的构建效度,需要在建模和预测LLM性能时将基准测试结果与能力区分开来。社会科学家和计算机科学家都提出了形式模型——潜在因子模型和缩放定律——用于识别基准分数背后的能力。然而,这两种技术都不能令人满意地解决构建效度问题。潜在因子模型忽略了缩放定律,因此,它们提取的能力通常是模型大小的代理。缩放定律忽略了测量误差,因此,它们提取的能力既不可解释,又过度拟合了观察到的基准测试。本文提出了结构化能力模型,这是第一个从大量LLM基准测试结果中提取可解释和可泛化能力的模型。在OpenLLM排行榜的大量结果样本上拟合了该模型及其两种替代方案。结构化能力模型在简约拟合指标上优于潜在因子模型,并且表现出比缩放定律更好的分布外基准预测。这些改进是可能的,因为现有方法都没有以适当的方式将模型规模与能力分开。模型规模应该像缩放定律中那样告知能力,并且这些能力应该像潜在因子模型中那样告知观察到的结果,直到测量误差。通过结合这两种见解,结构化能力模型展示了更好的解释和预测能力,从而量化LLM评估中的构建效度。
🔬 方法详解
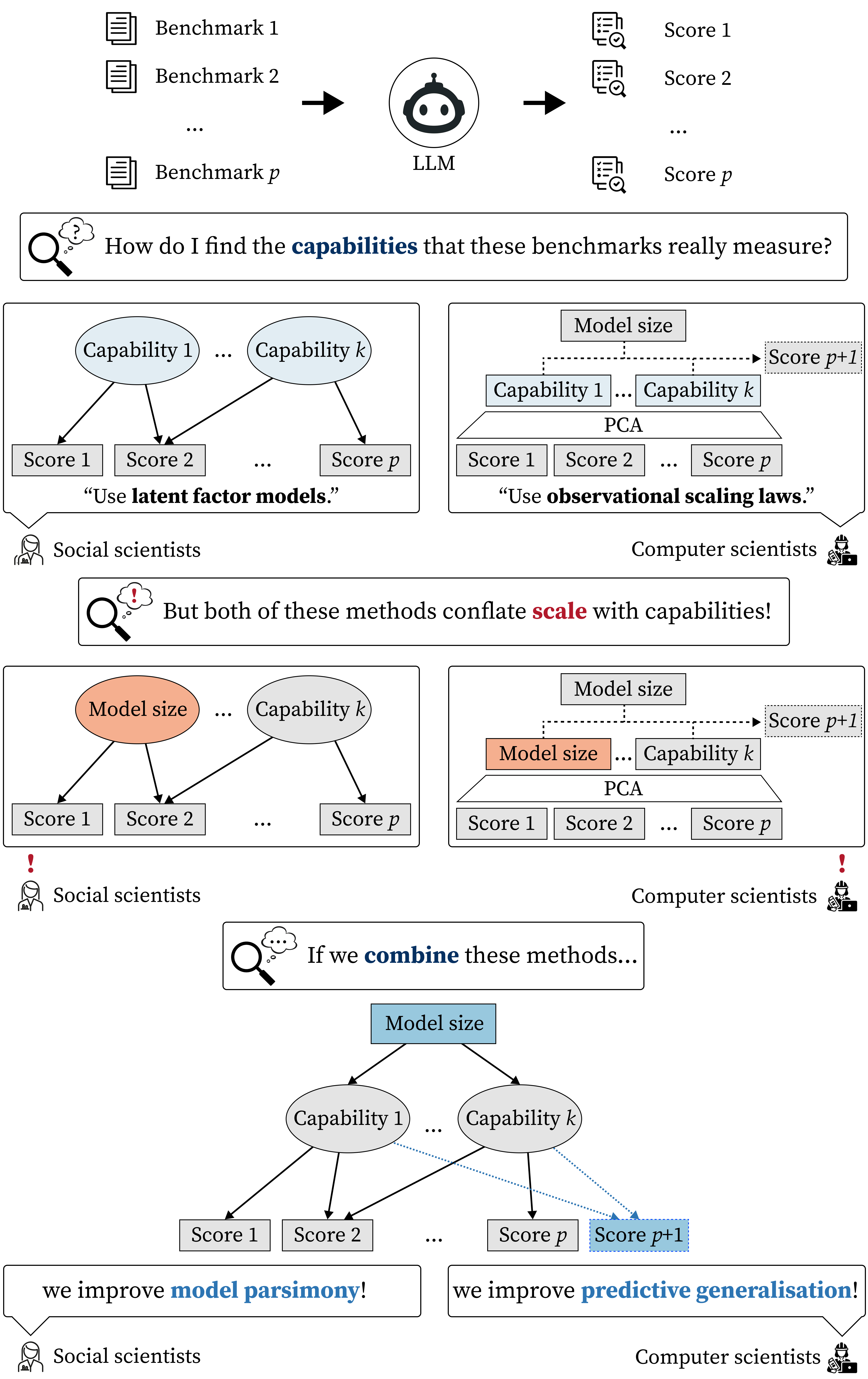
问题定义:现有的大语言模型评估方法,特别是依赖基准测试,存在构建效度问题。简单地将基准测试结果视为模型能力的直接反映是不准确的,因为基准测试本身可能受到测试集污染、标注错误等因素的影响。此外,现有方法如潜在因子模型忽略了模型规模的影响,而缩放定律又忽略了测量误差,导致提取的能力要么是模型大小的代理,要么不可解释且过度拟合。
核心思路:论文的核心思路是将模型规模(scaling laws)和测量误差(latent factor models)结合起来,构建一个更完善的模型,从而更准确地评估大语言模型的能力。该方法旨在分离模型规模与能力,使得提取的能力既具有可解释性,又具有泛化能力,从而更好地量化LLM评估中的构建效度。
技术框架:论文提出了“结构化能力模型”(Structured Capabilities Model)。该模型包含以下几个关键部分: 1. 模型规模建模:利用缩放定律来捕捉模型规模对能力的影响。 2. 能力建模:使用潜在因子模型来提取潜在的能力,并考虑测量误差。 3. 结构化约束:在能力建模中引入结构化约束,以提高能力的可解释性和泛化能力。 4. 联合优化:同时优化模型规模和能力,以获得更准确的评估结果。
关键创新:该方法最重要的创新在于它将缩放定律和潜在因子模型结合起来,从而能够同时考虑模型规模和测量误差。与现有方法相比,该方法能够更准确地提取模型的能力,并提高能力的可解释性和泛化能力。此外,结构化约束的引入也有助于提高模型的可解释性。
关键设计:论文中涉及的关键设计包括: 1. 缩放定律的具体形式:论文需要选择合适的缩放定律来建模模型规模对能力的影响。 2. 潜在因子模型的具体形式:论文需要选择合适的潜在因子模型来提取潜在的能力,并考虑测量误差。 3. 结构化约束的具体形式:论文需要设计合适的结构化约束,以提高能力的可解释性和泛化能力。 4. 优化算法:论文需要选择合适的优化算法来同时优化模型规模和能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结构化能力模型在简约拟合指标上优于潜在因子模型,并且表现出比缩放定律更好的分布外基准预测。这意味着该模型能够更准确地提取模型的能力,并提高能力的可解释性和泛化能力。这些结果验证了该模型在量化LLM评估中的构建效度方面的有效性。
🎯 应用场景
该研究成果可应用于更准确地评估和比较不同大语言模型的能力,指导模型训练和优化,以及设计更有效的基准测试。通过量化构建效度,可以提高LLM评估的可靠性和可信度,从而促进LLM技术的健康发展。
📄 摘要(原文)
The LLM community often reports benchmark results as if they are synonymous with general model capabilities. However, benchmarks can have problems that distort performance, like test set contamination and annotator error. How can we know that a benchmark is a reliable indicator of some capability that we want to measure? This question concerns the construct validity of LLM benchmarks, and it requires separating benchmark results from capabilities when we model and predict LLM performance. Both social scientists and computer scientists propose formal models - latent factor models and scaling laws - for identifying the capabilities underlying benchmark scores. However, neither technique is satisfactory for construct validity. Latent factor models ignore scaling laws, and as a result, the capabilities they extract often proxy model size. Scaling laws ignore measurement error, and as a result, the capabilities they extract are both uninterpretable and overfit to the observed benchmarks. This thesis presents the structured capabilities model, the first model to extract interpretable and generalisable capabilities from a large collection of LLM benchmark results. I fit this model and its two alternatives on a large sample of results from the OpenLLM Leaderboard. Structured capabilities outperform latent factor models on parsimonious fit indices, and exhibit better out-of-distribution benchmark prediction than scaling laws. These improvements are possible because neither existing approach separates model scale from capabilities in the appropriate way. Model scale should inform capabilities, as in scaling laws, and these capabilities should inform observed results up to measurement error, as in latent factor models. In combining these two insights, structured capabilities demonstrate better explanatory and predictive power for quantifying construct validity in LLM evaluations.