FMMD: A multimodal open peer review dataset based on F1000Research
作者: Zhenzhen Zhuang, Yuqing Fu, Jing Zhu, Zhangping Zhou, Jialiang Lin
分类: cs.DL, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-15
备注: Work in progress
💡 一句话要点
FMMD:一个基于F1000Research的多模态开放同行评审数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 同行评审 多模态数据 开放数据集 自动评审 版本控制 自然语言处理 计算机视觉
📋 核心要点
- 现有同行评审数据集主要集中于文本,忽略了图表等视觉信息,限制了多模态评审研究。
- FMMD数据集整合了手稿的视觉和结构数据,以及版本特定的评审报告和编辑决策。
- FMMD通过显式对齐评审意见和对应版本,支持对同行评审生命周期的细粒度分析,促进相关研究。
📝 摘要(中文)
自动化学术论文评审(ASPR)已进入与传统同行评审共存的阶段,人工智能(AI)系统越来越多地被纳入实际的手稿评估中。与此同时,关于自动和AI辅助同行评审的研究也大量涌现。尽管有这样的势头,但由于现有数据集中的几个关键限制,实证进展仍然受到限制。虽然审稿人通常会评估图表和复杂的布局来评估科学主张,但大多数现有数据集仍然以文本为中心。这种偏差因对计算机科学场所数据的狭隘关注而得到加强。此外,这些数据集缺乏审稿人评论和特定手稿版本之间的精确对齐,模糊了同行评审和手稿演变之间的迭代关系。作为回应,我们推出了FMMD,这是一个从F1000Research策划的多模态和多学科开放同行评审数据集。该数据集通过将手稿级别的视觉和结构数据与特定版本的审稿报告和编辑决策相结合,弥合了当前的差距。通过提供审稿人评论与正在审查的确切文章迭代之间的显式对齐,FMMD能够对跨不同科学领域的同行评审生命周期进行细粒度分析。FMMD支持多模态问题检测和多模态评论生成等任务。它为同行评审研究的发展提供了全面的经验资源。
🔬 方法详解
问题定义:现有自动同行评审数据集主要以文本为中心,忽略了手稿中的视觉和结构信息,无法充分模拟真实的评审过程。此外,现有数据集缺乏审稿意见与手稿版本的精确对应关系,难以追踪评审过程中的迭代演变。这些限制阻碍了多模态自动评审和评审过程分析的研究进展。
核心思路:FMMD数据集的核心思路是构建一个多模态、多学科的开放同行评审数据集,该数据集包含手稿的视觉和结构信息,以及版本特定的审稿报告和编辑决策。通过显式地将审稿意见与对应的手稿版本对齐,FMMD旨在提供一个更全面、更细粒度的同行评审数据资源,从而支持更深入的自动评审研究。
技术框架:FMMD数据集的构建主要包括以下几个阶段:1) 数据收集:从F1000Research平台收集手稿及其对应的审稿报告、编辑决策等信息。2) 数据处理:提取手稿的文本、图像、表格等信息,并进行结构化处理。3) 数据对齐:将审稿意见与对应的手稿版本进行精确对齐,建立审稿意见与手稿内容之间的关联。4) 数据发布:将处理后的数据以开放的形式发布,供研究人员使用。
关键创新:FMMD数据集的关键创新在于其多模态性和版本对齐。与以往的文本中心数据集不同,FMMD包含了手稿的视觉和结构信息,更贴近真实的评审场景。同时,FMMD通过精确的版本对齐,使得研究人员可以追踪评审过程中的迭代演变,从而进行更深入的分析。
关键设计:FMMD数据集的关键设计包括:1) 多模态数据表示:采用多种方式表示手稿的视觉和结构信息,例如图像特征、表格结构等。2) 版本对齐策略:设计有效的算法,将审稿意见与对应的手稿版本进行精确对齐。3) 数据质量控制:对数据进行清洗和标注,确保数据的质量和可靠性。
🖼️ 关键图片
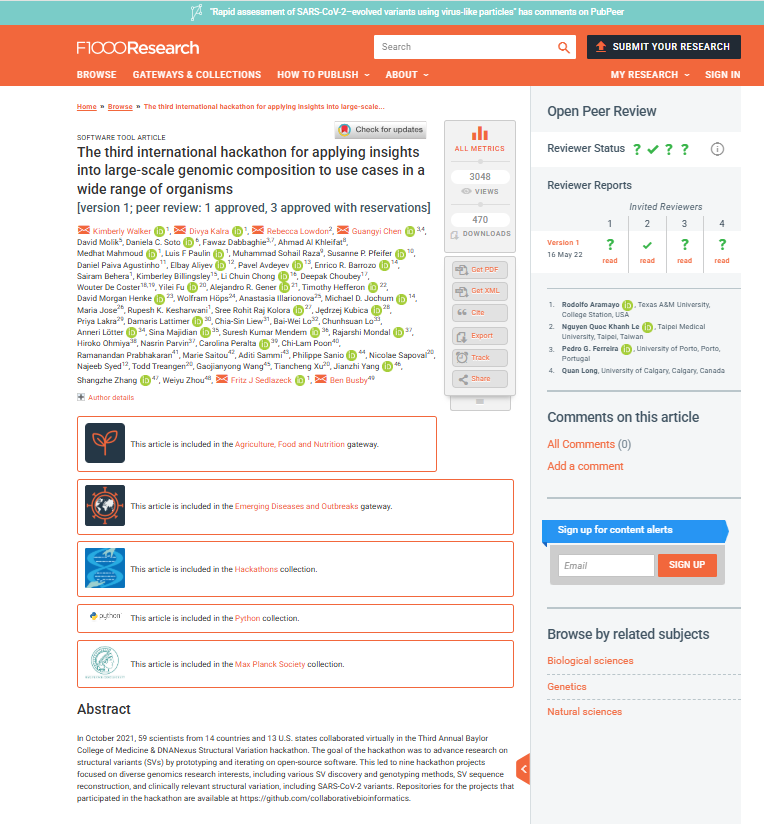
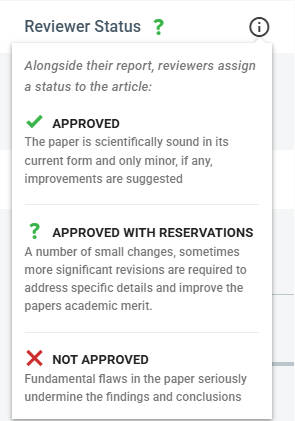
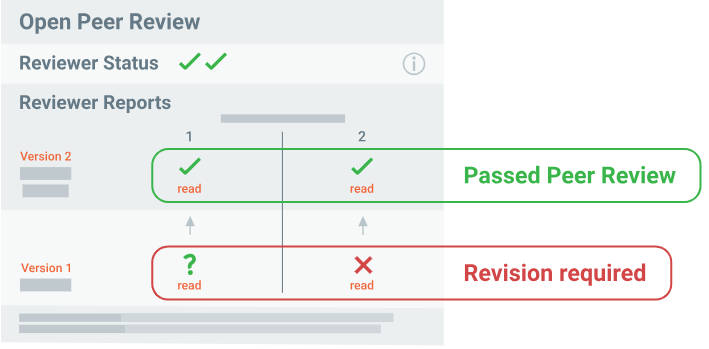
📊 实验亮点
FMMD数据集是首个多模态开放同行评审数据集,包含手稿的视觉和结构信息,以及版本特定的审稿报告和编辑决策。通过提供审稿人评论与正在审查的确切文章迭代之间的显式对齐,FMMD能够对跨不同科学领域的同行评审生命周期进行细粒度分析。该数据集支持多模态问题检测和多模态评论生成等任务。
🎯 应用场景
FMMD数据集可应用于多种场景,包括自动评审意见生成、评审质量评估、评审过程分析等。该数据集能够促进多模态自动评审技术的发展,提高评审效率和质量。此外,FMMD还可以用于研究评审过程中的偏见和公平性问题,为改进评审机制提供依据。未来,FMMD有望成为自动评审研究的重要基准数据集。
📄 摘要(原文)
Automated scholarly paper review (ASPR) has entered the coexistence phase with traditional peer review, where artificial intelligence (AI) systems are increasingly incorporated into real-world manuscript evaluation. In parallel, research on automated and AI-assisted peer review has proliferated. Despite this momentum, empirical progress remains constrained by several critical limitations in existing datasets. While reviewers routinely evaluate figures, tables, and complex layouts to assess scientific claims, most existing datasets remain overwhelmingly text-centric. This bias is reinforced by a narrow focus on data from computer science venues. Furthermore, these datasets lack precise alignment between reviewer comments and specific manuscript versions, obscuring the iterative relationship between peer review and manuscript evolution. In response, we introduce FMMD, a multimodal and multidisciplinary open peer review dataset curated from F1000Research. The dataset bridges the current gap by integrating manuscript-level visual and structural data with version-specific reviewer reports and editorial decisions. By providing explicit alignment between reviewer comments and the exact article iteration under review, FMMD enables fine-grained analysis of the peer review lifecycle across diverse scientific domains. FMMD supports tasks such as multimodal issue detection and multimodal review comment generation. It provides a comprehensive empirical resource for the development of peer review research.