SecCodeBench-V2 Technical Report
作者: Longfei Chen, Ji Zhao, Lanxiao Cui, Tong Su, Xingbo Pan, Ziyang Li, Yongxing Wu, Qijiang Cao, Qiyao Cai, Jing Zhang, Yuandong Ni, Junyao He, Zeyu Zhang, Chao Ge, Xuhuai Lu, Zeyu Gao, Yuxin Cui, Weisen Chen, Yuxuan Peng, Shengping Wang, Qi Li, Yukai Huang, Yukun Liu, Tuo Zhou, Terry Yue Zhuo, Junyang Lin, Chao Zhang
分类: cs.CR, cs.AI, cs.SE
发布日期: 2026-02-17
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
SecCodeBench-V2:一个用于评估LLM代码生成安全性的工业级基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 安全性评估 基准测试 软件安全
📋 核心要点
- 现有LLM代码生成工具在安全性方面存在不足,容易产生包含安全漏洞的代码,缺乏系统性的评估和改进。
- SecCodeBench-V2构建了一个包含工业级真实场景的基准,通过功能验证和安全验证的PoC测试用例,全面评估LLM的代码安全性。
- 该基准采用动态执行和LLM-as-a-judge相结合的评估方法,并设计了Pass@K评分协议,实现了对LLM安全能力的量化评估。
📝 摘要(中文)
本文介绍了SecCodeBench-V2,这是一个公开的基准,用于评估大型语言模型(LLM)在生成安全代码方面的能力。SecCodeBench-V2包含98个生成和修复场景,这些场景源自阿里巴巴集团的工业生产实践,涵盖了Java、C、Python、Go和Node.js五种编程语言中22个常见的CWE(常见弱点枚举)类别。SecCodeBench-V2采用函数级别的任务形式:每个场景提供一个完整的项目支架,并要求模型在固定的接口和依赖关系下实现或修补指定的目标函数。对于每个场景,SecCodeBench-V2提供可执行的概念验证(PoC)测试用例,用于功能验证和安全验证。所有测试用例均由安全专家编写并经过双重审查,确保高保真度、广泛覆盖和可靠的ground truth。除了基准本身,我们还构建了一个统一的评估流程,主要通过动态执行来评估模型。对于大多数场景,我们在隔离环境中编译和运行模型生成的工件,并执行PoC测试用例以验证功能正确性和安全属性。对于无法通过确定性测试用例判断安全问题的场景,我们还采用了LLM-as-a-judge oracle。为了总结跨异构场景和难度级别的性能,我们设计了一个基于Pass@K的评分协议,该协议对场景和严重性进行有原则的聚合,从而实现跨模型的整体和可比评估。总而言之,SecCodeBench-V2为评估AI编码助手的安全态势提供了一个严谨且可重现的基础,结果和工件发布在https://alibaba.github.io/sec-code-bench。该基准可在https://github.com/alibaba/sec-code-bench公开获取。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在代码生成方面取得了显著进展,但其生成的代码往往存在安全漏洞,例如注入攻击、跨站脚本攻击等。缺乏一个全面、可靠的基准来评估和比较不同LLM在代码安全方面的能力,阻碍了安全代码生成技术的发展。现有的代码生成基准通常侧重于功能正确性,而忽略了安全性,或者缺乏工业级的真实场景。
核心思路:SecCodeBench-V2的核心思路是构建一个包含真实工业场景、覆盖多种编程语言和CWE类别的代码安全基准。通过提供可执行的PoC测试用例,对LLM生成的代码进行功能和安全验证。对于难以通过确定性测试判断的场景,引入LLM作为裁判,进行主观评估。最终,通过Pass@K评分协议,对LLM的安全能力进行量化评估。
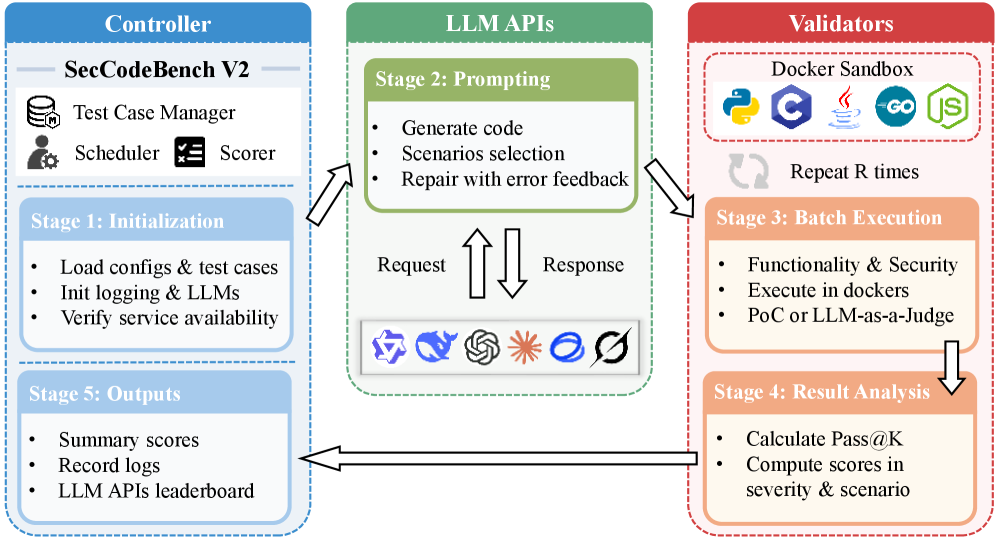
技术框架:SecCodeBench-V2的整体框架包括以下几个主要模块: 1. 场景构建:从阿里巴巴集团的工业生产实践中提取安全相关的代码生成和修复场景,涵盖Java、C、Python、Go和Node.js五种编程语言。 2. 测试用例生成:为每个场景编写可执行的PoC测试用例,用于验证功能正确性和安全属性。测试用例由安全专家编写并经过双重审查。 3. 评估流程:构建统一的评估流程,包括代码编译、动态执行、安全验证和LLM裁判。 4. 评分协议:设计基于Pass@K的评分协议,对LLM在不同场景和难度下的表现进行综合评估。
关键创新:SecCodeBench-V2的关键创新在于: 1. 工业级真实场景:基准中的场景源自真实的工业生产实践,更贴近实际应用需求。 2. 全面的安全覆盖:覆盖了22个常见的CWE类别,能够全面评估LLM的代码安全能力。 3. 动态执行和LLM裁判相结合:结合了确定性测试和主观评估,能够更准确地评估LLM的安全能力。
关键设计:SecCodeBench-V2的关键设计包括: 1. 函数级别的任务形式:要求模型实现或修补指定的目标函数,降低了任务难度,更易于评估。 2. 可执行的PoC测试用例:提供了可靠的ground truth,能够自动化地验证功能正确性和安全属性。 3. Pass@K评分协议:能够对LLM在不同场景和难度下的表现进行综合评估,并进行跨模型的比较。
🖼️ 关键图片
📊 实验亮点
SecCodeBench-V2包含98个来自工业界的真实场景,覆盖了5种编程语言和22个CWE类别,提供了高质量的PoC测试用例。通过动态执行和LLM裁判相结合的评估方法,能够更准确地评估LLM的代码安全能力。Pass@K评分协议能够对LLM在不同场景和难度下的表现进行综合评估,并进行跨模型的比较。
🎯 应用场景
SecCodeBench-V2可用于评估和改进LLM代码生成工具的安全性,帮助开发者构建更安全可靠的软件系统。该基准还可以促进安全代码生成技术的研究,推动AI在软件安全领域的应用。未来,可以基于SecCodeBench-V2开发自动化漏洞检测和修复工具,提高软件开发的效率和安全性。
📄 摘要(原文)
We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.