Benchmarking at the Edge of Comprehension
作者: Samuele Marro, Jialin Yu, Emanuele La Malfa, Oishi Deb, Jiawei Li, Yibo Yang, Ebey Abraham, Sunando Sengupta, Eric Sommerlade, Michael Wooldridge, Philip Torr
分类: cs.AI, cs.LG
发布日期: 2026-02-15 (更新: 2026-02-19)
💡 一句话要点
提出抗批判基准测试框架,解决大模型超越人类理解能力后的评测难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准测试 对抗学习 人类验证 抗批判正确性
📋 核心要点
- 现有基准测试方法在大模型能力超越人类理解后,难以生成区分性任务和提供准确的ground-truth。
- 提出抗批判基准测试,通过人类作为有界验证者,关注局部声明的验证,保持评估的完整性。
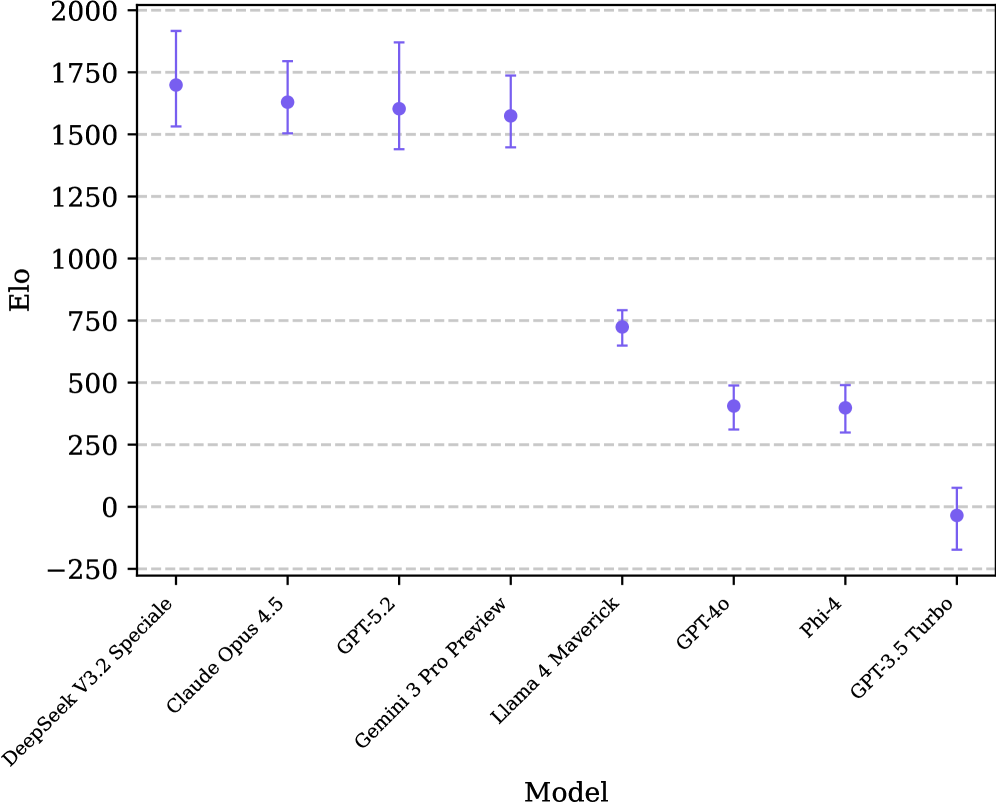
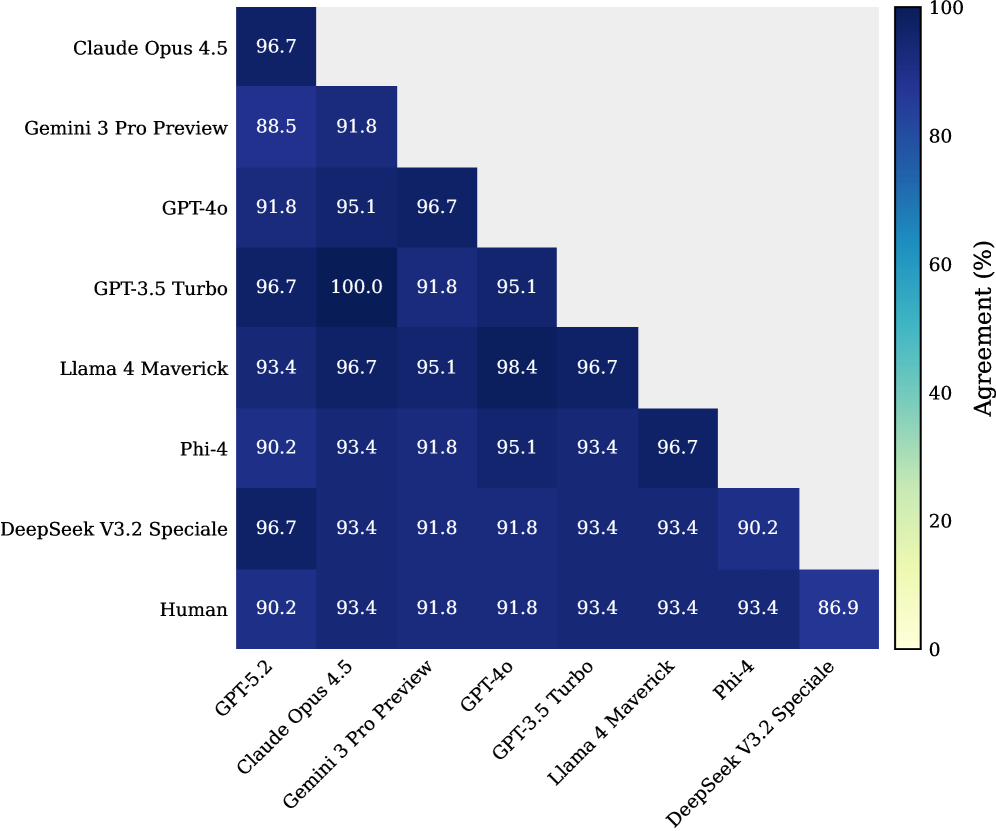
- 在数学领域对八个前沿LLM进行实验,结果表明该方法得到的分数稳定,并与外部能力度量相关。
📝 摘要(中文)
随着前沿大型语言模型(LLMs)在发布后不久就迅速饱和新的基准测试,基准测试本身正处于一个关键时刻:如果前沿模型不断改进,人类将越来越难以生成具有区分性的任务、提供准确的ground-truth答案或评估复杂的解决方案。如果基准测试变得不可行,我们衡量人工智能任何进展的能力将受到威胁。我们将这种情况称为后理解状态。在这项工作中,我们提出了一种抗批判基准测试(Critique-Resilient Benchmarking)的对抗框架,旨在比较模型,即使完全的人类理解是不可行的。我们的技术依赖于抗批判正确性的概念:如果没有任何对手令人信服地证明答案是错误的,则该答案被认为是正确的。与标准基准测试不同,人类充当有界验证者,并专注于局部声明,这在超越对任务的完全理解的情况下保持了评估的完整性。使用项目化的二分Bradley-Terry模型,我们共同对LLM进行排名,根据它们解决具有挑战性的任务和生成困难但可解决的问题的能力。我们展示了我们的方法在数学领域中对八个前沿LLM的有效性,表明结果分数是稳定的并且与外部能力度量相关。我们的框架将基准测试重新定义为人类充当最终仲裁者的对抗生成-评估游戏。
🔬 方法详解
问题定义:论文旨在解决当大型语言模型(LLMs)的能力超越人类理解范围时,如何有效地进行基准测试的问题。传统的基准测试依赖于人类专家来创建任务、提供标准答案并评估模型的性能。然而,当模型能够解决人类无法完全理解的复杂问题时,这些方法就变得不可靠。现有方法的痛点在于,人类难以生成具有区分度的任务,也难以判断复杂答案的正确性,从而导致基准测试失去意义。
核心思路:论文的核心思路是将基准测试过程转化为一个对抗性的生成-评估游戏。在这个游戏中,模型不仅需要解决问题,还需要生成能够挑战其他模型的问题。人类的角色从提供标准答案转变为验证者,他们不再需要完全理解整个问题的解决方案,而是只需要验证答案的局部正确性。这种“抗批判正确性”的概念允许在人类无法完全理解任务的情况下进行有效的模型比较。
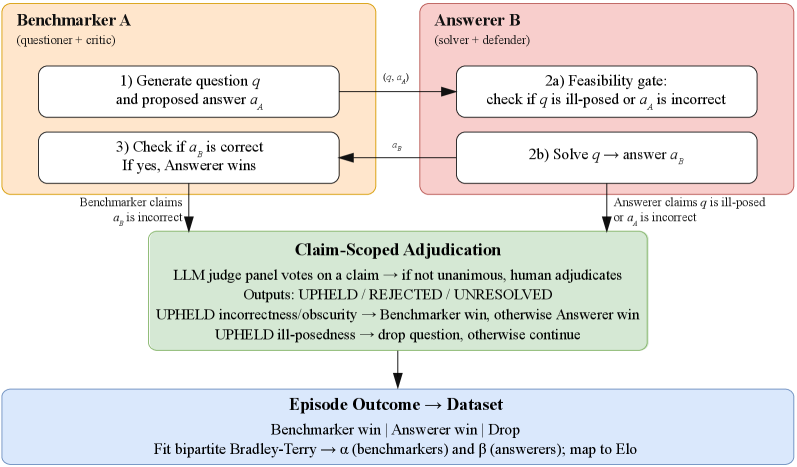
技术框架:该框架包含以下几个主要组成部分:1) 问题生成器:负责生成具有挑战性的问题。2) 解题器:负责解决生成的问题。3) 批判者:负责对解题器的答案进行批判,尝试找出错误。4) 验证者(人类):负责验证批判者的批判是否有效。整体流程是一个迭代的过程,问题生成器生成问题,解题器尝试解决,批判者尝试找出错误,最后由人类验证者进行仲裁。通过多次迭代,可以更准确地评估模型的真实能力。
关键创新:最重要的技术创新点在于引入了“抗批判正确性”的概念,以及将基准测试过程转化为对抗性的生成-评估游戏。与传统的基准测试方法相比,该方法不再依赖于人类对问题的完全理解,而是通过人类对局部声明的验证来评估模型的性能。这种方法更适用于评估能力超越人类理解范围的模型。
关键设计:论文使用了一个项目化的二分Bradley-Terry模型来对LLM进行排名。该模型同时考虑了模型解决问题的能力和生成问题的能力。模型的排名是基于模型在对抗游戏中的胜率来确定的。此外,论文还设计了一系列的实验来验证该方法的有效性,并证明了该方法得到的分数是稳定的并且与外部能力度量相关。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在数学领域对八个前沿LLM进行评估时,得到的分数是稳定的,并且与外部能力度量相关。这表明该方法能够有效地评估模型在复杂任务上的性能,即使人类无法完全理解这些任务的解决方案。该框架为解决大模型评测难题提供了一种新思路。
🎯 应用场景
该研究成果可应用于评估和比较各种大型语言模型,尤其是在模型能力超越人类理解范围的复杂领域,如数学、科学研究和复杂推理。它有助于推动人工智能的进步,并为未来的模型开发提供更可靠的评估标准。该框架还可用于自动化测试和验证,提高AI系统的可靠性。
📄 摘要(原文)
As frontier Large Language Models (LLMs) increasingly saturate new benchmarks shortly after they are published, benchmarking itself is at a juncture: if frontier models keep improving, it will become increasingly hard for humans to generate discriminative tasks, provide accurate ground-truth answers, or evaluate complex solutions. If benchmarking becomes infeasible, our ability to measure any progress in AI is at stake. We refer to this scenario as the post-comprehension regime. In this work, we propose Critique-Resilient Benchmarking, an adversarial framework designed to compare models even when full human understanding is infeasible. Our technique relies on the notion of critique-resilient correctness: an answer is deemed correct if no adversary has convincingly proved otherwise. Unlike standard benchmarking, humans serve as bounded verifiers and focus on localized claims, which preserves evaluation integrity beyond full comprehension of the task. Using an itemized bipartite Bradley-Terry model, we jointly rank LLMs by their ability to solve challenging tasks and to generate difficult yet solvable questions. We showcase the effectiveness of our method in the mathematical domain across eight frontier LLMs, showing that the resulting scores are stable and correlate with external capability measures. Our framework reformulates benchmarking as an adversarial generation-evaluation game in which humans serve as final adjudicators.