TabTracer: Monte Carlo Tree Search for Complex Table Reasoning with Large Language Models
作者: Zhizhao Luo, Zhaojing Luo, Meihui Zhang, Rui Mao
分类: cs.DB, cs.AI
发布日期: 2026-02-15
💡 一句话要点
TabTracer:基于蒙特卡洛树搜索的LLM复杂表格推理框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格推理 大型语言模型 蒙特卡洛树搜索 状态跟踪 回滚机制
📋 核心要点
- 现有表格推理方法缺乏有效的步骤级验证和回溯机制,容易导致错误累积和幻觉问题。
- TabTracer通过蒙特卡洛树搜索维护表格状态的搜索树,并利用反馈进行状态验证和回滚,提升推理可靠性。
- 实验表明,TabTracer在多个数据集上显著提升了准确率,并大幅降低了token消耗,提高了效率。
📝 摘要(中文)
大型语言模型(LLMs)已成为自然语言表格推理的强大工具,现有方法主要分为两类。基于Prompt的方法依赖于纯语言推理或单次程序生成,缺乏步骤级别的验证。基于Agent的方法在闭环中使用工具,但验证通常是局部的,回溯有限,导致错误传播并增加成本。此外,它们依赖于链式或束式轨迹,通常存在组合冗余,导致高昂的token成本。本文提出了TabTracer,一个agent框架,协调中间表格状态上的多步骤工具调用,并进行显式状态跟踪以进行验证和回滚。首先,它通过类型化操作和轻量级的数值和格式检查来强制执行步骤级别的验证,以提供可靠的奖励并抑制幻觉。其次,执行反馈蒙特卡洛树搜索维护候选表格状态的搜索树,并使用反向传播的反射分数来指导UCB1选择,并通过版本化快照进行回滚。第三,它通过预算感知修剪、去重和具有单调性门的状态哈希来减少冗余,从而降低token成本。在TabFact、WikiTQ和CRT数据集上的综合评估表明,TabTracer的准确率比最先进的基线高出6.7%,同时token消耗降低了59-84%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂表格推理任务中,由于缺乏有效的步骤级验证和回溯机制,导致的错误累积、幻觉问题以及高昂的token消耗问题。现有方法,如prompt-based和agent-based方法,在处理复杂推理时存在局限性,无法保证推理的准确性和效率。
核心思路:TabTracer的核心思路是引入蒙特卡洛树搜索(MCTS)来探索和验证不同的推理路径,通过显式的状态跟踪和回滚机制,纠正推理过程中的错误。同时,通过预算感知的剪枝、去重和状态哈希等技术,降低token消耗,提高推理效率。
技术框架:TabTracer框架主要包含以下几个模块:1) 状态表示:使用表格状态的快照来记录推理过程中的中间结果。2) 动作空间:定义了一系列类型化的操作,用于对表格状态进行转换。3) 奖励函数:基于步骤级别的验证结果,为每个动作提供奖励,抑制幻觉。4) 蒙特卡洛树搜索:维护一个搜索树,每个节点代表一个表格状态,边代表一个动作。MCTS通过选择、扩展、模拟和反向传播等步骤,探索最优的推理路径。5) 剪枝和去重:通过预算感知的剪枝、去重和状态哈希等技术,减少搜索空间,降低token消耗。
关键创新:TabTracer的关键创新在于将蒙特卡洛树搜索引入到表格推理任务中,并结合显式的状态跟踪和回滚机制,实现了更可靠和高效的推理。与现有方法相比,TabTracer能够更好地探索和验证不同的推理路径,纠正推理过程中的错误,并降低token消耗。
关键设计:TabTracer的关键设计包括:1) 类型化操作:定义了一系列类型化的操作,用于对表格状态进行转换,并进行类型检查,减少错误。2) 轻量级验证:使用轻量级的数值和格式检查来验证每个步骤的结果,提供可靠的奖励。3) UCB1选择:使用UCB1算法来选择下一个要探索的节点,平衡探索和利用。4) 单调性门:使用单调性门来判断状态是否重复,避免重复计算。
🖼️ 关键图片
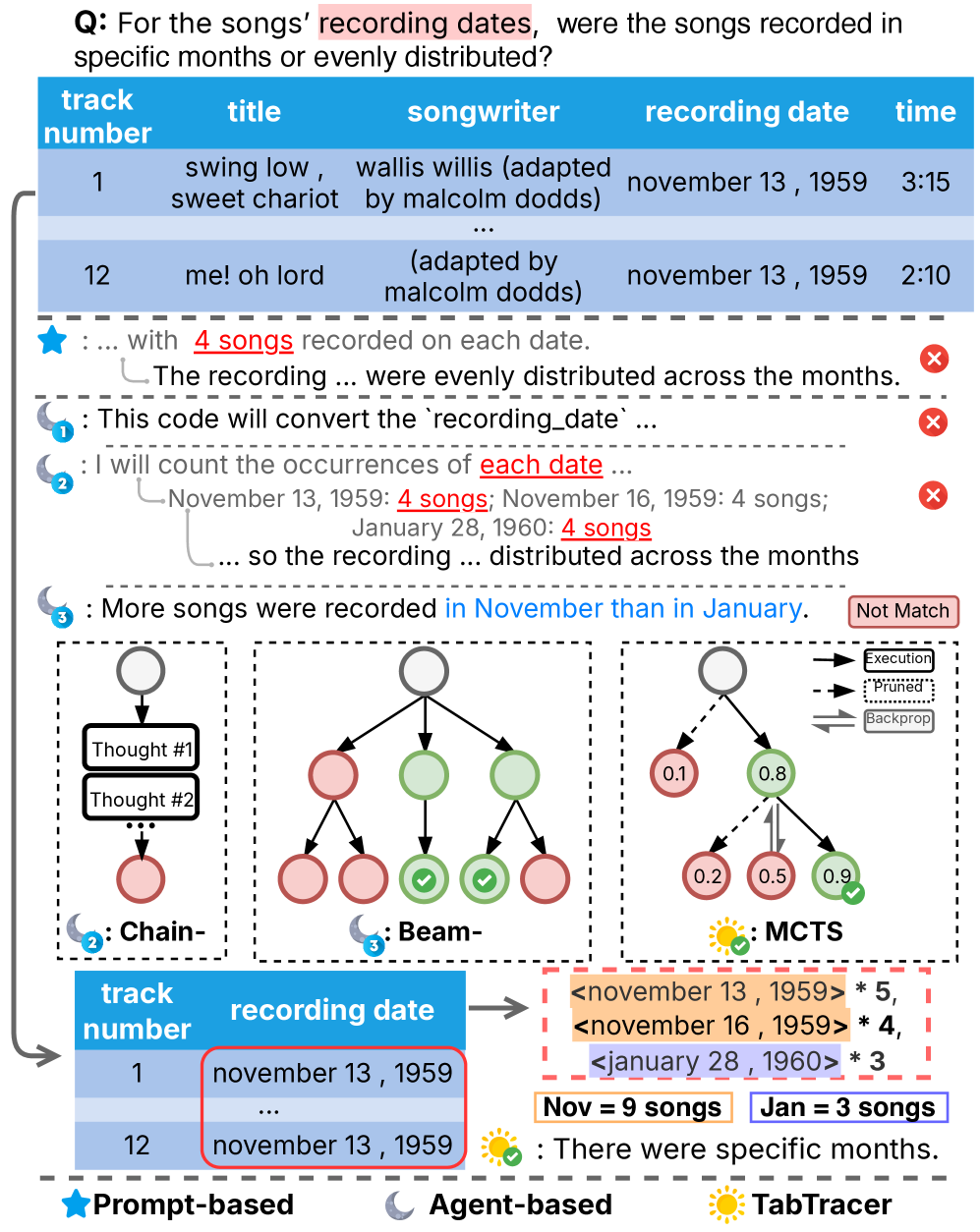
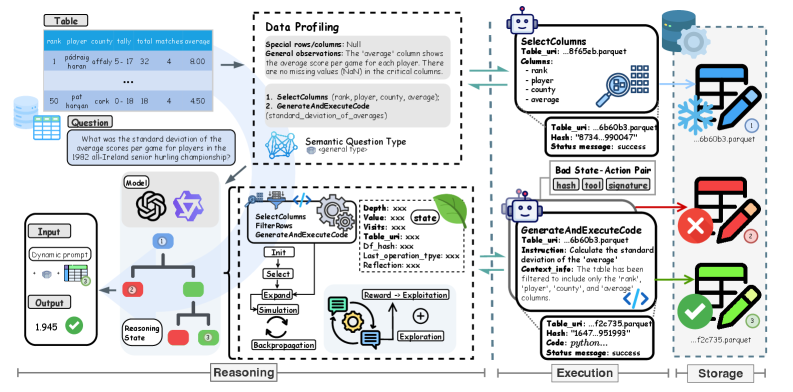
📊 实验亮点
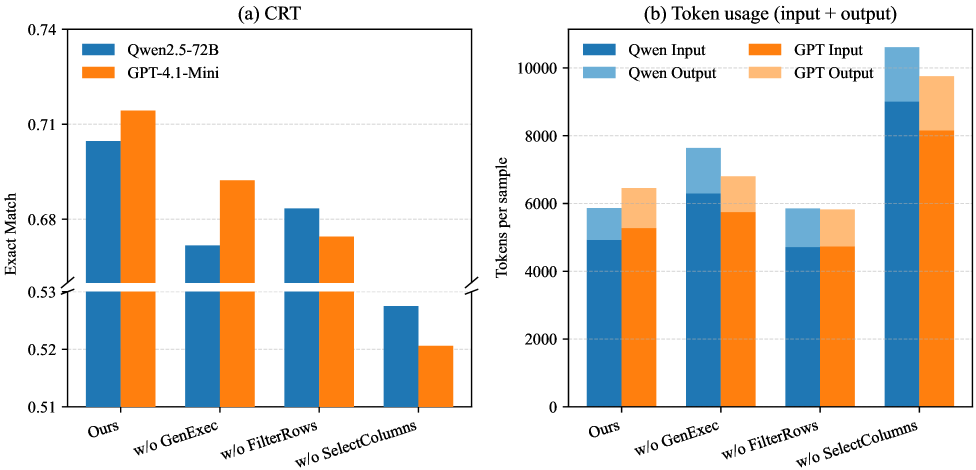
TabTracer在TabFact、WikiTQ和CRT数据集上进行了评估,结果表明,TabTracer的准确率比最先进的基线高出6.7%,同时token消耗降低了59-84%。例如,在TabFact数据集上,TabTracer取得了显著的性能提升,证明了其在复杂表格推理任务中的有效性。
🎯 应用场景
TabTracer可应用于金融分析、市场调研、科学研究等领域,帮助用户从表格数据中提取有价值的信息,辅助决策。该研究的实际价值在于提高了表格推理的准确性和效率,降低了计算成本。未来,TabTracer有望扩展到更复杂的表格推理任务,并与其他自然语言处理技术相结合,实现更智能的数据分析。
📄 摘要(原文)
Large language models (LLMs) have emerged as powerful tools for natural language table reasoning, where there are two main categories of methods. Prompt-based approaches rely on language-only inference or one-pass program generation without step-level verification. Agent-based approaches use tools in a closed loop, but verification is often local and backtracking is limited, allowing errors to propagate and increasing cost. Moreover, they rely on chain- or beam-style trajectories that are typically combinatorially redundant, leading to high token costs. In this paper, we propose TabTracer, an agentic framework that coordinates multi-step tool calls over intermediate table states, with explicit state tracking for verification and rollback. First, it enforces step-level verification with typed operations and lightweight numeric and format checks to provide reliable rewards and suppress hallucinations. Second, execution-feedback Monte Carlo Tree Search maintains a search tree of candidate table states and uses backpropagated reflection scores to guide UCB1 selection and rollback via versioned snapshots. Third, it reduces redundancy with budget-aware pruning, deduplication, and state hashing with a monotonicity gate to cut token cost. Comprehensive evaluation on TabFact, WikiTQ, and CRT datasets shows that TabTracer outperforms state-of-the-art baselines by up to 6.7% in accuracy while reducing token consumption by 59--84%.